数据
Martin、Fernanda和我以研究人员的心态开始做这个项目:我们希望能够理解在可视化分析过程中,应该如何最好地支持社会交互。我们对数据集的选择不是预先确定的。但是,很显然,好的数据领域的数据集将会满足某些特定的属性:我们想要大规模的、真实世界的数据集,它们和普通的大众相关,而且数据丰富,可以保证很多不同的分析。根据这些标准,人口普查统计的数据看起来很理想。我还一直对促使人口统计数据更公开、可访问感兴趣:我相信这是重要的一个方面,通过它我们可以更好地理解自己和历史。
我通过美国人口普查局的网站(htp://www.census.gov)开始搜索数据。事实证明,这种方式收效甚微。人口普查局在各种聚集层次提供了很多不同维度的数据集(如通过邮政编码、都市区域),但是只在最近几年人口普查才有丰富的数据。我还意识到自己在该网站搜索数据时不够集中深入。人口普查数据在过去几十年如何收集和建模的来龙去脉,还亟待进一步了解。例如,人口普查局在收集数据过程中使用的问题以及涉及的范围在过去几十年在不断变化,意味着即使该网站包含某个人每年的数据,它也并不能保证这些数据能够很容易具有比较性。
一般情况下,人们在对某个数据领域有了最基本的熟练程度之前,不应该一下子扎进可视化设计。因此,我的下一个步骤是访问各个领域的专家们:加州大学伯克利分校的社会学和人口学部门的同事,那时我是该部门的研究生。通过和他们的讨论,我对人口普查是如何工作以及人口学家使用哪些数据源研究人口有了更深的理解。在这个过程中,有人为我介绍了一个宝贵的资源:由明尼苏达大学人口中心(htp://www.ipums.org)维护的综合公用微观数据序列(Itegrated Public Use Microdata Series,IPUMS)数据库。IPUMS-USA数据库包含了1850~2000年的美国人口普查数据。其普查周期是10年,只有1890年例外,没有普查数据;在1921年这些数据记录在商业大厦(Cmmerce Building)被大火摧毁。IPUMS数据包含了每10年的代表性样本数据,占这10年的人口普查记录的总样本数据的1%或5%。每条记录代表人口样本的某个特征人物。在某些情况下,有某些特征的人物和家庭被多次代表,因而记录需要和不同的权值关联。
IPUMS-USA数据库特别吸引人之处在于IPUMS项目为所有的人口统计学变量开发了统一的代码和文档,这有助于随着时间分析变化。这种“和谐化”是一种宝贵的服务,使得能够进行比较性分析,而且通过扩展,可以获取一些新的洞察。然而,把分离的数据应用于共享模式的过程不可避免地引入了人工干预,该问题在后面还会出现。
诚如之前所述,IPUMS-USA数据库包含413个人口统计学变量,其涉及的范围从普通的领域如性别、年龄、种族、婚姻状态和职业,直到多少家庭包含洗衣机、烘干机、抽水马桶和电视(见图12-2)。在很多情况下,一些变量只在某几年有数据记录,而在其他年份,这些变量完全没有被测量。
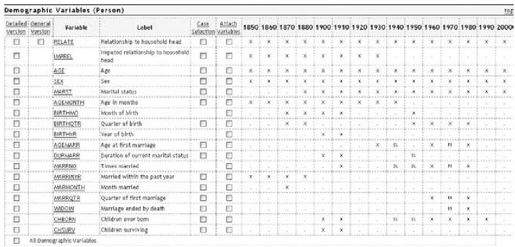
图 12-2:在IPUMS-USA数据库中可访问的人口统计学变量的摘要
IPUMS项目的宗旨是“只用它从善,不作恶”(ue it for good,never for evil)。幸运的是,在实施该箴言的过程中,超出了人们在下载数据摘要时必须点击的复选框。为了保护个人隐私,有些数据的可访问性受到了限制。举个例子,不包含宗教从属关系,而且详细的人口统计数据的可访问性也受到很大限制,尤其是对于人口密度低的地区。
我们决定采用IPUMS-USA作为sense.us应用的主要数据来源。使用IPUMS Web界面,我们首先选择了1850~2000年的样本数据(不包括1890年),然后选择了需要抽取的一组变量。绝大多数变量只是所有人口统计年份的一个子集。为了对长期的变化进行可视化探索,我们选择了一组变量,它们至少在一个世纪内都是可访问的。这组变量由22个变量组成,包括年龄、性别、婚姻状态、出生地(美国某个州/地区或者其他国家)、职业、种族、学校出勤率以及地理区域。由于隐私约束,地理数据仅仅局限于粗粒度的区域如新英格兰和美国西海岸。结果数据的抽取是把520MB的Gzip文件解压缩为3.3GB的文本文件。
接下来,我不会赘述后续发生的详细细节。数据处理、清洗以及后续的导入操作是直接但繁琐的过程,最终生成了包含抽取出来的可查询形式的人口统计数据,保存在MySQL数据库中。为了帮助分析,我们使用星型模式来组织数据(htp://en.wikipedia.org/wiki/Star_schema):把人口统计的评测方法存储到一张大的事实维表(fct table),该维表的每一列表示一个人口统计学变量,通过键值表示变量的范围值。维度表集合存储了每个人口统计变量采用的键值的文本标签和描述。
这种组合方式提供了指导探索性分析的基础。我们通过发布查询生成数据摘要,这些查询通过选定的维度“向上钻取”(rlled up)数据。举个例子,我们可以通过对所有其他变量的样本人数进行求和,分离出年龄、性别和婚姻状态的关系。简而言之,我们拥有探索数据和原型系统可视化的基础。
