第7章 分布式数据库
关系数据库理论汇集了计算机科学家几十年的智慧,Oracle、Microsoft SQL Server、MySQL等关系数据库系统广泛应用在各行各业中。可以说,没有关系数据库,就没有今天的IT或者互联网行业。然而,关系数据库设计之初并没有预见到IT行业发展如此之快,总是假设系统运行在单机这一封闭系统上。
有很多思路可以实现关系数据库的可扩展性。例如,在应用层划分数据,将不同的数据分片划分到不同的关系数据库上,如MySQL Sharding;或者在关系数据库内部支持数据自动分片,如Microsoft SQL Azure;或者干脆从存储引擎开始重写一个全新的分布式数据库,如Google Spanner以及Alibaba OceanBase。
本章首先介绍数据库中间层架构,接着介绍Microsoft SQL Azure,最后介绍Google Spanner。
7.1 数据库中间层
为了扩展关系数据库,最简单也是最为常见的做法就是应用层按照规则将数据拆分为多个分片,分布到多个数据库节点,并引入一个中间层来对应用屏蔽后端的数据库拆分细节。
7.1.1 架构
以MySQL Sharding架构为例,分为几个部分:中间层dbproxy集群、数据库组、元数据服务器、常驻进程,如图7-1所示。
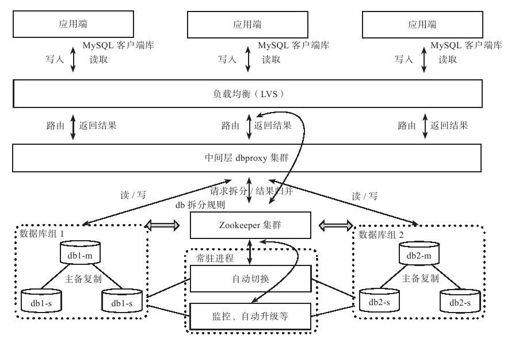
图 7-1 数据库中间层架构
(1)MySQL客户端库
应用程序通过MySQL原生的客户端与系统交互,支持JDBC,原有的单机访问数据库程序可以无缝迁移。
(2)中间层dbproxy
中间层解析客户端SQL请求并转发到后端的数据库。具体来讲,它解析MySQL协议,执行SQL路由,SQL过滤,读写分离,结果归并,排序以及分组,等等。中间层由多个无状态的dbproxy进程组成,不存在单点的情况。另外,可以在客户端与中间层之间引入LVS(Linux Virtual Server)对客户端请求进行负载均衡。需要注意的是,引入LVS后,客户端请求需要额外增加一层通信开销,因此,常见的做法是直接在客户端配置中间层服务器列表,由客户端处理请求负载均衡以及中间层服务器故障等情况。
(3)数据库组dbgroup
每个dbgroup由N台数据库机器组成,其中一台为主机(Master),另外N-1台为备机(Slave)。主机负责所有的写事务及强一致读事务,并将操作以binlog的形式复制到备机,备机可以支持有一定延迟的读事务。
(4)元数据服务器
元数据服务器主要负责维护dbgroup拆分规则并用于dbgroup选主。dbproxy通过元数据服务器获取拆分规则从而确定SQL语句的执行计划。另外,如果dbgroup的主机出现故障,需要通过元数据服务器选主。元数据服务器本身也需要多个副本实现HA,一种常见的方式是采用Zookeeper实现。
(5)常驻进程agents
部署在每台数据库服务器上的常驻进程,用于实现监控,单点切换,安装,卸载程序等。dbgroup中的数据库需要进行主备切换,软件升级等,这些控制逻辑需要与数据库读写事务处理逻辑隔离开来。
假设数据库按照用户哈希分区,同一个用户的数据分布在一个数据库组上。如果SQL请求只涉及同一个用户(这对于大多数应用都是成立的),那么,中间层将请求转发给相应的数据库组,等待返回结果并将结果返回给客户端;如果SQL请求涉及多个用户,那么中间层需要转发给多个数据库组,等待返回结果并将结果执行合并、分组、排序等操作后返回客户端。由于中间层的协议与MySQL兼容,客户端完全感受不到与访问单台MySQL机器之间的差别。
