可视化和社会数据分析
可视化通常用于构建数据的涵义来帮助理解这些数据,探索这些数据并交流结果发现。为了处理可视化信息,人类神经系统的很大一部分已经得到进化,在人类大脑中,超过70%的神经末梢和40%的皮质在视觉处理中相互关联(Wre 2004)。可视化设计充分利用了这种视觉处理系统的能力,使人们可以更容易理解并发现蕴藏于数据中的趋势、模式和异常信息。
需要注意的是,这不是手工制作一个“花哨的图形”的问题。通常,一个简单的表格或条形图(sns 3D虚饰frills和镜面高光)能提供很好的演示效果。这其中的特技在于为现有的数据和任务选择合适的视觉展现形式。
一个富有启发性的例子是Anscombe的“四重检测”(Qartet),它采用由统计学家Francis Anscombe收集的四类数据集来说明数据可视化的重要性(Ascombe 1973)。使用通用的统计学描述方式,这四类数据集看起来似乎完全一样(见图12-1)。但是,对这些数据的绘图展示就可以马上揭示出这些数据集之间的差异。
还有其他作家详细地描述了有效的视觉设计是如何辅助人们理解、沟通和制定决策。Tufte(1997)提出了著名的论断,如果当时工程师创造了更好的对火箭缺陷数据的视觉描述,挑战者号航天飞机的灾难可能可以避免(虽然该论断也饱受争议,见Robison等2002)。
可视化研究人员列出了“视觉变量”(vsual variables)的空间(如位置、长度、面积、形状和色彩)这些变量可以用于在可视化显示中对数据编码(Brtin 1967,Cart等1999)。他们还研究了当这些视觉变量应用于不同类型的数据,如范围的(名字)、顺序的(基于排序有序的)和定量的(数值的)数据时,人们对其解码可以达到的精确程度。举个例子,如在条形栏或散点图中所使用的空间位置,有助于对这些数据的每一种类型进行解码;当采用色彩对不同的标签进行分类时,它的区分度很高,而用于描述数值时,它的区分度则很低。
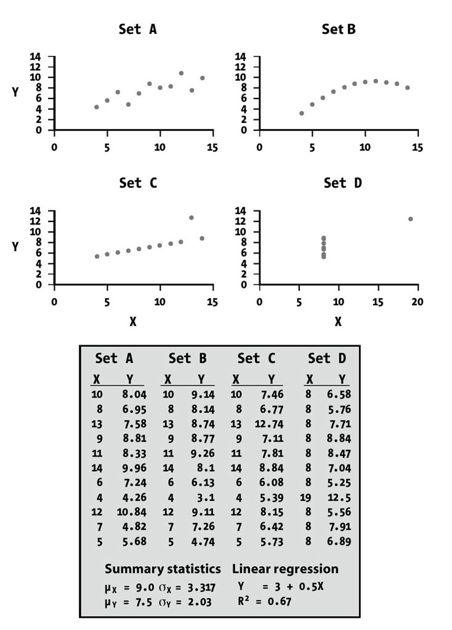
图 12-1:Anscombe的“四重检测”(Qartet),包含统计学上相似的数据集来说明如何利用可视化帮助人们理解
本着这种思想,绝大多数可视化集中于研究可视化应用的感性和认知方面,通常是在单用户交互系统的上下文中。然而,在实践中,可视化分析通常是一个社会过程。人们可能对于如何理解数据有不同的见解,可能会提供上下文知识来帮助加深理解。由于参与者达成共识,他们可以从同龄中互相学习。此外,有些数据集很大,由一个人完全深入探索是不可能的。这意味着为了全面支持有意义的决策(snsemaking),可视化应该也支持社会交互。
基于这些观点,我和同事Martin Watternberg以及IBM研究院的Fernanda Viégas开始调查用于可视化数据的用户界面如何可以更好地促进“可视化的社交生活”。我们开始启动研究项目,设计和实现网站sense.us,致力于形成人口统计数据的团体探索。该网站提供了一套美国过去150年的人口统计数据的可视化的解决方案,以及促进面向团体的数据分析的协作机制。
在本章的剩余部分,我将分享sense.us网站的设计过程,包括:我们如何选择和处理数据,开发一套可视化方案,并设计协作特征来促进社交数据分析。最后,观察人们如何通过该系统协作构建数据。
