何时数据无法驱动
前面的内容指出了人们在分析数据时存在的一些认知偏见。本文的剩余部分讨论数据所不能做的,也就是说,其衡量和解释本身可以转换数据的各种方式。本文不是一篇关于“谎言、天杀的谎言和统计”的论文:我们知道数据可以被故意混淆;本文的重点是它如何会被无意混淆。特别是在如下情况:
·我们使用数据的方式不够准确
·我们采用已知的偏见方式处理数据
虽然以下例子重点研究医学和财务数据,但是它们或多或少可以扩展。“数据”用于表示任意从经验、观察和实验中积累的原始的事实。
数据并非越多越好
统计是一门表示和近似的科学。我们捕获或者观察一个系统越多,就越能真实地表示它。一篇入门性的文章往往会强调:随着你增加样本大小,置信区间就减少,而没有丧失任何置信度。换句话说,更多的数据可以帮助你控制误差边际(见图13-4)。
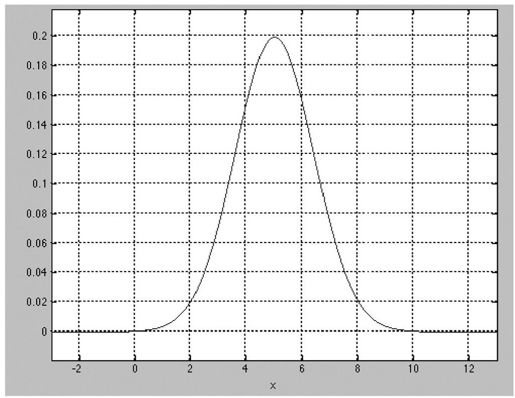
图 13-4:正态分布(见彩图49)
教科书上一个不错的真相。在游离世界外,需要审查一些假设。首先,数据是如何分布的?它是否是正态的?例如,很多财务数据的分布偏离常态。医学数据(例如,特征表达)通常更多的是呈高斯分布,但是演变并不总是符合中心极限定理。
如果数据不是正态分布,更多的数据将不会减少你期望的误差边际。Karl Popper描述了我们如何使用数据来回答问题上的偏态:
虽然无论有多少个与假设一致的结果都无法证明该假设是正确的,但是只要存在一个反面结果,就可以推翻该假设。更多的数据只是增加了必然性边际,而一个实例就可以推翻一个世纪的信仰。
其次,“误报率”(flse positive)和“漏报率”(flse negative)的代价相同吗?即使你的数据是(或者看起来)是正态分布的,你对不同结果的兴趣可能也是不对称的。
例如,无法检测到威胁生命的疾病的误差所付出的成本可能比错误的诊断更高。在这种情况下,(通过减少“漏报率”)提高诊断正确性的数据比通过大量数据来减少“误报率”更有用。
更多的数据并不容易
数据并不一定需要大规模。信息时代一个陈腐的“箴言”是:处理10TB的数据和处理10比特的数据一样简单,而制作100亿个向导小工具要比制作10个更昂贵。
在某些情况下,清洁和处理数据的代价不低。当需要人工肉眼校验,比如阅读X射线或者问卷上的手写编码数据时,尤其如此。依据“红桃皇后”(Rd Queen)效应[1],性能更好的计算机及其愈来愈强的收集数据的能力驱动了(而且被驱动)开发新的工具和采用新的方式来解析和使用数据。
也存在包含更多信息的认知成本。我们是选择超市的拥挤还是“401(k)条款”(401(k)plans)[2],研究表明随着选项的增加,决策需要花费的时间越来越多,我们变得更可能不做任何选择而直接放弃,而且对于自己做出的选择的满意度也降低了(Ienger和Lepper 2000)。
最后,一个微妙的成本是:更多的数据会使我们变得盲目而看不到其他的可能性,尤其当我们需要收集并整理数据时。很难想象,看到更多的数据意味着更好地支持一个假设——确认偏差和抽样问题的必然结果之前已经讨论过了。
数据不会自我解释
人们做出了种种解释。你可能已经听说,相关性(crrelation)和因果关系(cusality)是“聚头冤家”(srange bedfellows)。给定两个统计上密切相关的变量,因果关系既可以变大也可以变小。统计学家喜欢滥用相关性(更不用提很多博客了),比如对现代世界传统价值观的衰落有所不满的老太太。
记者是这种统计“不满”的首要主导因素。例如,《华尔街日报》最近的一篇文章指出(sellenbarger 2008),由于婚前同居离婚的概率更高,未婚夫妇为了提高婚后呆在一起的概率,应该避免婚前同居。该项研究没有任何迹象表示其中存在因果关系,而这个记者基于“数据”,给情侣们提供了她自己的建议。
用因果关系替代相关性不需要如此明显。当开展一项科学研究项目时,存在以下假设:如果发现事物间存在相关性,就意味着它们存在因果关系,否则其关系就是未知的。否则,为什么要去回答研究问题呢:大规模地搜索没有因果关系的相关性属于偶然性计算,不是科学。即使是所谓的大数据,科学依然是一个很强的由假设驱动的过程。
经验研究的局限不是有道理的服输,只是小心谨慎地推进研究发现,不受因果关系影响。基于数据创造故事是人之常情:研究是不断地修改故事,使它变得合理。
仅仅是答案的数据是不好的
描述性统计信息会隐藏细节信息。例如,图13-5的图表显示了看起来显著不同的四种分布,但其均值和方差却是相同的。描述性统计学的两大支柱——均值和方差——提供的关于分布的信息很少(Ascombe 1973)。

图 13-5:Anscombe的“四重奏”(qartet):每组数据集都有相同的均值和方差
当使用数据来制定决策时,我们倾向于认为数据分布只是为了最后的一个答案。我们可能需要基于二选一来制定决策——美国应该宣战吗?FDA(美国食品药品管理局)应该批准这种药物吗?预计谁会赢得竞选?(或者是做一个总结性陈述)美国人有多富有?在今后5年,地球的气候将会如何?——这些都是基于不确定性数据。即使报告了方差,重要的还是决策。
人们在思考时,考虑的是结果,而不是分布。以个人财务决策为例:我应该在股票、债券和现金上投资多少?即使过去的财务业绩可能预测将来的回报(即使财务顾问法律上需要承认这一点,事实上也并非如此)——也就是说,即使我们知道了分布的状态——我们还存在很多可选择的风险和回报组合,以及在这些分布范围内的很多可能的结果。给定一个风险水平,一个人退休时可能很富有也可能很贫穷,同时想象这几种情况很难(人们倾向于假设一个平均情况,或者有时是最佳的情况,即所谓的“规划性谬误”(panning fallacy))。
一个决策学科学家团队创建了一个有趣的工具来帮助投资者理解结果分布的固有的概率范围(见图13-6)。参与者可以调整100个“单位概率”来形成一条分布曲线。举个例子,他们可以把所有单位都放在75%的薪金的位置,或者把这些单位平均分发到很多不同的比例水平。然后,点击“开始”(g),观察这些单位一个个逐渐随机消失。最后留下的一项是“结果”(otcome)(Gldstein等2008)。因此,风险水平不是一条模糊的分布曲线,而是一组(这里是100个)具有相同发生概率的曲线。
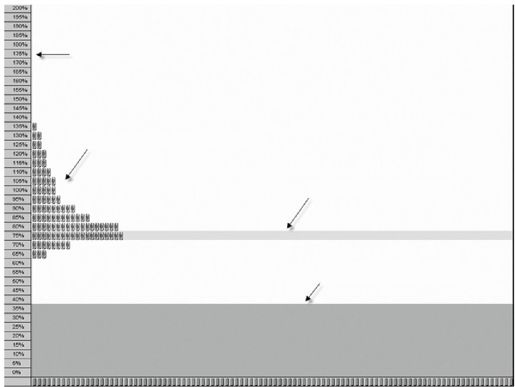
图 13-6:Goldstein等开发的工具帮助人们理解作为一组结果的分布(见彩图50)
生物学家Stephen Jay Gould通过和结果等同的描述统计进一步阐明了这个问题。“中间产物不是想要的信息”(Te Median is not the Message)是Gould对癌症诊断和“只能活8个月”的警告的反应。关于癌症的文章基于“预先定义的一组环境”揭示了向右偏分布——也就是在过去治疗情况的假设上,寿命很长的幸存者的一个很长的故事。声称“8个月”的生存期具有很大的局限性,正如Gould优雅地给出兽性的统计特征:
进化生物学家知道自然变异本身是唯一不可改变的本质。变异是残酷的现实,而不是对集中趋势的不完美的衡量尺度。均值和中位数是抽象化的。
数据不能预测
建立模型(来预测明天的天气,2012年超级杯的结果或者世界500强的命运)是一门很吸引人的艺术。事实上,科学最重要的探险——解释我们周围的世界的一个重要扩展,正试着去了解世界的未来。
在某些领域,即受控的物质世界宇宙,有可能预测几乎确定的结果。未来的结果可以高保真地从过去事件的发展轨迹中得出:水加热时会变成气体;物体在真空中会以每秒9.8米的加速度下降;如果动物的心脏停止跳动,它就死了。从认识论上看,Popper的“可否认性”(flsifiability)理论没有实际意义,但是如果之前三个假设是真实的,那么它可以引导出健全的社会生活。
在确定性较低的领域,比如人类或物理行为,模型是帮助解释模式的重要工具。但是,当我们过于渴望让数据说话时,可能会导致生成过拟合模型。
以发现多普勒径向速度为例(该过程我仅有表面简单的理解:基本上,明亮的星星使得查看行星变得很难,因此天文学家识别了多普勒变化的各种组合,它们只有在行星绕过恒星时才会出现)。很难检测模型的灵敏度,而且只有15个观察,其数据可能非常适合图13-7的正弦曲线(G等2004)!
当模型过拟合时,它就失去了预测能力。此外,如果我们喜欢接受任何最适合已有数据的模型,而不关心其复杂性或灵敏性,那么我们就会犯一些错误。首先,忘记数据的因果关系,对它有损害,过度调试的模型无法说明任何东西。
其次,我们忘记数据(或者数据集合)可能是有限的,而世界本身可以改变。以试图预测200年前的世界气候问题为例。存在一些关键证据,长期以来还保持很高的分辨率,即化石记录和冰核中的全球气温数据。气候学家还可以推断出当地气温和来自日记和树的年轮的沉淀,但是其精度水平差别悬殊:18世纪的暴风玻璃和20世纪带GPS的气象气球不同。而且,谁能够知道相同组合的交互在21世纪驱动的气候事件和20世纪会相同呢?
同样,1914年的福特汽车公司和1975年不一样,和今天的福特也不一样,但是很多金融模型假定市场的最后一个周期的动态性也将会解释其未来的业绩(而且,模型对要考虑的相对时间周期做出了非常不同的假设)。因此,风险分析模型可能在很多时候只是偏离(可接受程度)一点点,但是当发生“未预期”的情况时,它可能就会被完全打破(例如房地产市场崩溃)。
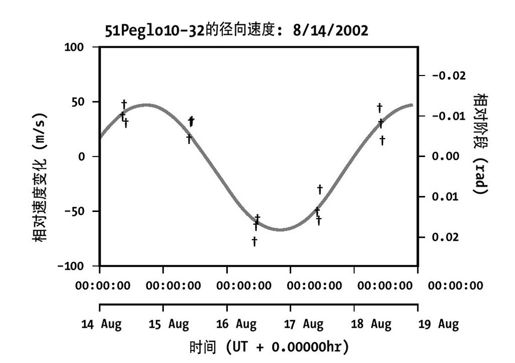
图 13-7:外星识别模型
好的科学家了解坏模型的危险,但是被一个看起来特别好的模型所“诱惑”也不难。举个例子,2005年报告的过拟合模型的一个单位的经验(它当时是正确的,但是事后看来,它还差得很远):
当一种新的模型方法大大提高了能量时,人们对它产生一定的怀疑是合适的。这种新方法通常是拟合数据收集的结果,而不是实际的底层行为关系。此外,这些问题在事后看来很显然,但是在我们当时有的数据清理过程中,并没有出现这些问题……最好的情况是,过度拟合会给新模型带来不必要的复杂性或者用户会诋毁该模型。最坏的情况是,它导致投资组合的风险评估的系统错误。
看看吧!
存在很多令人信服的理由来建立预测模型,包括探索场景和阐明假设;一个优秀的例子,参考Joshua Epstein 2008年发表的文章“为什么建模?”
概率不是直观的
这是构建统计时的另一个招人喜欢的“鞭笞”(fogging horse)策略,而且是出于善意的。统计学家不知疲倦地设计可爱的游戏,证明一个看似常识性的答案不正确的概率,而且条件概率和联合概率不是直观的。当数学家们和医生们被这些游戏愚弄时,这些统计学家便会格外高兴。
给定一个美国城市,100万居民当中大约有1000名(或0.1%)居民携带艾滋病毒阳性。一种新的艾滋病毒测试,包含1%的误诊率:每一百次中会有一次,它会将一个艾滋病毒阴性的人误诊为艾滋病毒携带者;反之亦然。
假设有人参加了测试,并被诊断携带艾滋病毒阳性。那么,他患有艾滋病毒的概率是多大呢?
很多人会回答说他患有艾滋病毒的概率是99%,因为测试的误诊率是1%。实际上,因为患有该疾病的人口比例非常小,任何人患有该疾病的概率,即使被诊断患有,也只有9.9%。(99.9万的艾滋病毒阴性的居民,有9990个会被诊断为携带艾滋病毒,而其中只有990个真正有艾滋病毒。对于结果是携带艾滋病毒的诊断,实际上真正有艾滋病毒的概率是990/9990或9.9%。)
医生给出的诊断错误率很高,至少是值得怀疑的。
在很多情况下,先验不会消失。当使用数据来回答问题时,我们不知道应该排除哪些证据,以及如何权衡哪些证据更重要。Daniel Kahneman——一个不知疲倦的概念命名者——把这种现象命名为“基准概率谬误”(bse rate fallacy)。
概率事件不是直观的
不但概率论很难把握,每个概率事件也很飘忽不定。当缺乏因果关系来把一个事件绑定到一组结果集上时,人们依赖过去的观察来估计概率。而且观察通常是以偏见方式收集的(尤其当通过经验囊括,而通过实验也很平常),并且很难记录、调试、加权、保存和查询。
真实世界并不创建随机变量
最开始,地球是没有形状的,而且没有东西。然后Fisher说:“让我们有z分数和变异数。”于是存在了z分数。Fisher看到回归很好,于是他把有意义的和无意义的区分开来。统计学的发明看起来是如此重大的创新,但是它们很难记住,因为它们不是自然规律。人可以想象另一个宇宙,那里设置了统计意义的标准阈值(被任意设置,正如在我们宇宙里)为p=0.01或p=0.06,而不是当前的p=0.05。想想那些已经被批准或拒绝的毒品、环境变量和健康影响之间的错误关联,你在汽车保险上花费的大量金钱!
在没有Fisherian的世界,不存在类似于独立随机变量的东西。实际上,很多东西关联度都很高。目前,实验控制相互依赖性是可能的,但是独立性就很难保证。正如我们最近所知,假设离散事件(如购房贷款人按揭拖欠)相互独立可能是错误的,但却有很多理论基于这种假设(如可交易的金融产品融入了贷款款项)不一定是错误的。
预测市场和群体决策制定过程能够非常出色地工作——在某些情况下,优于一组专家的估计。然而,当信息瀑布和相互依赖关系进入系统时,它们已经证明被打破了(Bkhchandani等1998)。
数据不是独立的
在现实世界的决策制定中,数据有很多种形式。信息很少会被清理并打包成一个格式良好的电子表格或“矩阵文件”(mtrix file);取而代之,我们通常需要基于主观以及量化信息来制定决策。
举个例子,是否制定在线把钱借给别人的决策(为了盈利,作为建立贷款市场的一部分)。我和同事使用一组来自于P2P(peer-to-peer)平台Prosper.com的35万贷款数据集,对资金借贷和偿还进行了分析,其结果表明不论有多少个模型(混合模型、神经网络、决策树和回归)能够预测谁能够获得贷款以及谁能够准时偿还的准确率只有75%。大量的数据——包括该网络的每个人有100多种个人财务健康指标——都可以根据现有算法来计算,但是哪个申请者可以获得资格以及哪个无法得到资助还是难以预测。通过量化主观特征,模型可以得到部分完善。当一个人决定是否把钱借给网络的某个成员时,出借人(和银行不同)考虑了很多“软”因素:借款人的目的声明、公司形象、拼写、语法以及其他个人资料信息。为了把其中一些特征纳入我们的模型,我们请人工(来自Amazon的Mechanical Turk)对Prosper.com网站的成员图像进行编码,首先是内容——该图像是否描述一个人、家庭、车等——然后是“诚信”评分:即该问题的答案,“你会借钱给这个人吗?”
但是模型仍然存在不足:社会因素对贷款的动态性有着意想不到的作用。和我们的假设相反,贷款给别人的决定不是独立的。而证据表明,竞标存在一些“羊群效应”:出借人学其他出借人,而且随着一个贷款上的竞标增加,单位时间的竞标也加速。
即使考虑这些情况以及其他的社会因素,很多出借人还是制定了次优的贷款决定。Proper网站在理论上是一个接近完美的市场:几乎所有的人都可以访问该站点的API,并重复我们的分析。但是出借人对于非常冒险的投资,还是只得到非常低的回报:给定统计的期望回报,很差的投资赌注的数量多得惊人。即使有可靠的信息(而且主观数据代理人谦逊温和),决策通常不是根据数据直接指定的,反过来,数据只能够从一定程度上解释人们的决策。
数据受到观察者的影响
最后,即使在可靠的因果关系是可能的情况下,如果数据是由Fisher和Bayes(如果该学生如此虔诚)的一个明智的学生老老实实地收集和建模,并由该学生负责改变并验证其模型(而且对模型结果仍然持怀疑态度),那么很多认知偏见会模糊人们的思考。在真实世界中,我们最好能够以概率性假设方式来操作。
正如统计学家常常在他们的博客上表示不满,行为经济学家在各自的编年史上都臭名昭著。如之前提到的叙述性谬误、确定偏见、选择悖论、冒险、基础概率谬误以及夸张的贴现。心理学家已经索引了很多其他的,包括从“锚定”(过度依赖于最近单点数据来制定决策)到“Lake Wobegon效应”(超出一半的人认为他们高于平均水平)。
随着这些影响被更好地记录,我们可以开发工具并利用直觉来帮助采用数据的票面价值(我的一部分工作重点为金融决策开发工具)。从某种意义上来说,解决办法很简单:如果你不理解数据的局限性,那么数据并没有太多价值。
[1]Lewis Carroll的《爱丽丝梦游仙境》中的“红桃皇后”说“为了呆在原地,你需要尽力奔跑”。该思想被用于描述一个系统,由于外部压力的竞争,必须不断地和竞争者共同演化发展。
[2]401(k)条款指的是20世纪80年代初制定的美国《国内税收法》的第401条第k项条款,是由雇员和雇主共同缴费建立起来的养老保险制度。
