BitTorrent
当你的用例是高度定制时,最好能够把数据处理流程调成“最优”。砍掉这些琐碎的东西和多余的载荷,使得任意的客户端和服务器之间的数据传输通信只适用于客户端和服务器紧密耦合并且协作良好的情况。BitTorrent在分布式的一组节点上来回移动大量的二进制数据块的速度是异常惊人的,这是对高度定制的用例进行优化的一个很好的例子。
私有权/P2P
HTTP协议的一大不足是每个有效的请求/响应对包含了与之前相同的数据头集合,即使这对操作可能是某个特定的客户端和服务器的第n对的交互操作。如果能够在初始阶段管理好这些交互,使得数据通道除了位操作之外其他什么都不做,那岂不是更智能?确实如此。这个原因以及很多其他原因,驱动着“点到点”(Pint-2-Point或Peer-2-Peer)协议的很多实现,这些实现每天传输着大量的数据。
选择HTTP协议作为传输方式,这将带来一个问题:它对应的格式是什么?当然,如果一个传输协议在过去几年中已经变得无处不在,这个过程中基于其传输的数据也必然已经被“净化”了。
格式
XML为进一步实现数据格式化打下了基础。数据应该基于哪一个层次格式来通信的问题基本上已经解决了。现在对由XML衍生出的数据格式的讨论是所有一切讨论的起始。虽然现在有很多开发人员觉得采用XML格式是理所当然的,但是值得注意的是这种数据格式非常臃肿。XML基于文本的格式,在定义上非常有描述性,因而它通常不是用于通信的最佳格式。每当我参与现代协议和格式的讨论时,我就想起AOL专有的FDO模型。FDO是二进制的、紧凑的以比特存储的协议/格式结合,为300波特的现代连接进行了优化。幸运的是,网络连接已经发展到今天,宽带速度已经成为规范。
如上所述,正如HTTP协议一样,XML的劣势也是它的优势。如果我们在过去15年学到了些东西,那便是无处不在的可读的协议和格式——我真的是这么认为。一种格式越是被人们所理解,它就越可以进一步走向创新之路。当调试程序的唯一方式是通过解密工具把数据转换成用大脑可以理解的东西时,人类创造性和通信之间就开始存在严重的障碍。“成功的数据”可以为程序员所理解,而“失败的数据”只能通过计算机来处理。注意:有效载荷格式和元数据格式(通常是XML)之间存在区别。高清晰的视频数据(如最近的高清晰的轰动电影)占用了大量的物理空间,而且人们无法阅读它;我把这种数据称为有效载荷格式。描述性的信息,比如视频的元数据,是相对比较紧凑的。在网络中,通过有效载荷格式传输胜过元数据传输(只要问问你最喜欢的网络服务提供商它占多少比例就知道了),但是这种格式的数据在被计算机解码之前,相对显得呆板无趣。
接口
接口(AI)使事情变得开始有趣。一旦每个人都认识到大量的HTTP事务像传统的API调用一样在网络上无处不在,REST协议为我们把Web作为大分布式应用奠定了基础。Roy Fielding是HTTP1.1协议的贡献者之一,他教会我们如何像表示状态转换(Rpresentational State Transfer,REST)那样描述事物的思想框架。
开发者终于可以停止挣扎于使用CORBA和DCOM模式来把他们的逻辑和数据分布到联网的计算机上,转而借助于标准的HTTP和基于文本的工具来实现应用程序间在传统的Web应用层以下进行交互。
这导致你能够想到的几乎所有We b应用的API呈爆炸式发展,如图8-1所示。API成为每个产品经理必有的东西。这既是件好事,也是件坏事。从好的方面来看,成千上万的产品公开它们的数据,全世界都能够访问。Programmable Web(http://www.programmableweb.com/)记录了好几百个这样的产品,而且随时可以使用。从坏的方面来看,很多API很仓促地开发出来,没有考虑到它们可能会如何被使用。其结果是由于API调用程序根据性能或者功能特征,带来从WAN到各种可能满足或可能不满足你的期望的不同终端范围的API调用高潮。很少有Web API提供服务层协议(Srvice-Level Agreement,SLA),如果真的有这样的API,其状况通常是很悲惨的。
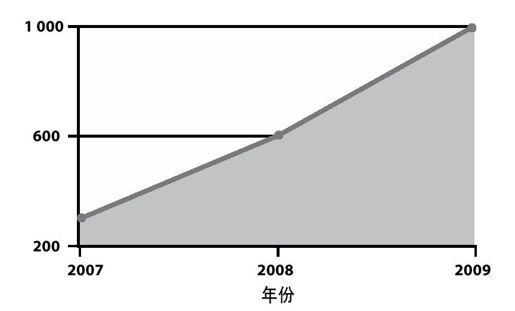
图 8-1:在过去几年公用的API数量增长情况,数据来源于Programmable Web网站
为了使某个应用的数据和功能能够通过API获取,不论是真正的还是假想的需求,都可以在网络上创造一些有趣的挑战。
如果查看今天的API在网络上是如何使用的,那么你会发现它们看起来是随意传输数据,且没有严格的SLA。在规模上,我们第一次有软件可以非常有规律地和其他软件进行集成。这种集成方式称为“混搭服务”(mshups),因为它们把数据从各个服务中“混搭”在一起。越来越多的终端用户期望数据在他们的社交应用能够具有实时性,但是支持实时数据传输的基础设施还远远不够丰富。在实现实时应用时,软件工程师无限复杂的创新性已经为应用提供实时通知产生了很多不同的模型(如“Comet”、“Web Hooks”,以及各种“PubSub”消息通知系统)。这些模型其中有些行之有效,有些则没有。不管你的方法是什么,解决方案在根本上没有真正的“魔术”;相反,饱受考验的框架通常都是在“幕后”一直发挥着作用。
在应用软件中有两个基本的时间流处理(tme-flow-processing)原语(Pimitives):轮询(Plling)和事件(Eents)。应用程序根据时间来执行,而用户交互的应用程序需要用户或者另一个服务的输入。该输入通过轮询或者事件方式在应用中执行。值得注意的是你可以通过以上任意一种模式来实现,在计算机课堂上应该讲解到使用它们的一些绝妙技巧,我不在这里赘述。这里重要的是定义关于应用程序如何收集它的相关输入的更高层的概念。使用例子来说明表达这两种模型最简单。
轮询
轮询是通过应用程序不断询问中断是否有变化来实现的;如果检测到变化,程序会执行定义好的动作。一个常用的类比是酒吧服务员。想象一家酒吧,有1个服务员和10个顾客。如果这个服务员是轮询模式的服务员,他会不断地询问每个顾客他们是否要喝酒。在整个酒吧询问“要喝一杯吗?”“要喝一杯吗?”“要喝一杯吗?”“要喝一杯吗?”等。不时地,其中一个被询问的顾客会回答“来一杯”,则该服务员就先不询问了,给顾客倒一杯酒。轮询的方式实现起来美丽简单,但是通常这对于客户端和服务器都是非常低效(正如类比所示)。
速率控制[1]
提供API为开发者进行访问的方式来展示你的在线服务,通常可以很容易实现;而基于应用程序构建一些框架并把数据连接起来就不是那么容易了。但是,一旦把API开放出来,你就无法控制这些API将会如何被其他应用程序使用。对程序的完全控制已经保护代码运行了几千年的时间。因此,构建一个大规模的“Web API”(即“Web服务”)需要付出慎重的考虑、熟练的管理和业务操作。
如果有人幸运地构建出一个令开发者很感兴趣的API,因此其轮询负载将变得很大,在应用上处理负荷增长的最简单的方式是通过IP或包头、通信层的访问,从而限制API的使用。虽然这种处理方式解决了伸缩性问题,但是它中断了为取悦用户而集成这个API的程序的处理流程。开发者不希望在他们的应用中构建“节流层”(Trottling Layer),他们只是希望执行习惯性的调用,使得系统能够“工作即可”。实际上,在系统中解决数据访问问题需要花费的精力比基于IP的速率限制还要多(即“节流”),但是我们通常无法投入足够的时间来调研真正的解决方案。一些社交数据的应用已经投入精力来解决这个问题,他们的API能够承载高负荷访问(如Digg)。但是绝大多数应用还不具备这一特点。
做正确的事
然而,包含大量社交数据的流行的社交应用程序在基础设施上不应该要求有庞大的资金投入,也不必是具有很强横向扩展性的应用。这些方面都会抑制产品的创新,耗费大量的资金。相反地,利用饱经时间考验的“事件”原语,简单地说是通过有序方式。大量规则说明了访问社交数据的90%以上的调用是不必要的。绝大多数时候,这些数据甚至是无法访问的。仍然以之前的酒吧服务员为例,当顾客回答“不喝酒”时,会由于被服务员不断地询问相同的问题而开始变得不耐烦。
为了更新某个用户拍的照片,不断地询问Flickr是一种资源浪费。相反地,如果当用户更新了他的照片,Flickr系统通知你的应用程序来调用,这种处理方式就会更高效,对用户更重要以及更及时。
每加仑0英里的效率
我将使用众所周知的“Flickr,Friendfeed的例子”来强调在获取社交数据时,使用轮询方式的低效性。总体来说,社交数据是由用户生成的。这意味着依赖于利用社交数据的社交应用是基于人们的行为,而不是更容易预测和管理的计算机的行为。当我们开发的软件的价值完全是人类活动的某个功能时,事情开始变得有趣。这个例子很有趣,因为发布者(Fickr)和消费者(Fiendfeed)都对用户的笔记留言进行比较,这能够对通过轮询方式异步传输的“外部调用”(ofbox)的本质问题产生有价值的洞察。
在2008年7月,Even Henshaw-Plath和Kellan Elliot-McCrea在俄勒冈州波特兰(Prtland)市组织的OSCON(Open Source Convention,O'Reilly的开源集会)会议上发表了演讲“Beyond REST?”(htp://www.slideshare.net/kellan/beyond-rest)。在该演讲中,他们透露为了确定Friendfeed的4.6万的用户账号在最近24小时内是否上传相片,Friendfeed每天会请求Flickr的API 290万次。而它的4.6万的用户,其中仅仅7000个用户在这期间内会访问Flickr,可能会上传照片。
一条著名的社交应用规则,称为“1-9-90”规则,在过去几年中开始兴起。其要旨是,如果你考虑社交应用100%的用户基础,其中1%的用户对核心数据有贡献(如“上传一张照片”),9%的用户参与贡献数据(如“把一张照片标记为最喜欢的”),而90%的用户仅仅浏览这些数据(如“视图照片”)。如果保守地把该规则应用于Flickr/Friendfeed范例中,则可以说明在某一天有7000个用户访问了Flickr,有700个用户会上传照片。这意味着Friendfeed请求Flickr接口290万次,只是为了知道他们的700个用户确实做了某些更新。这种方式“命中”的最高比率是0.02%,即4000次请求发现1条更新。
把Flickr/Friendfeed例子和酒吧服务员的类比结合起来,意味着轮询方式的酒吧服务员为了使得顾客需要酒时可以实时得到,需要询问这位顾客4000次“要喝一杯吗?”,他才会回答1次“来一杯”。
一方面,应用程序调用本地的“内部调用”(O-box)API来“吸纳”这种低效性。另一方面,应用程序执行Web API调用的效率也非常低下。如果你根据当前所有的社交应用来考虑这个例子,其代价确实会非常令人震惊。
事件驱动型的软件可以驱动应用程序达到实时性,而社交数据在本质上就需要实时通信。通过在线银行软件查看某张支票账户清除了我的支票账户的操作,“拖延”一两天才能看到是可以容忍的;但是一个年轻人要看到他最好的朋友在春天拍摄的照片的请求,需要被立即处理。
事件
事件驱动型的架构和轮询驱动型不同,它采取了不同的解决方案。和酒吧服务员不断地询问顾客们是否需要喝酒不同,这种模型的酒吧服务员仅仅站在吧台后面,等待顾客告诉说他们想要喝酒。虽然事件处理通常更有效,但是考虑到具体的“事件”概念本身,它确实要求一些额外的代价。事件需要被消除、捕获;事件处理框架必须存在,这导致了事件处理方式的复杂性。轮询方式可以简单地通过线性、过程化的循环来完成,而这种简单性也正是它被过度滥用的一个关键原因。
从侏罗纪时期开始,轮询和事件这两种执行流规范奠定了软件开发的基础。客户端和服务器软件都依赖这两种模式来控制执行流以及应用的行为。操作系统通过恰当地运用它们,提供流畅的用户输入和交互体验。作为一个开发人员,你选择哪一种模型通常取决于你所使用的开发语言,或者你正在使用的库或框架的功能。虽然这两者的性能特征在本地、内部API调用的应用中通常区别不大,但是当执行远程、外部API调用的操作时,其性能特征可能导致应用程序瘫痪。注意,当处理用户界面和图形渲染时,本地性能的区别对于应用是至关重要的。
一旦程序员开始大量注入远程API调用到本地应用程序,轮询和事件处理方式之间的区别变得非常明显。本地I/O调用和远程I/O调用之间的区别呈指数增长。所有通过磁盘、内存和芯片接口来加快应用程序的工作变得毫无意义。图8-2说明了本地数据访问和远程数据访问之间的I/O性能的相对区别。为了简单起见,我已经隐含地说明了固有的IP连接断开延迟,并且作为带宽/吞吐量功能来说明这一点。然而,如果你真正考虑实际的协议交互作为全部数据传输代价的功能,延迟问题会变得更加严重。
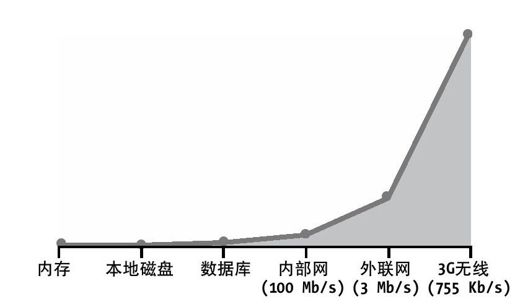
图 8-2:文件描述符在各种连接类型上的操作的相对吞吐量
正如你所看到的,差异非常明显。在远程数据访问次数远多于本地数据访问的极端情况下,轮询和事件模式在驱动应用时所产生的延迟的差别会更加明显。当你的软件为了采取某些措施而需要知道在网络中某个服务是否发生变化时,你往往没有足够的时间来执行低效的轮询。如果酒吧服务员问了4000次的“要喝一杯吗?”,却只能得到顾客1次的肯定回答,当服务员需要问遍城镇里的所有顾客时,浪费在查询上的时间都要爆炸了。轮询和事件之间各有千秋,但是只有一种模型在Web上易于实现:轮询。基于HTTP/REST的客户端-服务器编程从来没有为Web应用开发提供正式的事件驱动框架。结果导致Web充满了低时效性的社交数据驱动的应用,社交数据的时效性特征让这一问题更为突出。如果我的朋友明天可能在城镇,我可不想自己知道时为时已晚。我们希望应用能够“实时”就像构建在要倒塌的扑克牌堆砌的房子那样,而我们看到墙变得越来越高。
HTML 5事件
值得注意的是HTML5规范突出了事件模型和在高层上支持双向通信功能的“Web Socket”框架。XMLHttpRequest已经把GUI Web应用提升到一个新的层次,我猜想“Web Sockets”将对今后几年的Web应用开发产生重大影响。允许基于浏览器的应用以更类似于socket的方式来访问数据必将带来好的结果。
WAN规模的事件
分布式事件处理和通知不是一个新问题,而它的解决方案也不是。事实上,企业空间已经生成了无比强大和高效的“消息总线”的解决方案,尽管这是专利的。Tibco公司作为企业消息总线解决方案的领先提供商而广为人知。然而,企业消息总线的关注重点在于它们传输的数据的临界值,而非通过各种各样的连接堆栈方能实现与多样化的终端间进行连接。股票交易需要确保传输成功并保护隐私。要达到这种程度需要付出较高的代价,该代价转化为了高额的牌照费,但Internet上,这一转化进行得不是很好。社交数据是通过对终端用户免费的应用创建和消费的。因此,各企业公司提供的昂贵的、私有的和难以集成的消息总线解决方案在Web上不受欢迎。
利用生成社交数据的技术来提供事件驱动通知机制的解决方案,通常正是基于该系统已有的技术。可以使用HTTP POST方式来推动整个WAN范围内任意服务之间的事件,使用标准格式(XL),在执行控制流过程中的延迟可以被关闭。Jeff Lindsay在宣传HTTP POST的事件传输模型时给出了一个生动的比喻,并由此获得了绰号“Web Hooks”(htp://blog.webhooks.org/)。再强调一次,HTTP不是最优化的传输事件协议,XML也不是最优格式,但是这二者提供了最丰富、实用的机制来解决服务器之间实时通信的问题。
如果社交数据变得更加隐蔽,有可能发生以下两件事之一:一是我们作为消费者,将继续忍受,而我们的行为模式和期望将会更符合低级模型;二是我们停止使用该产品,因为它们的使用价值已经下降到不足以抵消使用所需要忍受的烦恼。前者有很多先例(Bta与VHS),因为我们通常接受我们想要解决的问题的非最佳解决方案。后者每天都发生,因为发展迅猛的工业和产品通常由于时间和最后的优化因素而崩溃。在一个框架变成标准之前,中间的事件网关可以通过众多协议和格式代为转发事件和数据的方式,起到连通数据发布者和阅读者的桥梁作用。如果事件机制的实现可以做到成本低且通用,它将可以消除社交数据的破坏性的延迟。“Web规模”的实时社交数据的普遍应用依赖于事件驱动模型。
Gnip项目[2]是基于以下理念成立的:围绕社交数据消费的事件驱动架构是提供实时访问模式的唯一方式。然而,由于轮询方式还会存在,Gnip仍然选择轮询方式作为社交数据交互的首选模型。
单一的API集成通常简单明了。然而,当你要集成很多不同的终端时,便开始出现效率低下的问题。Gnip为它的终端数据消费者实现了多API集成的工作,这些API最后只需要通过唯一点就可以完成集成Gnip。
[1]在计算机网络中,速率控制常用在一个网络接口上,用于控制发送和接收数据的通信速率。流量小于或等于指定速率的数据会被发送,而流量若是超过了指定速率,则被丢弃或延迟发送。
[2]想了解更多信息,可访问其网站:http://www.gnip.com/。
