预处理数据
我们从头开始:像很多网站一样,FaceStat运行在一个SQL数据库上。评判界面记录用户的评论并把它们作为一个三元组(fce ID,attribute,judgment)保存起来。我们做的第一件事是从数据库中抽取1000万条记录。它生成一个如下的文件:
face_id key value 149777 describe serious 18717 trustworthy 3 140467 attractive 2 149777 describe five-head ……
我们对探索不同类型的感知属性之间的关系感兴趣。一个有趣的问题是“我看起来多大了?”第一件要做的事是看人们给出的回复。Unix命令行工具使得快速查看人们的回复直方图变得非常简单。最常见的回复看起来是合理的年龄,但是我们也发现了一个问题:
Look at$cat data.tsv| age judgments'grep"age"| values cut-f3| and count how many times sort| each value occurs,uniq-c| and order by this count.sort-nr
以下是这个shell管道的输出。对于每一行,第一个数字是频率计数。第二个字符串是回复值——是人们针对问题“我看起来多大了?”在Web表单中输入的回复。经常出现的情况是用户输入了一个数字,但是有时存在一些问题:
7047219 7002122 6938718 6842317 …… 2724\r\n 2717\r\n 2301 2116\r\n …… 1 old enough to know better 1 hopefully over 21 1 e 1?? ……
FaceStat已经运行了8个月,而且经历了很多变化,因此数据是在不同的情况下收集的。一些奇怪的网页浏览器会增加行结束空白符\r\n。有时存在bug,用户输入文本形式的回复以及一些其他格式有问题的数据。看看在sort|uniq-c|sort-nr之后,直方图的最底部的数据值,就可以很容易地暴露出数据上存在的bug,因为它们通常会展现为游离点。我们需要写一些正则表达式,它可以清除这类格式有问题的值。
详细描述所有的数据合理性检查和数据清除会显得很繁琐,但是它们是任何数据分析重要的第一步。对于任何人工生成的数据集,必定存在一些杂乱的游离点。比如,有人发现了如何绕过选择哪张脸来评论的随机性,把一张脸标注了100多次“mr.cool”。
除了清除之外,对于该特定数据集的一些重要的决策是:1)如何把多选的回复如“很值得信任”和“不值得信任”映射为一个数值;2)如何把很多人对一张脸的很多回复聚集成一个描述。每张脸在一些不同属性上有大约几百个评价。我们将简单地对数值评价求平均值。(在这种规范下,我们忽略文本描述,在后面会提到。)因此,每张脸包含感觉上的年龄、智商等因素的均值。它看起来如表17-1所示。
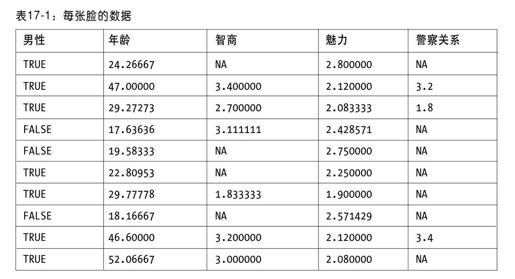
总而言之,有成千上万的脸,包含20多种不同的属性。有很多缺失值:询问不同的人不同的问题。有了这些警告,我们可以把数据加载到某个包里进行更详细的分析。如果你想深入了解,我们已经生成了数据子集,在http://data.doloreslabs.com可以获取有用的代码。
