更新数据
用户和Web站点的交互操作会导致数据库的不断更新。因此,我们要解决的首要挑战是为每个更新提供良好的性能和操作一致性的前提下,如何支持大量的更新操作。
面临挑战
假设我们要构建一个社交网络站点,系统中的每个用户都有一条用户信息记录,该记录包含用户名、爱好等。用户Alice可能在全世界都有朋友,她的朋友想看她的个人信息,这些读取请求操作有严格的低延迟要求。为此,系统必须保证Alice的用户信息记录(其他人的也类似)在全球都有副本,这样她的朋友们就可以访问该记录的本地副本。现在,社交网络的一个特征是用户可以通过自由的文本定制来更新自己的状态。比如,Alice可能想修改她的状态为“忙碌,电话中”(Bsy on the phone),过后又修改为“有空,要聊天吗?”(Of the phone,anybody wanna chat?)。当Alice更改她的状态时,系统需要把这些更改操作写入数据库中她的用户信息记录,这样她的朋友们才可以看到。用户信息记录表见表4-1。注意,为了支持Web应用的不断升级,必须提供一个灵活的数据库模式和松散耦合的数据组织方式,而不是每条记录的每个字段都有相应值,并且增加新的字段代价必须小。
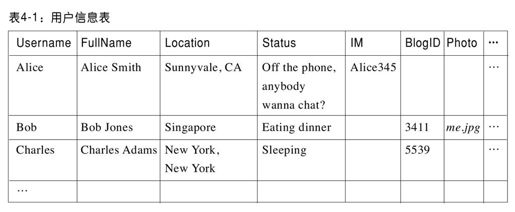
我们该如何更新Alice的用户信息记录?从标准数据库角度看,为了实现该更新操作的原子性,我们需要执行以下步骤:打开一个事务;对所有的副本执行写操作;向所有的副本发送提交信息并关闭该事务。这种方法和标准数据库的ACID[1]模式一致,保证所有的副本都能够正确地更新到新状态。即使是非ACID模式的数据库,如G公司的BigTable(Chang等2006),采用了类似的方法来同步更新数据的所有副本。但是,当存在地理空间上的数据复制时,该方法效率很低。当Alice输入她的状态信息并点击“OK”,由于需要等待分散在各地的数据中心提交该事务,她可能需要等待很长时间才能加载响应页面。此外,为了保证原子性,在事务处理过程中,系统需要对Alice的状态加排他锁,这意味着其他用户可能长时间无法看到Alice的状态。
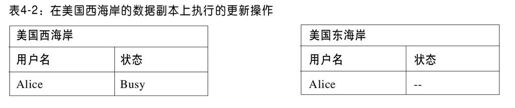
由于当地理空间上存在不同副本时,原子事务的代价很高,很多Web数据库采用了“尽最大努力”的方式(bst-effort approach):先将更新写到一份数据中,然后异步地将更新操作传播(popagate)到其他的副本。模拟事务操作时,不执行加锁及验证。这种方法,犹如其名——“尽最大努力”,存在很多困难。即使系统能够保证在所有的副本上执行更新,也不能保证数据库的不同副本最终都保持一致性。比如,Alice首先将她的状态更新为“Busy”,这样在美国西海岸(wst coast)的数据中心需要执行写操作,如表4-2所示。
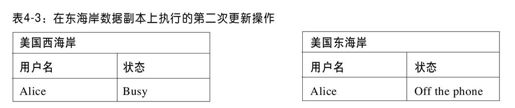
然后,Alice把她的状态更新为“Off the phone”,但由于网络干扰,该更新操作误在美国东海岸(est coast)的数据副本上执行,如表4-3所示。
由于更新传播是异步的,一个可能的事件序列如下:在美国东海岸的数据副本上首先执行“Off the phone”更新操作,然后执行“Busy”更新操作。于是,通过有线传播,更新操作如表4-4所示。
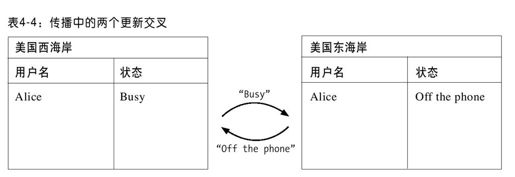
在美国东海岸,“Busy”的状态覆盖了“Off the phone”状态;而在美国西海岸,“Off the phone”状态覆盖了“Busy”状态,这导致如表4-5所示的状态不一致性。
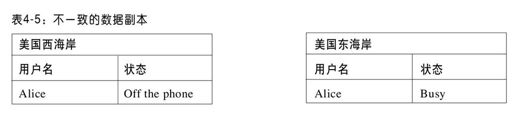
根据读取数据副本的不同,Alice的好友看到的Alice的状态也是不同的,而且该不一致性会一直存在,直到Alice再次改变她的状态。
为了解决上述问题,一些Web规模(wb-scale)的数据存储实现了最终一致性策(eentual consistency),如上述的不正常现象可能暂时发生,数据库最终将会解决该不一致性,并保证所有的数据副本都有相同值。该策略是某些系统的核心,如Amazon的Web服务S3。最终一致性策略通常使用如闲话(gssip)和反熵(ati-entropy)的技术来实现。但是,即使数据库最终会收敛到某个值,也很难预测它最终的收敛结果。因为没有全局时钟来序列化所有的更新操作,数据库难以识别Alice的最终状态更新是“Busy”还是“Off the phone”,因此最后有可能会收敛为“Busy”状态。这样,正当Alice准备和好友聊天,她的所有好友都认为她是忙碌的,且在Alice再次更新她的状态前,这种不正常现象会一直存在。
我们的方法
强一致性策略(如ACID事务)存在扩展上的局限性,弱一致性策略(如尽最大努力策略或最终一致性策略)可能存在不正常现象,我们提出介于二者之间的一种策略,即时间轴一致(tmeline consistency)策略:所有的数据副本将通过相同的时间轴执行更新操作,而且该更新和数据库上执行的更新顺序相同。该时间轴如图4-1所示。因此,数据库将在所有的数据副本上收敛为相同的结果值,且该值是该应用在数据库上执行的最近一次更新操作之后的值。

图 4-1:Alice状态的更新操作时间轴
时间轴一致性是这样实现的:由一台主备份服务器(mster copy,以下简称主备份)执行所有的更新操作,然后将变化异步传播到其他备份服务器来实现的。该主备份序列化所有的更新操作,并确保为每个更新指定一个序列号。即使在更新的异步传播中存在瞬间的故障或误序,该序列号的次序是和需要在所有副本上执行的更新次序一致的。我们选择每条记录一个主备份是因为雅虎的很多应用依赖于同一张数据表,该表中不同的记录对应不同的用户,每个用户都有不同的使用模式(uage patterns)。当然,有可能为主备份性(mstership)选择其他的粒度,比如每个记录分区(如基于关键字)有一个主备份。
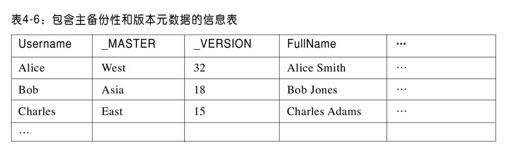
即使是在同一张表,不同记录的主备份也可能分布在不同的服务器上。在以上例子中,Alice住在美国西海岸,并在美国西海岸的数据副本有一条主备份记录;而她的好友Bob住在新加坡,其主备份记录是在亚洲地区的副本。记录的主备份性是作为记录的元数据域(mtadata field)存储在该记录本身,如表4-6所示。
主备份似乎和我们的原则——只应该同步执行代价低的操作不符。如果Alice去纽约旅行,并在那里更新她的状态,由于她的个人信息记录的主备份在美国西海岸,她必须等待系统把她的更新操作提交到美国西海岸;这种高延迟的跨州更新操作正是我们应该尽量避免的。由于用户转变使用模式(如Alice的旅行),这种跨数据中心的写操作确实会偶尔发生,但几率很小。我们分析了对雅虎的用户数据库的更新操作,发现记录更新在包含主备份的数据中心上执行的概率占85%。当然,Alice可能迁移到美国东海岸或者欧洲,由于其记录的主备份仍然在美国西海岸,她执行的写操作就不再是在本地执行的。我们的系统会追踪一条记录更新的源起,为了保证绝大部分的写操作还是在本地执行,系统会根据长期性访问模式(acess pattern)的转变来修改主备份性。(我们将在下一章更详细地讨论主备份性。)
当应用读取一条记录,它通常会读取该记录的本地副本。除非该副本标记为主备份,否则其数据可能已经过期了。该应用可以从时间轴识别其记录实例是和某个版本的记录一致,但是它无法从记录本身识别该记录是否为最新版本。如果该应用要求记录必须是最新版本,系统允许它发送最新读(u-to-date read)请求操作,该请求会被提交到主备份来获取记录的最新备份。执行最新读操作代价很高,而通常情况下读本地副本(可能数据已经过期)的代价很低,这和系统的设计原则也是一致的。幸运的是,Web应用通常对数据时效性要求较低,能够接受过期数据。如果Alice更新了她的状态,但她的好友Bob没有马上看到,而是过后不久看到其新状态,也是可以接受的。
应用可以执行的另一类读操作是“临界读”(citical read),可以保证从用户的角度来讲,数据只随时间向前移动。假设有这样的情况,Alice改变了她的头像(表示一个用户的图片),Bob可能会看Alice的信息页面(导致对数据库的一次读操作),并看到了Alice的新头像。然后,Bob可能会刷新该页面,但由于网络问题,该刷新操作被重定向到没有执行Alice头像更新的副本上执行。结果是Bob将看到的数据比他刚看到的版本更老。为了避免应用程序执行这些操作引起的这种不正常现象,数据库为读操作调用返回记录时会附上该记录的一个版本号。该版本号可以保存在Bob的会话状态(sssion state)或者其浏览器cookie中。当Bob刷新Alice的信息页面时,他上次读到的版本号将和本次请求一同发送,数据库会保证返回记录的版本不会老于该版本。这可能需要把版本号和请求提交给主备份。指定版本号的读操作被称为“临界读”,任何版本号等于指定版本号或者更新的副本,其返回的结果数据都是可以接受的。对于先更新再读取数据库的用户,该技巧尤其有用。以Alice自己为例,当她更新完头像后,如果有任何页面还显示其旧头像,她一定会感到很困惑。因此,当她执行了某个动作需要更新数据库(如更新头像)时,应用程序可以使用“临界读”机制来保证页面都不会显示她的旧数据。
我们也支持“测试并设置”(tst-and-set)操作,该操作使得写操作必须依赖于当前读操作的版本和之前看到的版本(其版本号作为参数传递给“测试并设置”请求)相同。从传统的数据库系统考虑,这是ACID事务的一个特例,它限于单记录,使用的是乐观并发控制策略(otimistic concurrency control)。
主备份性的其他方面
我们采用了各种技术来保证即使在工作负荷变化、失效情况下,都能够低延迟地、平滑地执行读写操作。
举个例子,正如我们之前所述,该系统实现的是记录级(rcord-level)的主备份性。如果一条记录的很多写操作来源于某个数据中心而不是当前的主备份,该记录的主备份性将被及时地转移到该数据中心,且随后的写操作将在该数据中心本地执行。此外,转移主备份性代价很低且系统可以自动执行,因而系统可以快速地适应工作负荷的变化。
系统还实现了即使在存储单元失效的情况下,还能够不间断地执行读写操作的机制。当某个存储单元失效,会(手工或自动)执行对该存储单元的覆盖操作(oerride),并指示另一个数据中心取代失效的存储单元,(为以该存储单元作为主备份的记录)执行写操作。系统会采取措施(细节不在这里赘述),确保根据在失效的存储单元已执行的更新操作执行顺序覆盖操作。这样,当其他的数据中心开始取代失效的存储单元执行更新操作时,还能够保证时间轴一致性。
在PNUTS中,所有读写请求会通过路由层来定位到一条记录相应的数据备份(可能是主备份)。该间接层(lvel of indirection)是提供不间断的系统可用性(uinterrupted system availability)的关键。即使当一个存储单元失效而其数据恢复到另一个存储单元,或者根据使用模式的变化转移记录的主备份,这些变化对于上层应用也是透明的,应用依然可以连接到路由器,享受不间断的系统可用性,其请求可以无缝地路由到适当的数据中心。
支持有序数据
PNUTS系统架构上同时支持散列分区和范围分区的数据。我们称散列版的数据库为YDHT,即雅虎分布式散列表(Yhoo!Distributed Hash Table);称有序表版的数据库为YDOT,即雅虎分布式有序表(Yhoo!Distributed Ordered Table)。绝大多数系统不关心数据的组织方式。但是,有个重要的方面对物理数据的组织方式是敏感的。尤其是采用散列表方式组织的数据,往往可以把负载很均衡地分散到不同的服务器。如果数据是有序的,部分更频繁访问的关键字空间(ky space)将会出现“热点”(htpot)效应。比如,如果状态更新是通过时间排序,那么最近的更新是用户最感兴趣的,则包含在该段时间范围末的数据分区的服务器负荷会最重。在不影响系统向外扩展下,我们不允许“热点”效应持续。
逻辑有序的数据实际上是存储在物理相连的记录分区上,但是当分区无序组织时,这些数据就可能存储在多台物理服务器上。我们可以根据负载,动态移动分区来解决“热点”效应问题。如果一台服务器上有多个热分区(ht partition),可以把这些分区移到负荷较低的服务器上。此外,我们还可以动态划分分区,这样某个热分区上的负载可以分散到几台服务器上[2]。这种在存储单元间移动和划分分区的策略和先前提到的改变一条记录的主备份性机制是不同的:对于前者,改变记录的主备份会导致在一台服务器发起的更新延迟,但通常不影响给定记录分区记录的累积读写操作负荷。需要划分和移动分区的一个特例是当我们想要更新或插入大量的记录。在这种情况下,如果不采取特殊措施,就会发生只向几台服务器发送大批量更新操作,从而导致服务器负载不均衡。因此,需要理解更新操作是如何分布在关键字空间(ky space),必要的时候,可以为后期的一连串更新操作预先划分和移动分区(Slberstein等2008)。
我们把应用和物理数据组织细节相分离。对于单记录的读写操作,使用路由层可以使应用免于受分区移动和划分的影响。对于范围扫描,我们需要提供进一步抽象:假设我们需要扫描年龄在21~30岁的所有注册用户,执行该查询可能意味着在一台服务器上需要扫描包含几千条记录的数据分区,在另一台服务器上扫描另一个分区等。每个分区有几千条记录,由于它们在磁盘上是顺序存储的,因此可以快速扫描。我们希望这些分区的移动和划分对于应用是透明的。解决该问题的一个巧妙方式是借鉴迭代器(ierator)的思想:当应用执行扫描时,我们返回一组记录,然后准备好下一组记录,触发应用继续扫描。因此,当应用执行完一次批处理,开始请求更多的数据时,可以把这些请求转换到包含下一组记录分区的新存储服务器上执行。
牺牲一致性,换取可用性
时间轴一致性处理一般问题效率高,且语义简洁,但它也并不完美。有时,整个数据中心崩溃(如断电)或者不可用(如断网),那么以该数据中心作为主备份的记录将不可写。这种情况暴露了已有的在一致性、可用性和分区容忍性(prtition tolerance)上的平衡问题(tade-off):在所有情况下,这三者属性只能保证其中的两个。由于数据库是全球性的,分区必然存在且不会造成大的影响,因此实际上我们只需要处理一致性和可用性间的平衡。如果一个数据中心断网了,可能有些新的更新操作还没有传播到其他的数据副本,我们可以通过两种方式保证一致性:一是为了保持一致性,在该数据中心可用前,不允许执行数据更新;二是为了保持可用性,要违背时间轴一致性原则,允许一些更新操作应用到非主备份的记录。
系统为应用提供了基于表级粒度(pr-table basis)来选择相应策略。如果对于某个特定的表,可用性对于该应用的优先级比一致性高,那么当一个数据中心断网时,系统会临时转换该表中任何不可用记录的主备份性到其他的数据中心。该决策牺牲时间轴一致性,有效地支持了可用性,如图4-2中的例子所示。当恢复完一个不可用的数据中心,系统会自动协调任何有冲突的更新记录,并通知应用这些冲突信息。该协调保证了即使不能满足时间轴一致性,数据库在任何数据备份上都能收敛到相同的值。另一方面,对于应用而言,如果一致性优先级比可用性高,则会保持时间轴一致性而不会传递主备份性,这样,一些写操作执行会失败。
对于某些操作,一致性和可用性间的平衡较易于把握。例如,假设有个关于投票的应用,用户可以对各种问题进行投票(如“你最喜欢的颜色是什么?”),投票结果作为计数存储在数据库上。计数操作(如增加)是可交换的(cmmutative),因此,在不破坏时间轴一致性的情况下,甚至可以应用于非主备份副本上。一般来说,复制机制可以在不同副本间传递记录的新版本,但是对于可交换操作,我们实际上是传递操作(如增加)而不是结果值。那么,主备份在任何时间接收到操作(不论是在正常的数据操作期间还是在某个数据中心失效后),它都可以执行该操作,而不需要担心操作是否乱序。该策略的一个局限是可交换和非可交换的操作不可以混合:因为我们无法知道如何合理地对一个计数值的增加操作和重写操作进行排序,所以当记录插入后,禁止在任何时刻对其计数器设值。
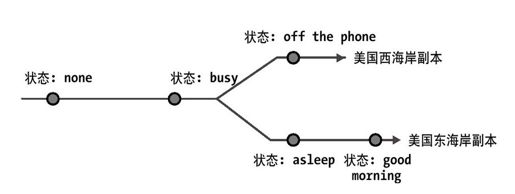
图 4-2:西部数据中心断网,更新时间轴产生交叉(frks)
PNUTS的另一个扩展是允许对多条记录执行更新操作。我们主要研究基于记录级的时间轴一致性的原因是很多Web应用负载涉及在某一时刻对单条记录的更新操作。但是,有时更新多条记录更合适。例如,在社会网络应用中,可能存在双向好友链接:如果Alice和Bob是好友,那么Alice会出现在Bob的好友列表,同样,Bob也会出现在Alice的好友列表。因此,当Alice和Bob成为好友时,我们需要更新两条记录。因为系统不提供ACID事务,所以无法保证该更新是原子性的。但是,我们可以采取绑定式写操作(bndled writes):当对数据库执行一次调用时,应用可以请求两个写操作,数据库会保证两个写操作最终都会执行。为了实现这点,系统对请求的写操作写日志,如果初始执行失败,系统会重试这两个写操作,直到它们都成功。该方法保证了记录级的时间轴一致性,由于重试可以异步执行,这也保证了系统的性能。
总之,时间轴一致性为记录更新如何传播提供了简单的语义支持(smantics),以及为应用如何牺牲读延迟来换取流通性(crrency)提供了灵活性。但是,它并不支持一般的ACID事务,尤其是执行多条记录的读写操作事务。
[1]事务具有原子性、一致性、隔离性(不受其他并发事务影响)和持久性。
[2]细心的读者可能会发现,如果所有的更新影响包含该时间范围内的分区,划分该分区并不能解决问题,需要一些其他方法,如通过组合关键字如用户名和时间进行排序。
