什么是Deep Web
“Deep Web”(深网)指的是隐藏在HTML表单后的Web内容。为了获取这些内容,用户必须提交包含有效值的表单。例如图9-1的商店定位表单,搜索邮编为94043的商店,可以得到一个包含了商店列表的Web页面。该结果页面即为Deep Web的Web页面的一个例子。
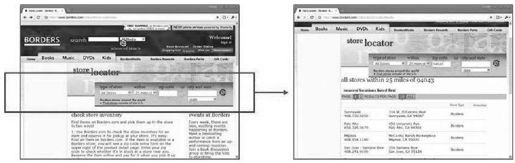
图 9-1:Borders商店定位表单和提交特定表单得到的Deep Web结果页(见彩图21)
Deep Web被公认为是搜索引擎在覆盖率上存在的一个很大空白。这是因为搜索引擎通过Web爬虫(cawler)来发现页面,并在索引中包含这些页面,从传统意义上来说,这些Web爬虫仅仅依赖于Web页面的超链接来发现新的Web内容。它们缺乏自动提交表单的能力,因此在表单后的Web页面无法被搜索引擎索引。包含表单的页面通常对表单后的页面内容包含很少;因此,对于普通的用户,只有当他们已经知道相应的HTML表单或者搜索引擎以某种方式将他们引导至该表单,这些用户才能够发现这些Deep Web内容。事实上,Deep Web(也称“不可见网络”(Ivisible Web)或者“暗网”(Hdden Web))的名字正是基于以下观察——Web用户无法通过搜索引擎简单地访问这些内容。
很多文章认为Deep Web拥有的数据比现在可搜索的WWW要多得多(Brgman 2001,He 2007,Raghavan 2001)。我们最近的研究(Mdhavan 2007)估计,存在几千万包含潜在有用的deep-web内容的HTML表单,而且Deep Web涵盖的范围跨越了每个可以想象的领域。这些流行的领域包括二手车销售、房地产清单、公寓租赁、求职、产品和食品食谱。有很多表单可以访问政府或者公共部门信息,比如法律法规、法院裁决、环境报告等。还有些表单可以让用户搜索更加深层的内容,如绿荫树、去公园的打车费、马雕像等。
当考虑Deep Web时,我们必须记住HTML表单适用于Web中的各种任务,但不是所有表单都可以访问deep-web内容。例如,要求输入用户名和密码的登录表单、提交用户输入到论坛和博客的反馈表单、执行购买的购物车等,这些表单需要获取用户的私有信息或者导致后台状态改变,因此不属于Deep Web的一部分。相反,我们主要考虑那些允许用户匿名搜索信息的表单。
由于deep-web内容的本质特征和数量规模,很自然地,搜索引擎会希望在它们的Web索引中包含这些内容。这样,搜索引擎才可以向用户展现这些新的内容,反之亦然。因此,无论在学术领域还是工业领域,人们对如何提供访问deep-web内容的问题都很感兴趣。但是,很大一部分的研究和技术将重点放在了如何在某些狭窄的领域来解决这个问题。这种做法最显著代表是垂直搜索引擎,每个都是专注于某个狭窄领域的内容。例如,二手车搜索和求职搜索网站允许用户从单一门户网站搜索很多底层的站点。这种策略虽然可以访问一部分Deep Web内容,但是其可达的范围非常有限,并且忽略了大量不适合于这些狭义领域的基于表单的网站。
我们的目标是为通用搜索引擎用户提供Deep Web访问方式。从搜索引擎的角度,我们希望包含很大规模的Deep Web内容,即能够访问尽可能多的上千万的HTML表单。因此,我们需要一个解决方案可以在所有可能的语言和领域工作,而且不需要人工监督,即一个完全自动化的策略。从deep-web站点主机(hst)角度考虑,该策略不应该过度使用站点宿主的资源;换句话说,该策略只应该驱动那些真正相关的用户流量到该网站。
在这一章,我们将概述一个满足上述标准的解决方案。该方案名称是探寻(srfacing),对于每个HTML表单,预计算一组查询,这组查询可能能够从深层站点中返回有用的内容。从每个预计算的查询中汇集URL,再把这些URL插入到搜索引擎的索引。从高层上看,我们的方法解决了两个挑战:一是在向一个表单提交查询时,决定需要填写哪些表单输入框;二是找到合适的值来填写这些输入框。在核心上,该方法依赖于通过智能选择的样本查询来探测HTML表单,然后分析检索到的Web页面的区别。该策略虽然简单优雅,却是非常高效的,而且可以有效地为Web搜索用户提供很大一部分Deep Web内容。我们的搜寻策略可以应用于Web中任何使用get方法(在本章后面会概述)的HTML表单。这主要是为了排除一些我们不希望爬虫去抓取的表单,比如需要用户信息的表单或者是产品购买结果表单,这些表单通常使用post方法。
我们的deep-web探寻系统已经部署到G公司的搜索引擎上。该系统成功地抓取了几百个领域下的数百万个站点。目前,在G公司的网站上,每秒有超过1000个的查询,在首页结果中能够看到一条来自Deep Web的搜寻结果。总体来说,搜索引擎用户发现这些结果和普通的搜索结果一样有用。关于该解决方案更详细的探讨和实验分析请参考(Mdhavan 2008)和(Mdhavan 2009)。
在本章的剩余部分,我们首先探讨访问deep-web站点的其他可选方案;其次描述思考该问题的概念模型;然后描述预测一个表单中有用的输入框(以及输入框组合)以及预测适合于这些输入框所需的合适值的策略;最后总结并评论我们在方案部署方面的经验。
