聚类
数据中的人们有哪些典型类型?聚类是找到这种模式的强大的统计方法。聚类算法通过将相似的实例分组在一起,从而把数据点分成几种特征类。聚类有很多方法,但是最流行和简单的方法称为K均值聚类(K-means)方法。在K均值聚类方法中,每个聚合有一个中心点,称为“质心”(cntroid)。在数据中找到一些不同的质心,每个数据点被分配给一个质心。该算法迭代调整聚合,这样使得尽可能多的数据点靠近分配给它们的质心。
在我们的数据集中,每张脸大约有20个数值属性。因此,脸部就是在20维空间的点。K均值聚类方法会把脸孔放到该空间的不同的聚合,试着选择聚合,使得脸孔可以尽可能地和它们所在的聚合的中央相似。
K均值聚类算法不好的一点是你必须选定固定值的聚合个数——“K”。然而,不存在很明显的方式来选择聚合的个数。需要做的最好的事是尝试集中不同的个数,查看出现了什么模式。以下是运行K均值分类算法的一个合理输出:
Preprocess the data,>norm_data=apply(d,2,function(x){ by changing missing values to the mean,x[is.na(x)]=mean(x,na.rm=TRUE) and unit-normalizing values,x=(x-mean(x))/sd(x) which usually makes k-means work better.x}) Then run k-means for 5 clusters,>clus=kmeans(norm_data,5) and plot attractiveness vs.age,>plot(d$age,d$attractive, but color by col=c("red","purple","blue","orange", cluster assignment,"green","darkturquoise")[clus$cluster], and have fun with unicode.pch=ifelse(d$male,'\u2642','\u2640'))
散点图的点表示脸部,点的颜色和它们被分配的聚合一致。我们将显示在魅力和年龄空间内的脸庞,如我们之前的绘图一样。一些聚合已经可以理解:橙色聚合表示年长的人,紫色看起来是有魅力的年轻人等。
这个绘图只显示数据的二维或者三维,因此没有充分地总结聚类算法,聚类算法完整地比较了20维空间的人脸。这是一些聚类重叠(oerlap)的原因:举个例子,红色和绿色看起来有非常相似的年龄和魅力范围。这些聚合必须通过其他属性区分。
我们通过各种方式来分别查看各个聚合。首先,我们显示聚合的属性权重。它是聚合的质心点的位置,质心点通常被认为是该聚合表示人脸的典型属性。因此,如果你查看图17-13的每个集群的平均点,它会返回年龄和魅力的聚合权重。(我们将显示八个属性;其他属性不重要,因为它们包含太多的缺失值。)其次,我们显示了在该集群中的人脸的最显著的10个特征,通过如之前的性别分析那样的条件概率进行排序。
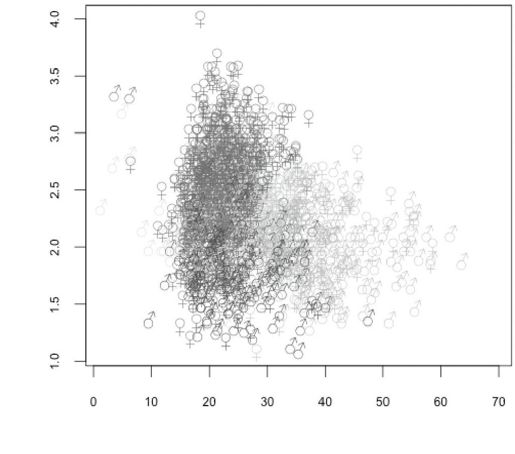
图 17-13:魅力和年龄的关系,通过集群着色,显示了包含2000个点的子样本(见彩图65)
首先,图17-14显示的是紫色集群。这是一个非常女性化、具有高度魅力值的集群。标签很有趣。它们和属性惊人的相似;事实上,如果覆盖左侧图,你很可能猜出该组的很多属性。标签显示了一致生动的画面——即使我们的k均值聚类算法完全忽略了这个信息!这说明了标签和社会属性有内在的联系。(这一点可能不足为怪。)

图 17-14:集群2
我们在图17-15和图17-16展示了所有集群,包括每个集群中四个最有代表性的脸孔(表示最接近质心点的)。
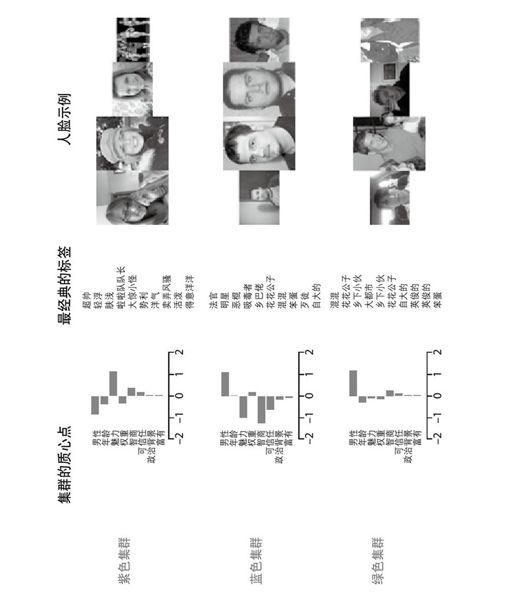
图 17-15:集群的质心点、标签和例子(见彩图66)
有些集群有直接的解释,而另一些则不是很清晰:
紫色集群
年轻、有魅力的女性。
蓝色集群
丑陋、智商低的男人(“失败者”?)。
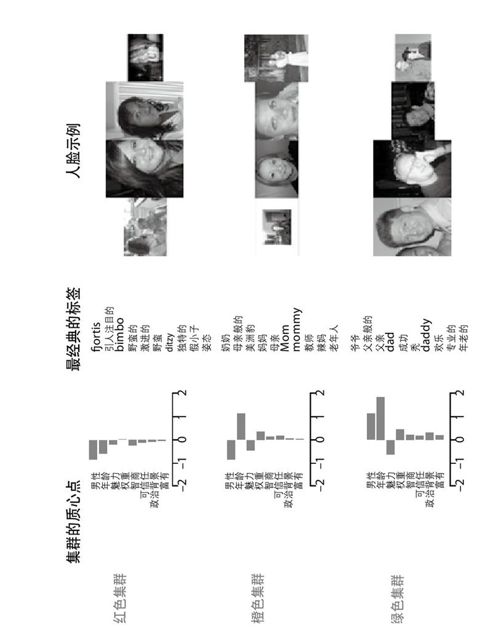
图 17-16:集群的质心点、标签和例子(见彩图67)
绿色集群
其他更普通的年轻男人。它的很多标签对于蓝色集群也非常有可能。
红色集群
其他年女性。
橙色集群
较年老的女性。
青绿色集群
较年老的男性。
聚类一方面用于发现数据高纬度的模式或者分组会很有用,因为这些模式和分组无法通过两个维度进行可视化。另一方面,很难验证聚类是否告诉你一些“真实”的东西。存在很多聚类算法和很多参数调整(比如k),不同的调整会生成不同的结果。这项工作是否有用?
集群看起来似乎相当一致,而且对于很多模式具有提示作用。观看那些生动的标签集合互相关联很有趣。而k均值聚类算法可能可以模拟我们的大脑中对人类特征的思考。从质心点和标签集合,我们可以想象表示每个集群的典型的人类特征。
