Coco Krumme
数据做了很多事情:它使我们能够区分科学与迷信,重复与随机。在过去几十年中,科学家们收集、整理和存储数据的能力已经有了长足的发展。从医学的决策制定到软饮料的市场营销到供应链的管理,我们更多地是依靠事实而不是直觉。我们依靠数据驱动这一切。
但是,数据无法驱动一切。在刚刚过去的20世纪,心理学家对人们对任何事物的解释接近理性式的稳重这一理论已经“颇有微词”。实际上,我们在解释信息的时候通常是有倾向性的。此外,真实世界并不是和骰子游戏的概率一样简单。相反地,个人必须从观察到的经验模式中提取可能性。
本章是关于存在于数据和分析之间的近似和偏见的讨论。它描述了一组新的实验和工具来帮助我们更有效地利用数据,而且从医学、消费和金融决策领域不断增加的文献中抽取一些例子。
假设我请你从图13-1中识别出与众不同的一只鸭子。
答案很简单且可以立即给出:人类的眼睛可以从一群白天鹅中识别出丑小鸭。但是,对于计算机,其解决方案就没就有这么简单:对于绝大多数情况,图像识别软件远落后于人类的视觉系统。

图 13-1:人类视觉系统善于识别出与众不同的鸭子
我们的大脑能够快速地对新事物和旧事物进行对比。我们善于进行类比和扩展:将手套、毛衣和滑雪者关联在一起;卡通老鼠和卡通熊是相似的;卡通熊和真正的熊相似;后两类的相似性本身很不一样。
即使你抹去上下文,我们的视觉系统仍然非常擅长挑选模式。以图13-2为例:你将如何把这些数据分成两组?
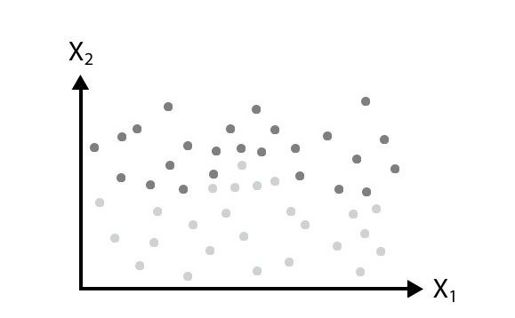
图 13-2:我们可以构建模型来区分两组数据集(见彩图47)
从添加维度和数据点开始,该任务如果由人来做,将会逐渐变得太复杂;而计算机则可以较轻松地解析该数据。你或许可以在两个点集之间画出一条近似曲线,但是计算机能够构建一个模型进而以最精确的方式划分数据。
现在,看看图13-3的图表模式,它显示了三个主要制造商在2005年1~10月这段时间的股票价格。观察以下图表,在阅读下一段前给出答案:基于给定的模式,你预期这三只股票中哪一只股票在2006年会涨?
你是选择了第三只股票吗?因为它看起来最后在涨。那么,你错了。事实上,如果你选择第一只或者第二只股票,你也一样错了。没有哪只股票会上涨,也没有哪只会下跌。实际上,这三个图表甚至并不能表示股票价格。它们是随机生成的:垃圾数据——可能有人会如是说。但是一旦相信这些图表属于某个公司(在本例中指制造业),就会产生各种各样的猜测。即使有真正的图表,除非你对某个公司或者行业有专业知识,否则很难基于一只股票过去10个月的业绩预测它将来的走势。
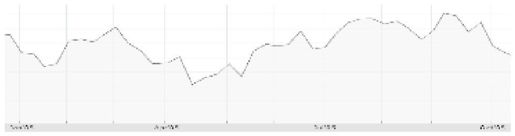
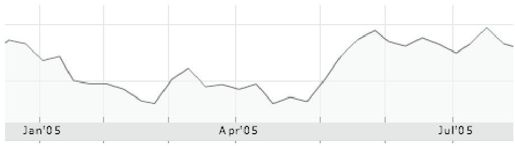
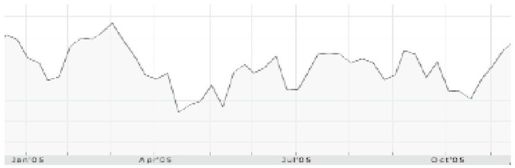
图 13-3:三只股票(a、b和c)在2005年的业绩(见彩图48)
从噪音数据捏造故事的倾向有时被称为“叙述谬误”(nrrative fallacy)。即使你对问题持怀疑态度(或者读得太快),当我们调查一些拔尖的MBA学生——其中有些应聘金融业的工作——相同的问题,他们很确定地表达对这些“股票”走势的信心。有些人说会涨,有些人说会跌。当为这些图表补充一些随机生成的“新闻剪辑”,并随机和某个图表放在一起时,这些学生更坚定了自己之前的预测——这些可能显示了人们根据数据给自己讲一个好故事的能力(Kumme,待发表)。(再看一下财经记者写的一些俏皮话:“对失业率上升的恐惧导致道琼斯指数下跌100点。”)
如果说人类善于观察模式,则人类同时也是编造关于统计学故事的大师。如果我们知道数据来自哪里及其涵义,这个问题就不那么严重;如果我们面对的是来自很多数据源的证据和高赌注的产出时,这个问题便可能会是灾难性的。
最后一个例子,在探讨问题之前,想一想你的期望。把过去的结论应用于当前分析的倾向被称为“确认偏见”(cnfirmation bias)(Lrd等1979)。(想一想你认识的某些人,他们只是为了选出一些语句来进一步肯定自己的世界观而阅读。)这在处理数据时也是真实存在的现象。观察表明,科学家更偏向于坚持过去的假设,有时在面临着对过去假设否定的压倒性的证据面前亦是如此(Jng 2006)。同样,股票投资获得收益的投资商会根据经验舒缓地释放神经素多巴胺,帮助他们对市场的行为做出决定(L和Repin 2002)。
我们暂时假定你既不是科学家也不是股票投资商,而只是一个渺小的调查员,对以下两个投资方案选项做出选择:
·选项A:100%收益7400美元
·选项B:75%可能收益10000美元,25%没有任何收益
这里没有什么技巧:你可以看到每种结果的期望效益。你会选择哪一种呢?
现在,给出以下两种选项,你又会选择哪一种呢?
·选项C:100%损失7400美元
·选项D:75%可能亏损10000美元,25%没有亏损
绝大多数人选择A和D。这里出现了不对称的情况:我们往往在下跌时更愿意冒险,而在上涨时则更保守。也就是说,稳赚比赚得更多但可能不赚更吸引人,但是当需要支付一定资金时,我们宁愿选择可能亏损更多可能不亏的情况。此外,这种投资组合并没有得到最大回报:如果我们只是投机性地考虑收益和损失,我们应该选择B+C的组合方式,因为其总期望收益是1000美元,而A+D组合方式的总期望收益是-1000美元(也就是说,比起A+D组合方式,B+C组合方式总期望收益高出2000美元)。
Daniel Kahneman和Amos Tversky在20世纪70年代首先做了该实验,它揭示了人们通常都不是以概率的方式思考问题:相反,我们想象和每一种单一收益相关的感情收益。
事实上,在很多重要的方面,我们并不是以自己所假定的方式来处理数据。
