用DNA存储数据
基因组是生命体的数据库。它由DNA分子写成,其副本存储在人体的每一个细胞中(只有少数例外)。这种模式在自然界中普遍存在,即使是最简单的生命形式也不例外。基因组中编码的信息包含制造蛋白质的指令,而这些蛋白质组成的分子机器则运行着细胞内的化学系统。这就是为什么我认为DNA是可容错、冗余的存储形式。
你身体里的几乎每一个细胞中都有一个数据中心,数据中心里存储着这些基因数据库。我们称这个数据中心为细胞核,细胞核中又含有染色体。所有的人都是双倍体,你也不例外。你的每一个染色体都由两个副本构成,分别来自于你的父亲和你的母亲。除了普通的染色体之外,人类还有性染色体。女性有两条X染色体,男性有一条X和一条Y染色体。这些基因数据存储库的基本存储单元是DNA双链,两条链通过神奇的双螺旋结构缠绕在一起,如图15-1所示。
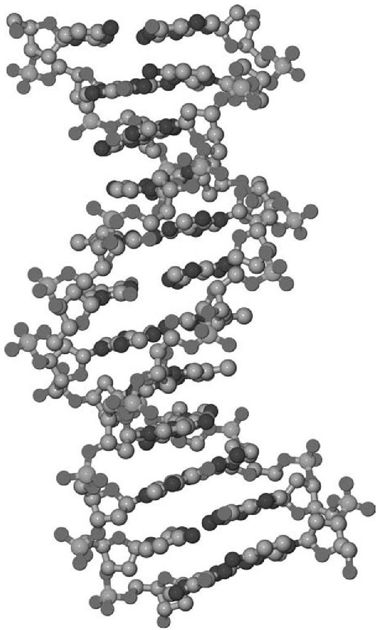
图 15-1:DNA中的一个小片段,由POV-Ray软件从PDB文件1BNA生成,doi:10.2210/pdb1bna/pdb(见彩图51)
DNA的每条链都是由一串碱基构成的。DNA中含有四种碱基——腺嘌呤、鸟嘌呤、胞嘧啶、胸腺嘧啶(或者分别缩写为A、G、C、T)。基因数据库正是编码存于这个四元体系中。在人体中,DNA含有3G(3×109)个碱基,分布在两个稍有不同的副本中。
DNA生RNA,RNA生蛋白质
DNA到底是用来做什么的?人类基因组中的大部分似乎并没有直接的作用,尽管它们可能有一些潜在用途。基因组中的2%构成基因,基因的序列决定了蛋白质的构造。DNA是由四进制编码写成的大分子,同样,蛋白质是由二十进制编码写成的稍小的分子。组成蛋白质的序列编码确定了蛋白质的形状,而蛋白质的形状和化学结构又决定了其在细胞的分子机器中担当哪一个齿轮的角色。
和其他文件格式一样,读取和显示DNA序列中所编码的信息也需要特殊的读取装置。和其他种类的文件不一样的是,这个装置是在纳米尺度下在活细胞中工作的,它根据基因中碱基的排列,按照一定的顺序查找各个分子。RNA是DNA的短命表兄,它有一个类似四进制代码的系统。当一个基因被激活时,蛋白质分子机器系统会在RNA中生成该基因的副本。这些RNA副本被转移到蛋白质机器中翻译成蛋白质,每个RNA分子都能用作许多蛋白质分子的模板。
如此看来,DNA和蛋白质形成了一种伙伴关系:蛋白质提供机器装置,在基因中的碱基序列指导下制造新的蛋白质。虽然DNA被认为是“生命的蓝图”,但它也只能在细胞中分子(尤其是蛋白质)已经存在的情况下发挥作用。
通过控制负责激活基因的蛋白质的产生,细胞可以用产生蛋白质的方式对刺激物或者其他需要作出反应。通过这些机制,其他细胞可以通过发送信号分子(比如激素)来控制某个细胞。许多药物也通过这些机制产生作用。
每一个基因都由其周围控制蛋白质产生的序列做了标记(见图15-2)。基因组中编码的一些蛋白质可以选择性地用于这些标记。一些蛋白质会促进基因的表达,而另外一些则会阻止该基因的表达。

图 15-2:图示为一个DNA片段,其中包含一个基因,以及基因周围用来和细胞调控机制相互作用来限制基因表达的区域。这里基因由一个启动子和一个增强子引导,这样基因就被做了标记,使得细胞知道何时应当表达该基因(见彩图52)
使用药物Hack你的DNA数据
让我们来幻想一下:O'Reilly要在“Hacks”系列图书中增加一本《DNA Hacks》——其中包含100种方式来修改、重构或者增强你的基因数据库。那么这些Hack方式的一半差不多都通过阻断或者激励某一类蛋白质的活动来进行,这类蛋白质被称作G蛋白偶联受体(G-protein coupled receptors,GPCR)。例如,胃酸分泌由体内信号作用于一个特殊的GPCR来激发。当信号分子触及GPCR时,将会发生一系列的相互作用,以至会“打开”或“关闭”你的DNA中的基因。例如用来治疗胃溃疡和胃痛的雷尼替丁,通过在信号和GPCR之间横插一脚来阻断信号,从而发挥作用。和在Email客户端中使用智能的hack来过滤垃圾邮件一样(比如过滤包含“V1Agr4”的消息),雷尼替丁就是一个智能的hack,人们通过它来阻止传递“请分泌更多胃酸”信息的信号穿过细胞屏障。
还有一种形式的DNA元数据(mtadata)值得一提。尽管基因组通常情况下被看做一个只读数据库,但是DNA可以因为环境因素被化学修改,导致某些基因被抑制。这些化学变化并不改变基因自身的编码,而是通过提供附加的注释使得细胞机器不再容易转录该基因。研究这些化学修改的学科叫做表观遗传学。对于这些修改在身体组成中所扮演角色的研究现在仍旧处于初级阶段。不过目前已知的是,一些表观遗传学变化会关掉在某个特定细胞中不需要的基因(肌肉细胞需要的基因和肝脏细胞并不相同)。基因可以因为环境因素而被关掉——这似乎毫无疑问地会在幻想中的《DNA Hacks》一书的未来版本中出现,这确实让人激动不已。例如,生长素基因可以因为饥饿而被关掉。更有趣的是,这些变化可能会遗传给孩子,换句话说,我们的生活方式产生的变化可以影响到下一代的基因,这在以前被认为是天方夜谭。
癌症
癌症是一种由于细胞增生失控而产生的疾病。一个细胞的生长和位置是由它的基因控制的,也就是说,它只会以可控的方式分裂。除此之外,人类基因组中包含了很多肿瘤抑制基因,它们可以在细胞不受控增生的时候使细胞消亡。那么癌症是怎么发生的呢?答案就在数据库损坏中。化学致癌物(比如香烟中的)、辐射和病毒都能够使你的DNA产生变化。
当计算机硬盘碰到小损坏的时候,你可能注意不到有什么不同。不过当一定数量的损坏不断积累,程序就会开始崩溃,文件就打不开了。基因组同样如此。损坏足够多之后,基因的控制会产生紊乱,导致不正常表达的发生。如果你能触及正确的基因,那么细胞会开始向它自己发送生长和分裂的信号。其他的基因(比如肿瘤抑制基因)可以被完全关闭,一旦如此,你便在一步步走向癌症。
当然,硬盘在大多数情况下是可靠的。大多数硬盘中都有专门的系统来检测和重映射坏道。硬盘中也包含了检测磁盘损伤并通知用户的系统(比如SMART监控)。为了获得额外的可靠性,你可以通过RAID1阵列来将两个硬盘相互镜像。这样,两个硬盘的内容是相同的,如果一个硬盘出现错误,另一个硬盘便可以替代它并恢复数据。细胞自身也有检测和修复DNA损伤的机制。让我们来回忆一下,DNA分子以双螺旋的形式存在,一条链上的碱基与另一条链上的对应碱基互补配对。如果一条链发生损伤,它可以通过另一条链作为模板进行修复(类似硬盘的RAID1方式)。对于更大损伤的修复,还可以采用其他机制。
如果损伤不能修复,肿瘤凋亡基因就会启动,阻止细胞分裂并最终导致细胞程序性死亡。在理想的情况下,DNA受到损伤的细胞可以得到修复,类似硬盘的SMART机制。涉足过计算机集群(比方说5000个硬盘的规模)的人都会知道硬盘故障是多么的频发。想想人体内有100万亿个细胞,他们大概会奇怪为什么癌症的发病率会比较低。
复制
前文中已经说到,DNA是由缠绕在一起的两条链构成的。两条链是互补的:DNA的四种碱基都有对应的互补碱基(A和G互补,C和T互补),互补碱基出现在互补链的相同位置。沃森和克里克[1]在他们揭示DNA结构的论文中有一段著名的论述:“我们注意到我们的碱基互补配对假说直接给出了一种可行的基因物质复制机制。”
每一个DNA链都可以用作另一个链的模板,用以复制DNA双螺旋。细胞可以分离两条链,将他们分别作为模板,用互补碱基制造新链。在细胞分裂为两个新细胞时,上述过程就会发生(见图15-3)。
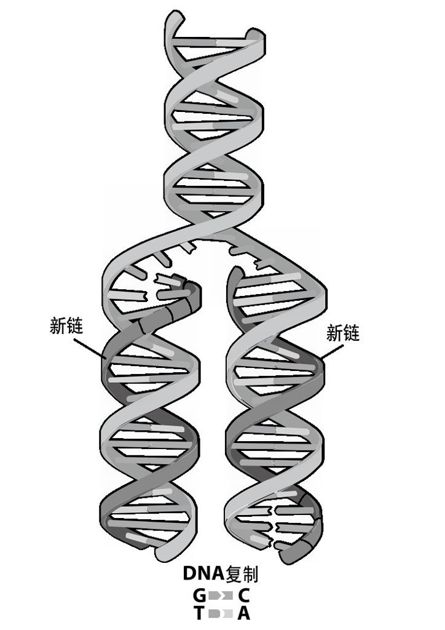
图 15-3 使用两个原始DNA链(白色)作为模板制造两个新链(黑色)的DNA复制过程,产生了两个新的双螺旋分子(照片来自http://genome.gov/glossary.cfm)
破解基因编码
假设未来文明出土了一块21世纪的硬盘。即使未来人能够理解文件系统(如前所述),文本文件在硬盘上最终还是以二进制形式储存的。如果没有将7bit数据转换为一个字母的7bit ASCII码表,信息就会无法解读。
1961年,克里克和布伦纳[2]开始了基因中类似的编码的逆向工程。ASCII将二进制转换为90个左右的字符,每个字符必需7个比特,即27=128(实际上还有一位用于奇偶校验)。在DNA中,四进制的碱基代码需要编码21个字母(20个氨基酸和1个终止信号),那么每个字符就需要3个碱基(43=64)(见表15-1)。
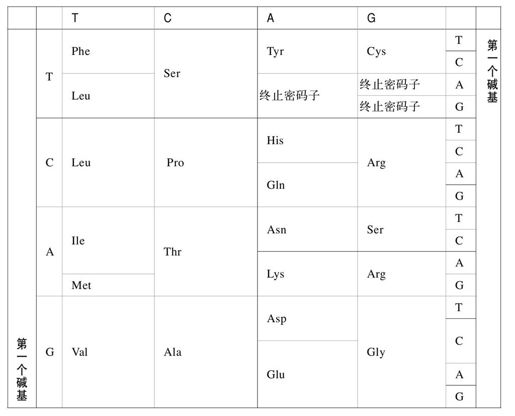
举例来说,三个碱基ACT编码了苏氨酸。当翻译机器在基因中遇到ACT三联密码子时,就会向制造中的蛋白质分子插入一个苏氨酸。我们可以注意到,密码子的数量(64)比信号(20个氨基酸和一个终止信号)要多。这意味着三联密码子有内建的冗余机制——大多数的氨基酸由不止一个密码子编码。
实际上,对大多数密码子来说,最后一个碱基对编码没有影响或者影响很小。这使得碱基突变(碱基的变化,比如A变为T)对蛋白质造成影响的可能性变得尽可能低,也就保护了蛋白质结构免受可能的碱基损伤影响。
人类基因组在有意外错误并入的情况下已经成长了几十亿年。因此,基因组中充满了没有作用功能的元素以及那些作用功能不明确的元素。虽然“垃圾DNA”这个说法现在已经不再流行了,但是不可否认的是,DNA中大量信息的存在仅仅是因为将它们移出基因组的选择性压力太小了或者根本不存在。
有些元素可以自行在基因组中复制、粘贴。例如,Alu元素,一个大约有300个碱基的碎片,其中包含的信息可以它自己复制为RNA(一种寿命短一些的类DNA分子),然后在其他位置重新复制进入基因组。这样的结果就好像让库布里克(Sanley Kubrick)的《The Shining》中的人物杰克和你一起写本书,书中写着“只工作,不玩耍,聪明杰克也变傻”[3]。Alu元素占到了人类基因组的10%。简单生命体基因组的大小限制了这些元素的增殖,人类基因组中这些元素的存在也就使得人类基因组更为深奥难懂了。
DNA作为数字化存储
进化的力量塑造了基因组。但在达尔文提出进化论的时候,他知道自己碰到了一个问题。常识告诉我们,高个子和矮个子生出的孩子身高会一般,那么“高”和“矮”的遗传信息会不可逆地混合在一起。有性繁殖会让一个物种达到平均水平,但事实上,正如和达尔文同一时代的孟德尔[4]所发现的,基因并没有不可逆地混合在一起。
原因在于DNA的数字化本质。中等个头的子代会有来自父亲和母亲各一套基因拷贝。基因并没有混合在一起,举例来说,序列中没有任何一点有半A半T的状态。所以信息并没有丢失,并且可以原样传递给孙代。复杂的生命得以进化并存在,这就是由DNA所实现的数字化储存。
进化作为算法
我们知道创造细胞中DNA的基本算法是:进化。DNA序列因变异而变化。那么进化是如何塑造DNA?令人吃惊的是,进化(以两代间DNA序列变化定义)的大部分是选择中性的,即进化对生命体没有任何影响。为什么是这样?很明显,在小种群中这种变化的发生有机会以后在种群中占支配地位。对大一些的种群来说,这种变化占支配地位的可能性较小,但是这种变化的数量会相应增加——所以最终中性进化仍然占优势。
这对解释个体间与物种间的差异很重要。中性进化是两个基因组之间任意不同的空模型(nll model)。这意味着,为了证明两个物种的相同基因中存在的差异是有意义的,科学家们一直想证明中性进化的“算法”无法生成两个序列。而这需要估算变化的比率,并确定其是否会快于或慢于中性理论所预计的速度。如果产生了多于预计的变化,则可能是由于这些变化已经为组织提供了功能上的改进,并且这些变化已在种群中迅速蔓延。如果变化比所预计的要慢,那么基因可能足够重要,使得绝大部分变化不再是中性的,然后被进化所拒绝。
人类参考基因组[5]目前被看做表示不同人混合的线性字符串,物种内的巨量差异意味着人类参考基因组可以更适当的被看做包含了种群内不同的图(Gaph)。一个个体的基因组可以被表示为参考图的一个遍历。
[1]即詹姆斯·杜威·沃森(Jmes D.Watson)与佛朗西斯·克里克(Fancis Crick),此二人因发现DNA分子双螺旋结构于1962年获得诺贝尔生理学或医学奖。
[2]悉尼·布伦纳(Sdney Brenner),南非生物学家,2002年诺贝尔生理学或医学奖获得者。
[3]“All work and no play makes Jack a dull boy.”是《The Shining》中的原文。
[4]格里哥·孟德尔(Gegor Mendel),奥地利遗传学家,遗传学的奠基人。他通过豌豆杂交实验,提出了遗传因子(现称基因)及显性性状、隐性性状等重要概念,并阐明其遗传规律,后人称之为孟德尔定律。
[5]Reference Human Genome,即人类基因组计划所测序的基因组。
