复杂查询
随着Web应用更加复杂有趣,这些应用需要以新的不同方式从数据库中检索和组合信息。下一步,我们将探索如何在大规模系统上支持这些查询。
面临挑战
系统对只需要一条或者几条记录的查询做了优化。尤其是,系统可以通过主键来查询记录;只要知道Alice的用户名,就可以直接确定哪个分区包含她的信息记录,加载页面时读取该记录。另外,系统可以采用散列分区表或范围分区表来存储数据。对于范围分区表,可以通过主键的排序范围做范围扫描。例如,系统可能以每个连接一条记录的方式存储Alice的好友列表,其中每个连接的主键是Alice和她好友的用户ID对(见表4-7)。
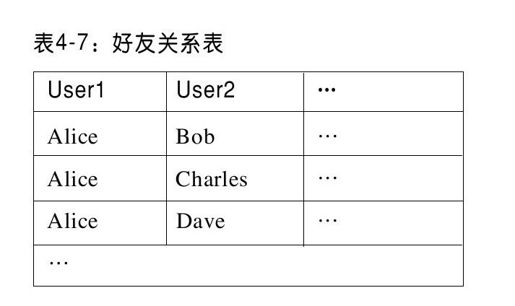
对于范围分区表,所有以“Alice”为前缀的记录会聚集在一起,因此,只需要小范围扫描就可以检索到这些相关记录。
现在假设我们需要给社交网络站点添加另一个功能。在该站点中,用户可以发布照片,对其他人的照片发表评论。Alice可能想对Bob、Charles和Dave的照片发表评论。当页面显示一张照片,我们希望它也能够显示和该照片相关的一组用户评论,同时还想为Alice显示她对其他人的照片做出的一组评论。评论表的主键设定为(PotoID,CommentID),并以有序的YDOT表的方式存储(见表4-8),因此对相同照片的所有评论会聚集在一起,可以通过范围查询来检索。
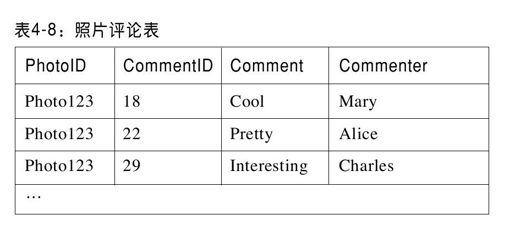
系统如何收集Alice做出的所有评论?它需要对Alice的信息记录(以username为主键)和评论记录(以username做外键)做连接查询。由于向外扩展的系统架构,数据分区跨越很多服务器,因此连接操作需要访问很多服务器。该操作一方面需要连接多台服务器,另一方面一条查询占用大量的服务器资源(导致其他的请求响应变慢),因此代价很高,增加了请求延迟。
在向外扩展的系统中,另一种代价高的操作是聚集(goup-by-aggregate)查询。假定用户指定了爱好,系统想要计算每种爱好的用户数,从而可以向Alice展示哪种爱好是最受欢迎的。这种查询需要扫描所有的数据并保存计数值。这种表扫描操作会给系统带来巨大的负荷,而且不能够同步执行,因此Alice的页面需要非常长的时间才能加载。
这些例子说明了虽然单点查询和范围扫描可以快速执行,但是代价更高的连接和聚集查询操作不能够同步执行。
我们的方法
处理代价高的操作,核心原则是异步执行,但是代价高的查询实际上不能够以这种方式处理;我们不希望需要Alice不断返回检查获取其所有评论的异步查询是否已经执行完成。
实例化视图可以通过异步式构建(Aarawal等2009),当Alice登录时,她可以快速(同步)地查询该视图[1]。虽然和基本表的数据相比,异步式构建的视图可能已经过期,但由于应用本来就需要处理过期的副本,所以处理过期的视图数据通常是可以接受的。事实上,我们把实例化视图作为一种特殊的副本,该副本可以复制数据和转换数据。通过与更新副本相同的机制来更新视图,系统保证了视图和复制的基本表数据,有相似的可靠性和一致性保证,而不需要再设计和实现另一个机制。
虽然视图是在后台维护,但是我们还是希望尽量减少它的代价。如果维护视图占用很多系统资源,或者它会影响同步的读写请求(增加每个查询的延迟),或者会被分配很少的资源,运行很慢,这样视图数据会严重过期而导致视图可能毫无用处。因此,我们必须探索使视图维护高效的策略。比如对于先例,系统想给Alice显示她对其他人的照片做出的所有评论。系统将创建一个实例化视图,该视图通过外键(评论员的username)而不是主键对评论数据进行重组聚合。那么,Alice做出的所有评论会聚合在一起,我们还可以给视图添加Alice的信息记录,以她的username为主键,因此Alice的信息和评论可以聚合在一起。主键/外键连接操作如同扫描并连接以“Alice”为前缀的视图记录一样简单。结果如表4-9所示。
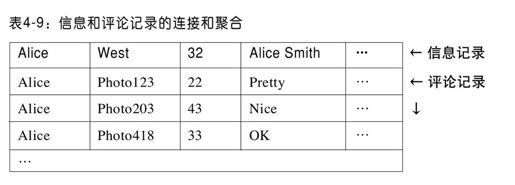
注意,我们并没有在视图中做信息和评论记录的预连接操作,只是通过定位需要连接的记录,使得连接的维护代价低。当需要对基本表记录做更新操作时,我们只需要更新一条视图记录,即使该视图将和很多其他记录做连接操作。
我们如何在同一个表存储信息和评论记录?在传统的数据库,因为两种记录有不同的模式(shema),所以这样会很难存储。但是,PNUTS的一个核心特征是能够表示灵活的数据库模式。相同表中不同的记录可以有不同的属性组。这个特性对于Web应用特别有用,因为Web数据通常稀疏松散,一个销售商品的数据库根据商品的种类,会有不同的属性(如color、weight、RAM和flavor)。灵活的数据模式对于实现实例化视图连接也是非常重要的,这样我们可以定位来自不同表的连接记录。
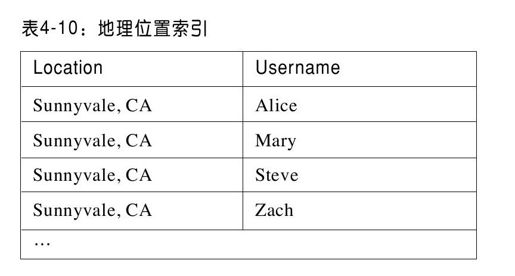
异步式视图方法也有助于响应其他类型的查询。聚集查询可以通过实例化视图预先分组(pe-group),甚至可以预先聚合(pe-ag gregate)数据,因此可以有效地响应查询。甚至有诸如选择非主键属性的“简单”查询,这种查询通过实例化视图方式处理最有效。假设需要查询住在加州Sunnyvale的所有用户。因为用户表的主键是username,该查询通常需要执行代价高的表扫描操作。但是,我们可以采用实例化视图在用户表的“location”域构建索引,把该索引存储到有序的YDOT表,然后在“Sunnyvale,California”的索引记录上执行范围扫描来获取结果,从而响应查询请求(见表4-10)。
如其他系统中的实例化视图,只要我们事先知道需要什么查询,就可以有效地创建视图。对于提供Web服务的应用,查询通常是根据事先确定的模板,在运行时指定参数(如地理位置或用户名)。因此,应用开发者可以预先知道哪些查询很复杂,需要实例化视图。为了即时请求存储在PNUTS中的数据,开发者需要使用PNUTS插件从系统中获取数据,并把数据保存到运行着Hadoop的计算网格。Hadoop是MapReduce的开源实现。当有一些不同的机制来处理复杂的查询,实现有助于有效执行查询的查询计划器是非常有用的。查询计划器可以减轻应用开发者的负担,它可以写声明性查询(dclarative queries),而不需要考虑这些查询将如何执行。但是,对于如PNUTS的大规模系统,有效的查询计划器需要复杂的统计收集、负载监测、网络监测和一系列其他机制来保证查询计划器对于系统的所有可能瓶颈有足够的信息来制定最有效的查询计划。
[1]在PNUTS系统的生产版本中,还不包含实例化视图。
