集体调解
我相信充分利用全网数据是解决匹配问题的关键。这种思想体现在称为“集体调解”(cllective reconciliation)或“集体实体决议”(cllective entity resolution)。有关这方面的详细讨论,我建议阅读Indrajit Bhattacharya的博士论文,你可以在http://www.lib.umd.edu/drum/handle/1903/4241获取该论文。
在本节中,我将从高层次介绍集体调解的涵义。这些算法的实现细节根据你所处理的特定类型的数据会有很大区别,而且超出了本章的讨论范围,但是我希望一个高层次的概要会帮助你去试验以及使你阅读别人在该主题上所做的工作会更容易。
首先,考虑如下情况,我们有两个电影数据集,两个数据集包含的信息略有不同。从这两个数据集抽取两份数据片段并进行图形化表示,如图20-5所示。我们已经确定仅仅基于名字进行匹配是不明智的,因此我们无法仅仅通过名字来确定两个对象是一样的。但是,我们相信图A中的节点node10和图B中的节点node22可能是一样的,因为它们的名字都是“Julia Roberts”,图A中的节点node12和图B中的节点node27可能是一致的,因为它们都是命名为“Ready to Wear”。
技巧在于我们在两个图中的数据项有潜在的匹配,而且这些数据项相互间有一定的连接——潜在匹配的“Julia Roberts”节点和潜在匹配的“Ready to Wear”之间有连接。这条连接为这二者的匹配提供了更多的证据。这种匹配关系是否是最终结论取决于很多可能性假设,如有多个名叫Julia Roberts的女主角在名为《Ready to Wear》的电影中,但是在该案例情况下,我们可以认为这些关联匹配是正确的。
这些关联的实现方式有很多区别,但是主流技术称为“消息传递”(mssage-passing)。通常,图A中的节点node12知道它可能和图B中的节点node27一样,查看图B中的所有连接,它给图A中的邻居节点发送了消息。连接所有演员的消息可能是“你可能和节点node22或节点node25一样”。而节点node10接收到这条消息后,意识到“实际上,我已经认为我可能和节点node22一样”。同理,节点node10告诉节点node12它可能的所有电影。图20-6显示了可能的过程。
你很可能明白了为什么这被称为“集体调解”,而不是拼合记录,我们实际上是想要一次性把所有东西都归并起来,而且节点之间可以互相提供信息是否需要归并。当然,这只是一个很小的例子,但是考虑一下图20-7所示的更复杂的一项。
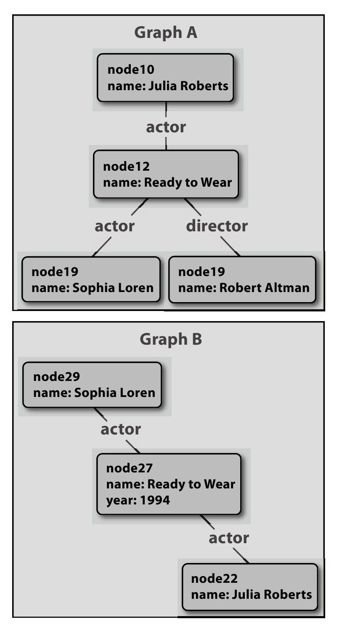
图 20-5:两个不同的电影数据集的数据片段
在该图中,名字为“Ready to Wear”的节点并不匹配,而且我们甚至没有一个节点命名为node10!我们如何知道它是Julia Roberts?但是,我们已经稍微扩展了网络范围,包含一些其他Julia Roberts为明星的电影,幸运的是,“消息传递”机制可以通过很多迭代来完成。可能你明白了“消息传递”算法的作用?以下是基本的思想:
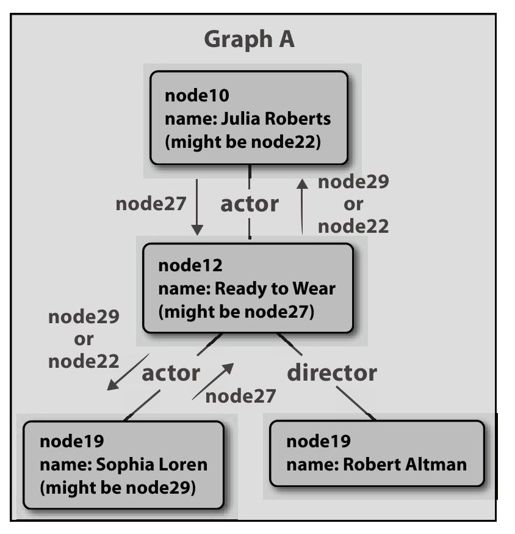
图 20-6:节点间的消息传递
1.节点node11决定它和节点node23有可能匹配,因为它们的名字相同;
2.相似地,节点node15认为它和节点node9有可能匹配(如果我们有更多关于Julia Roberts的电影数据,就可以继续更多这样的推测了);
3.节点node11发送了一条消息给节点node10:“你可能和节点node22或者节点node24匹配”;
4.类似,节点node15发送了一条消息给节点node10:“你可能和节点node22或节点node25匹配”;
5.节点node10在收到了所有这些消息后,下定结论认为很可能是节点node22,因为那是它所共有的消息;
6.注意,节点node10已经确定了自己所匹配的节点,因而可以发送一条消息到所有它所连接的节点(包括它收到消息的节点),给出消息它所认为的它们可能和哪些节点相匹配;
7.节点node12收到了节点node10和节点node19的消息:“你可能和节点node23匹配”,因此它最后选择和节点node23匹配。
虽然只有一个演员名字相同,但是我们已经确定《Prêt-à-Porter》和《Ready to Wear》是同一部电影。
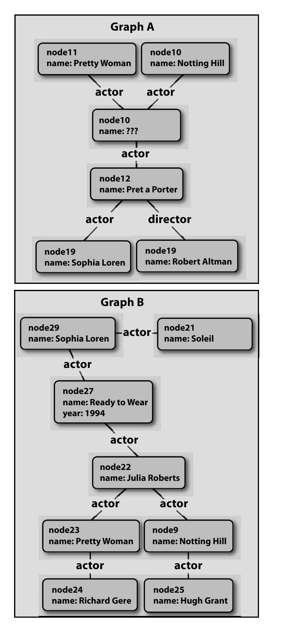
图 20-7:一个更复杂的归并问题
注意我们是如何利用全网的事实来确定最终的匹配?这就是集体调解的精髓,以及它如此强大的原因。这一观点可以继续扩展:在某些实验中,我发现你可以仅仅使用电影的发布年份来连接两个电影和演员的数据集。某个明星在特定12个年份出演的电影,以及和在8个特定年份另一个不同的明星共同出演的事实就足以唯一性地确定这两个人的身份。
当然,其中的实现和数学细节可能非常复杂,但那些不在本章的讨论范围之内。实现这种技术的可定制性版本就留个读者作为非常有益的练习了。
