解决棘手问题
奥克兰的CrimeWatch是一个提供犯罪报告信息的应用,以图片的形式提供犯罪报告相关的原始制图和卡通式的图标。CrimeWatch为便于数据展示进行了专门优化,而且侧重于预测用户需求而不是提供原始材料。应用的用户体验是通过“向导小工具”(Wzard)来通知的,它是一个用户界面,提供给用户一系列的对话框,它们生成了一系列的步骤,通过特定的序列执行任务。CrimeWatch应用的必要步骤如下:
1.事件:选择事件的类型(一种或者多种);
2.地点:在地址附近搜索,在可管理的范围内;或者是某个特征附近,如学校或者公园;
3.时间:在多长的时间范围内进行搜索。
CrimeWatch通过静态图片来响应,该图片以图表的形式显示各个报告。
点击这些图标可以获取更多的信息。第一次激发了对CrimeWatch的兴趣是在我开始思考某种方式用来颠倒服务端完成归并过程;从静态的图片开始,通过附加的地理信息来抽取犯罪报告信息:使用和那些其他地理软件系统兼容的经纬度值,通常被称为地理定位(golocation)。这种简单的识别问题很容易理解,而且在视觉特征抽取方面已经存在着很好的技术。
首先,我们需要获取一张图片进行处理。这过程实际上比看起来要复杂得多,我们必须跳过一系列的“钩子”(hok),“说服”服务器生成一张犯罪报告图片。CrimeWatch在服务器端保存了会话状态,因此有必要通过一个假的虚拟用户来模拟一套完整的向导互动模式:通过表单接受服务条款,然后通过交互向导继续完成各个步骤,在这些过程中保存HTTP Cookies和令牌(Tken),然后对非标准的HTTP重定向进行正确地响应。重构这些步骤过程,从而生成有用的犯罪报告图像是该项目面临的第一个难题。幸运的是,客户端的HTTP代理软件Charles(http://charlesproxy.com/)和Mozilla插件LiveHTTPHeaders(http://livehttpheaders.mozdev.org/)简化了这种重构过程。解释中间HTML页面本身是通过使用网页刮屏(pge-scraping)库的方法,如Leonard Richardson的BeautifulSoup库(htp://www.crummy.com/software/BeautifulSoup/)。BeautifulSoup库是为了使通常看到的HTML“标签”变得有意义,纠正了某些通用的问题如不正确的嵌入式标签或者部分标记,而且它允许我们读取HTML表格和JavaScript脚本命令,这些构成了一个完整的客户/服务器会话。
可以使用简单的Unix命令行工具如Shell脚本和网页访问工具cURL(http://curl.netmirror.org/)来模拟第1版的刮屏过程。其关键是仔细检查浏览器和服务器之间的HTTP连接,寻找暴露出来的信息可以帮助重新构建交互。查看URL中包含的CGI变量和Post方式请求体是重构的第一步,它可以准确地表示接受了使用条件后的初始的会话连接。基于会话的应用如CrimeWatch大量地使用了Cookie来保存客户端的状态,因此,利用HTTP库把Cookie打成Jar包是必需的。CrimeWatch还大量依赖于客户端的JavaScript框架,而不仅仅是简单的表单提交;此外,它还使用了额外的状态变量,这样中间响应页面必须通过HTML解析器和正则表达式才能够搜索隐藏在页面脚本中的详细信息。最后,由于很多这种老一代的Web应用是在跨浏览器的动态HTML被开发者普遍应用之前出现的,因此“欺骗”User-Agent头数据,假装是IE浏览器或者Mozilla火狐浏览器绕过User-Agent头数据通常是必要的;其他浏览器会显示不兼容报警信息,不返回任何数据。
在这个过程结束时,只剩下中等大小的图片位图,期望能够包含可识别的犯罪报告图标。通过第一轮抽取每个图标的像素位置很简单,但是过程很慢;对于图像中的每个可能的位置,把它的像素颜色和已知的图标做比较,一旦差异小于某个给定的阈值,就显示正的匹配度值。因为我们是在噪音相对较少的后台来处理预先指定的图标,这实际上是一种完全的“防弹”方法。CrimeWatch中使用的犯罪图标是独一无二的,而且即使部分被其他图标或者图片特征所屏蔽,但是还是可以很容易识别出来。我采用的检测这些图片的工具是NumPy(http://numpy.scipy.org/),它是一个久经考验、功能强大的Python数组操作库。图11-2和图11-3显示了CrimeWatch的部分样本图片,突出显示了程序可识别的图标。
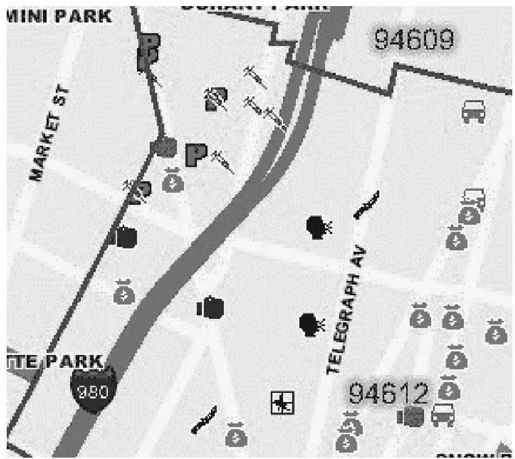
图 11-2:CrimeWatch的样本数据显示了盗窃、毒品、抢劫、盗窃车辆等犯罪活动(见彩图29)
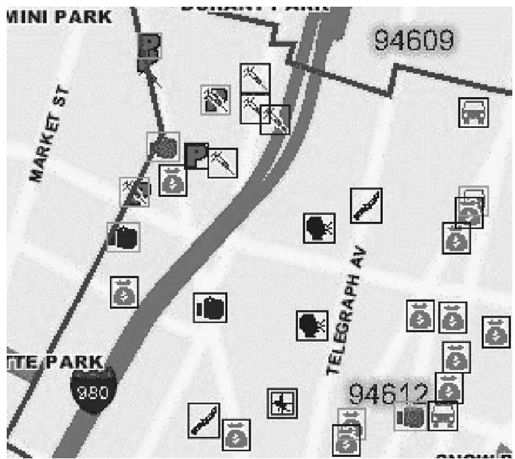
图 11-3:CrimeWatch相同的样本数据,突出显示了程序可识别的图标(见彩图30)
遗憾的是,蛮力方法在普通的CPU上很慢,但是通过对所需处理的各种地图的一些简单分析,也许可以对其速度进行一些优化。例如,很多犯罪报告图标有很显著的特征颜色:通常货币形状的绿色袋子表示盗窃,蓝色拳击手套表示普通伤害。一种简单的预处理步骤是通过代价较低的图片扫描来找到与其中一个期望的颜色接近的像素的位置,这种方式可以极大地降低代价高的全图标匹配的位置数目。图11-4用白色正好显示了图11-2的红色部分,它表示严重伤害可能发生的场所,可以看到有红色的拳击手套。

图 11-4:CrimeWatch的相同的样本图片,红色的部分用白色显示是为了更清晰地突出红色的拳击手套图标(表示严重伤害)
一个较为复杂的预处理步骤是通过一系列的扫描来搜索临近的几种特征图标颜色。例如,盗窃是通过黑白相间的破碎的玻璃小图标来显示的。一张经典的地图上包含很多的黑色和白色,但只有图标和文本会黑白相间。我们会找到所有和这两种颜色很相近的像素,并把高代价的搜索区域降低限制为只包含有限的候选像素。
每次犯罪报告的地理定位过程都需要根据在渲染地图中检测到的像素位置来确定位置。为了实现这一点,对于给定的一组输入,CrimeWatch总是返回可预测大小和位置的地图是有帮助的。例如,3号警务服务区域(Plice Service Area)的地图需要总是覆盖相同的区域,而不用考虑当时实际的犯罪报告是集中于区域的某个角落还是扩散到所有地方。CrimeWatch提供的地图包含的底层地理特征如街道或海岸线,总是在相同的地方。对于每一种可能的地理布局方式,需要人工定位三个大间距的已知参照点。道路交叉口对于这点非常合适,因为在CrimeWatch上可以很容易地定位它们的(x,y)像素坐标,而且通过Simon Willison的GetLatLon应用(htp://getlatlon.com),也可以很容易地定位道路交叉口的地理位置(经纬度)。给奥克兰的6个警务服务区添加三个参照点相当于手工创建了18个已知的地理定位。该步骤只需要做一次:在每个服务区,所有能在地图上找到的图标,都可以利用简单的线性算法,通过和已知的参照点比较,计算出它们的地理位置。图11-5显示了商业区邮政编码的地图,它包含选定的三个地理参照点。定位了这三个点之后,就可以三角测量地图上的任何其他点的地理位置。
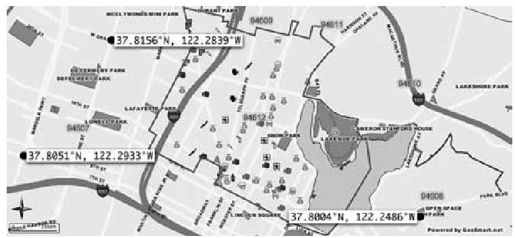
图 11-5:奥克兰商业区地图,为三角测量所显示的三个参照点(见彩图31)
唯一剩下的一件事就是模拟用户点击每个犯罪图标,收集关于犯罪报告的进一步详细信息,比如案例编号、每天的日期和时间以及简单的文本描述。其生成的最终产品是每天包含大约100个报告的数据库。该步骤面临的一个挑战是确定一个独特报告是由哪些构成的。我采用移动窗口来收集报告,这意味着每个报告都会被收集多次,而多个独立的报告可以通过警察局提供的唯一案例编号覆盖成一个。最后,我们使用了一组案例编号和文本描述,它们足够覆盖数据收集中绝大部分的不一致性。
实现上述功能的代码运行于事件驱动的网络引擎Twisted Python(http://www.twistedmatrix.com/)上。采用这种引擎使得打开并保持一个长时间持续运行、使用CrimeWatch提供服务的模拟浏览器的会话变成可能。有了这些代码库,可以把脆弱的程序转变成每天晚上连续运行和收集数据的应用程序,而且结果数据也可以以表单方式公开展示。我们相信对于奥克兰市的居民而言,表单方式显示要比采用CrimeWatch显示显得更为友好。
晚上收集这些数据为最初8个月的收集和实验奠定了基础。每天晚上,我们会在13种类型的犯罪和6个警务服务区的全部组合上运行一个网页刮屏工具(Pge Scraper)。由于CrimeWatch的一次性设计,每个个人报告需要有它自己的请求/响应循环。我们还为每个步骤增加了很多延迟——在这个过程中,每两个步骤之间高达一分钟或者更多的延迟——因此不会由于过多的请求而使CrimeWatch服务器负载过高。在午夜之后,将会启动单一进程运行,而且该程序通常可以持续6个小时或者更多。
一般来说,错误还是时常发生。CrimeWatch服务程序常常会变得非常“不理智”,勉强生成一个没有空间、时间或类型约束的地图,比如奥克兰过去三个月所有地区的所有犯罪。我们没有可靠的方式来检测这种情况,而且我们的数据库所报告的地理位置经常错乱。
在这个案例中,我们觉得偶尔的错误报告只是为了改进数据库浏览工具而付出的很小的代价。在2007年前半年,我们继续收集数据,通过可视化表示或者出版发表技术,周期性地发布一些小的实验。
