13.3 MapReduce扩展
MapReduce框架有效地解决了海量数据的离线批处理问题,在各大互联网公司得到广泛的应用。事实已经证明了MapReduce巨大的影响力,以至于引发了一系列的扩展和改进。这些扩展包括:
●Google Tenzing:基于MapReduce模型构建SQL执行引擎,使得数据分析人员可以直接通过SQL语言处理大数据。
●Microsoft Dryad:将MapReduce模型从一个简单的两步工作流扩展为任何函数集的组合,并通过一个有向无环图来表示函数之间的工作流。
●Google Pregel:用于图模型迭代计算,这种场景下Pregel的性能远远好于 MapReduce。
13.3.1 Google Tenzing
Google Tenzing是一个构建在MapReduce之上的SQL执行引擎,支持SQL查询且能够扩展到成千上万台机器,极大地方便了数据分析人员。
1.整体架构
Tenzing系统有四个主要组件:分布式Worker池、查询服务器、客户端接口和元数据服务器,如图13-2所示。
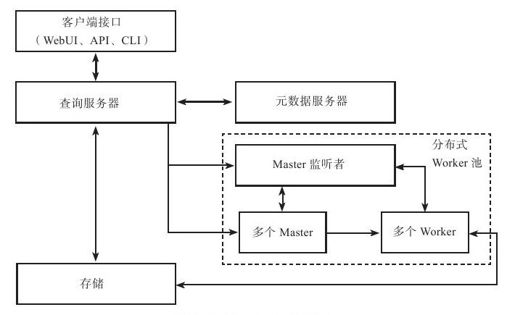
图 13-2 Tenzing整体架构
●查询服务器(Query Server):作为连接客户端和worker池的中间桥梁而存在。查询服务器会解析客户端发送的查询请求,进行SQL优化,然后将执行计划发送给分布式Worker池执行。Tenzing支持基于规则(rule-based optimizer)以及基于开销(cost-based optimizer)两种优化模式。
●分布式Worker池:作为执行系统,它会根据查询服务器生成的执行计划运行MapReduce任务。为了降低查询延时,Tenzing不是每次都重新生成新进程,而是让进程一直处于运行状态。Worker池包含master和worker两种节点,其中,master对应MapReduce框架中的master进程,worker对应MapReduce框架中的map和reduce进程。另外,还有一个称为master监听者(master watcher)的守护进程,查询服务器通过master监听者获取master信息。
●元数据服务器(Metadata Server):存储和获取表格schema、访问控制列表(Access Control List,ACL)等全局元数据。元数据服务器使用Bigtable作为持久化的后台存储。
●客户端接口:Tenzing提供三类客户端接口,包括API、命令行客户端(CLI)以及Web UI。
●存储(Storage):分布式worker池中的master和worker进程执行MapReduce任务时需要读写存储服务。另外,查询服务器会从存储服务获取执行结果。
2.查询流程
1)用户通过Web UI、CLI或者API向查询服务器提交查询。
2)查询服务器将查询请求解析为一个中间语法树。
3)查询服务器从元数据服务器获取相应的元数据,然后创建一个更加完整的中间格式。
4)优化器扫描该中间格式进行各种优化,生成物理查询计划。
5)优化后的物理查询计划由一个或多个MapReduce作业组成。对于每个MapReduce作业,查询服务器通过master监听者找到一个可用的master,master将该作业划分为多个任务。
6)空闲的worker从master拉取已就绪的任务。Reduce进程会将它们的结果写入到一个中间存储区域中。
7)查询服务器监控这些中间存储区域,收集中间结果,并流失地返回给客户端。
3.SQL运算符映射到MapReduce
查询服务器负责将用户的SQL操作转化为MapReduce作业,本节介绍各个SQL物理运算符对应的MapReduce实现。
(1)选择和投影
选择运算符σC(R)的一种MapReduce实现如下。
Map函数:对R中的每个元素t,检测它是否满足条件C。如果满足,则产生一个“键-值”对(t,t)。也就是说,键和值都是t。
Reduce函数:Reduce的作用类似于恒等式,它仅仅将每个“键-值”对传递到输出部分。
投影运算的处理和选择运算类似,不同的是,投影运算可能会产生多个相同的元组,因此Reduce函数必须要剔除冗余元组。可以采用如下方式实现投影运算符πS(R)。
Map函数:对R中的每个元组t,通过剔除属性不在S中的字段得到元组t',输出一个“键-值”对(t',t')。
Reduce函数:对任意Map任务产生的每个键t',将存在一个或多个“键-值”对(t',t'),Reduce函数将(t',[t',t',…,t'])转换为(t',t'),以保证对该键t'只产生一个(t',t')对。
Tenzing执行时会做一些优化,例如选择运算符下移到存储层;如果存储层支持列式存储,Tenzing只扫描那些查询执行必须的列。
(2)分组和聚合
假定对关系R(A,B,C)按照字段A分组,并计算每个分组中所有元组的字段B之和。可以采用如下方式实现γA,SUM(B)(R)。
Map函数:对于每个元组,生成“键-值”对(a,b)。
Reduce函数:每个键a代表一个分组,对与键a相关的字段B的值的列表[b1,b2,…,bn]执行SUM操作,输出结果为(a,SUM(b1,b2,…,bn))。
Tenzing支持基于哈希的聚合操作,首先,放松底层MapReduce框架的限制,shuffle时保证所有键相同的“键-值”对属于同一个Reduce任务,但是并不要求按照键有序排列。其次,Reduce函数采用基于哈希的方法对数据分组并计算聚合结果。
(3)多表连接
大表连接是分布式数据库的难题,MapReduce模型能够有效地解决这一类问题。常见的连接算法包括Sort Merge Join、Hash Join以及Nested Loop Join。
假设需要将R(A,B)和S(B,C)进行自然连接运算,即寻找字段B相同的元组。可以通过Sort Merge Join实现如下:
Map函数:对于R中的每个元组(a,b),生成“键-值”对(b,(R,a)),对S中的每个元组(b,c),生成“键-值”对(b,(S,c))。
Reduce函数:每个键值b会与一系列对相关联,这些对要么来自(R,a),要么来自(S,c)。键b对应的输出结果是(b,[(a1,b,c1),(a2,b,c2),…]),也就是说,与b相关联的元组列表由来自R和S中的具有共同b值的元组组合而成。
如果两张表格都很大,且二者的大小比较接近,Join字段也没有索引,Sort Merge Join往往比较高效。然而,如果一张表格相比另外一张表格要大很多,Hash Join往往更加合适。
假设R(A,B)比S(B,C)大很多,可以通过Hash Join实现自然连接。Tenzing中一次Hash Join需要执行三个MapReduce任务。
MR1:将R(A,B)按照字段B划分为N个哈希分区,记为R1,R2,…,RN;
MR2:将S(B,C)按照字段B划分为N个哈希分区,记为S1,S2,…,Sn;
MR3:每个哈希分区<Ri,Si>对应一个Map任务,这个Map任务会将Si加载到内存中。对于Ri中的每个元组(a,b),生成(b,[(a,b,c1),(a,b,c2),…]),其中,(b,[c1,c2,…])是Si中存储的元组。Reduce的作用类似于恒等式,输出每个传入的“键-值”对。
Sort Merge Join和Hash Join适用于两张表格都不能够存放到内存中,且连接列没有索引的场景。如果S(B,C)在B列有索引,可以通过Remote Lookup Join实现自然连接,如下:
Map函数:对于R中的每个元组(a,b),通过索引查询S(B,C)中所有列值为b的元组,生成(b,[(a,b,c1),(a,b,c2),…])。
Reduce函数:Reduce的作用类似于恒等式,输出每个传入的“键-值”对。
如果S(B,C)能够存放到内存中,那么,Map进程在执行map任务的过程中会将S(B,C)的所有元组缓存在本地,进一步优化执行效率。另外,同一个Map进程可能执行多个map任务,这些map任务共享一份S(B,C)的所有元组缓存。
