可视化
给定人口统计数据的大小和范围,我们早就意识到把单一的可视化设计应用于所有的数据可能会导致某些灾难。只要有可能,我们就希望把数据转换成最简单的形式,用于支持广泛的分析。由于我们的设计需要面对广泛的受众,我们创建了一个可视化数据集合的方法,它表示选定数据的分片。在本质上,我们希望可视化有用,同时,它又尽可能地简单。
因此,我们的设计哲学需要理清哪一种数据集合可能是最大的兴趣点,而哪一种可视化设计和交互技术可以最佳支持对这些维度的积极探索。为了实现这一点,我们开始同时探索数据本身和可视化设计空间。
在设计一个界面来帮助别人探索数据之前,我希望首先能够确保数据本身足够有趣,使得别人愿意去探索它。我在探索中采用了很多种方法,包括SQL查询、Excel和可视化系统。数据探索最有用的工具是数据库可视化系统Tableau。使用Tableau工具,人们可以把数据库的各个字段通过拖拽方式映射到视觉编码中;然后,应用查询该数据库,对结果进行可视化(披露一下,我是Tableau软件的顾问)。因此,我们可以对很多不同方法构建可视化原型系统(见图12-3)。我们生成了一个庞大的数据可视化集合,和同事分享该集合,收集他们的反馈。使用真实数据快速评估可视化方法的能力为我们节省了很多实验时间,使得能够为最后的系统设计保留开发精力。
在探索数据过程中,我记录下了有趣的趋势、模式和发现的游离点。在某些情况下,有意思的故事是在很多维度的组合下发现的。例如,通过年龄和性别对婚姻状态的统计结果说明了女性初次结婚的平均年龄随着时间在增长,在过去一个世纪大约增长了5年。在其他情况下,根据单一数据类型描绘的曲线随着时间推移,揭示了很多有意思的故事,如农民工在劳动力市场中的盛衰以及全球不同的移民浪潮。一般来说,我发现对数据进行转换是很有用的,可任意把数据看做绝对人口数量,或者看做是十年内人口普查比例。
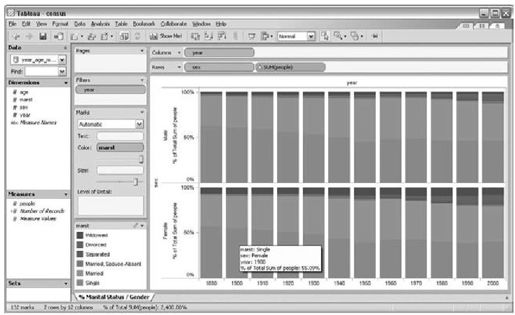
图 12-3:使用Tableau工具构建的显示几十年间婚姻状态分布的原型系统可视化(见彩图36)
设计考虑
有了原型系统,Martin、Fernanda和我为sense.us应用协作设计了交互式可视化。在设计中,我们首先简单列出了设计中的一些考虑。
培养个人相关性
如果没有人关心数据,就没有人会去探索它。我们假设熟悉的维度如地理和时间,使得用户能够快速地在数据和表单叙述中他们自己(或者和他们相似的人们)。假设我们可以访问的地理数据是有限的,我们集中于随着时间的变化来表示数据。我们还尝试使用交互技术,使用户可以快速找到他们感兴趣的数据记录,如特定的职业或国家起源。
提供有效的视觉编码
自然而然,我们希望使用视觉编码来帮助理解数据。在某些情况下,这种工作任务直截了当:如果想要检验两个数值之间的关联,我将很难找到比散点图更好的表示方式。在这种情况下,我们需要做出很多折中权衡。
对随着时间变化进行可视化的一个通用方法是使用线条图。但是,在一个线条图中显示200多个职业会导致封闭的线条之间非常混乱。取而代之,我们选择堆栈图(sacked graph),它们可以把一个图叠加到另一个图上,从而可以对多条时间序列视觉上求和(见图12-4和图12-5)。我们的这种选择是受到Martin的婴儿名向导图(Bby Name Voyager)可视化的影响,婴儿名向导图是关于婴儿名字受欢迎程度的堆栈图,在网上变得超乎寻常地受欢迎(Wttenberg和Kriss 2006)。堆栈图可以清晰地显示聚集模式,并且可以很优雅地支持交互过滤,但是其代价模糊了个人倾向——对于某个倾向的理解是由栈序列的曲线带来的偏见生成的。相反地,我们确定点击一条序列可以过滤出对它的显示,因此,通过这种方式,其趋势可以很容易被隔离出来进行显示。
进一步地,我们遵循了构建的文化约定,通过很多观察者所熟悉的方式对数据进行视觉编码(比如,用蓝色表示男孩,粉红色表示女孩)。当考虑如何在很多人口统计学变量间对交互进行可视化,而不是试图发明一些完全新颖的东西,我们采取的是对人口统计学家已经普遍使用的图形类型——人口金字塔进行扩展。
使每种展示方式都与众不同
在某些情况下,我们使用了相同的可视化类型来显示不同的数据类型。例如,对于职业和出生地数据,我们都使用了堆栈图。然而,我们希望每一种展示方式在视觉上都与众不同,这样用户就可以一眼识别出它们。结果是,我们为每一种可视化都构建了唯一的彩板。
支持直觉探索
为了培养交互探索,我们希望使得接口操作尽可能地简单。对于堆栈图,我们让用户输入搜索关键字对感兴趣的项进行查询。在其他情况下,我们提供了一组下拉菜单对维度进行选择或者过滤。我们还包含了控件来选择绝对人数计数和范化的比例。更高级的控制可能实现,而且我们发现提供该级别的控制能够促使通过整洁易用的接口所做的一系列探索。
积极参与玩耍
除了培养个人相关性,我们希望和该系统的交互有趣好玩。因此,我们致力于采用优雅高效的数据表示方式。我们设计了交互技术和动画转换技术来提高响应和动态性效果,但是我们不想过度滥用这种文体特征。
我们希望增强而不是骚扰数据探索。我们不断改变动画形式和计时方式,直到设计上“感觉良好”。持续1秒钟的动画提供了不需要放慢分析的过程,观看者就可以跟上的视觉转换过程。
可视化设计
首先通过参与自己的数据探索,我们可以确定自己最感兴趣的数据维度。为了设计一组人口统计数据的可视化解决方案,我们把这些观察应用到设计考虑中。
工作向导
“工作向导”(Jb Voyager)是一个堆栈图,显示了美国在过去150年间(见图12-4)的劳动力的组成部分。每条序列曲线表示一种职业,通过性别进一步细分:蓝色代表男性,粉色代表女性。用户可以通过点击一条序列曲线,只显示其相应的职位,或者通过输入关键字查询来过滤掉与查询不匹配的职位。我们还包含了下拉菜单,通过性别进行过滤;在绝对人数计数和劳动力比例之间进行视图转换。这些操作支持对聚集趋势(如第二次世界大战后涌入劳动力市场的女性)和个人模式(如机动车工程师的盛衰)的探索。
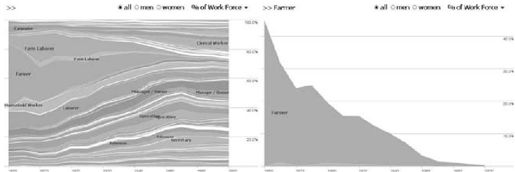
图 12-4:工作向导可视化:左图显示在过去150年间劳动力组成概要视图,右图显示过滤后农民工的比例的视图(见彩图37)
我们很快意识到仅仅通过性别对序列曲线进行着色是不够的。当我们过滤了视图,仅仅显示男性或者女性,要区分不同的序列曲线变得很困难。一个解决方案是通过任意方式改变色彩饱和度,使得感官上能够区分不同的序列曲线。Martin提出了一种很有技巧的变换方式:不是随意改变颜色,而是通过有意义的、数据驱动的方式来实现。因此,我们根据每个职业的社会经济指数分值来改变其对应的颜色饱和度。因此,平均收入越高的序列曲线,其颜色越深。在实践中,这种编码方式工作良好,不需要为显示增加误导或者无意义的视觉特征,而提高了不同职业的识别度。
出生地向导
“出生地向导”(Brthplace Voyager)和工作向导的设计相似,但是它显示的是每个人口统计年份的美国居民的出生地(见图12-5)。其记录的出生地或者是美国某个州和地区或者是其他国家。交互式控件可以通过查询关键字或不同大陆位置进行过滤,只显示绝对计数和比率。
数据可视化支持对全世界(如过去来自欧洲的移民浪潮以及当前来自拉丁美洲的移民浪潮)和美国国内(如每个州的居民的变化比率)的移民趋势的探索。
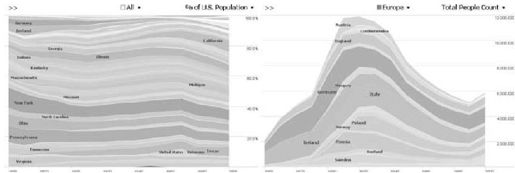
图 12-5:出生地向导可视化:左图显示在过去150年间出生地的分布概要,右图显示过滤后欧洲移民的总数的视图(见彩图38)
在出生地向导中,我们遇到了和之前相似的着色问题。在这种情况下,我们根据大陆位置来分配色彩,为美国的各个州增添一些额外的色彩。然后,我们实验了改变色彩饱和度的不同方法,直到我们可以使用在该州出生的人口总数或者所有时间片断的国家作为后备数据。
美国人口统计的国家地图和散点图
虽然工作向导和出生地向导的时间线在设计上都是使观察者以历史叙述的方式进行参与,但是我们希望能够包含更加传统的视图。我们提供了一个着色的美国国家地图,显示每个州的人口统计变量的分布。在2000~2005年(如图12-6的左图所示),在国家人口变化的标注地图中,人们可以看到西南部地区人口得到显著增长,而North Dakota的人口却在不断下降。我们还提供了散点图的表示方式来检测不同变量之间的潜在关联。用户可以把人口统计变量映射到坐标轴的x坐标和y坐标,圆圈的面积表示整个美国。例如,人们可能会注意到全国家庭收入和零售额之间的关联(如图12-6的右图所示)。这些视图的备份数据包括我们从美国人口统计局网站上下载的额外的统计数据。
人口金字塔
最复杂的可视化是交互式的人口金字塔,它是为了同时帮助探索多个人口统计学变量而设计的(见图12-7)。人口金字塔(有时称之为“年龄-性别”金字塔),是由同事介绍的关于人口统计学的一种图形。金字塔被一条垂直曲线划分为两半:一条曲线表示男性,另一条表示女性。y轴表示年龄,通常以5年或10年作为一组进行分组;x轴表示某个年龄段的总人数,男性的人数值朝一个方向增长,而女性的人数值朝相反方向增长(如图12-7的左图所示)。该金字塔形状传递了人口动态信息:险峻的金字塔暗示了其死亡率比圆柱形的更高。

图 12-6:(左图)交互式国家地图显示每个州从2000~2005年的人口变化,(右图)美国散点图显示了平均家庭收入(x轴)和零售额(y轴),新罕布什尔州和特拉华州有最高的零售额(见彩图39)
我们创建了一个交互式金字塔,除了年龄和性别,它还结合以下人口统计变量:地理区域、种族、婚姻状态、学校出席率和收入水平。该金字塔的两边默认通过性别来划分数据。我们放宽了这种限制,增加了下拉菜单,通过该菜单,用户可以选择一个人口统计学变量,把该变量对应的(x,y)两个值映射到金字塔的两条边上。比如,用户通过把美国西部海岸放到金字塔一边,而把新英格兰放在另一边的方式来观察地理区域。
我们还引入了彩图编码菜单:选择一个人口统计变量把金字塔的两条边转换为描述变量值的流行率(pevalence)的堆栈图。例如,用户可以以学校出勤率进行统计,用于查看学校人口出勤率分段情况(如图12-7的右图所示)。我们为每个变量选择一个与众不同的彩板,只要可能就依赖于已有的文化约定(如蓝色=男性,粉色=女性),使用在线工具ColorBrewer(http://colorbrewer.org)来确定其他情况的颜色选择。我们使用灰色带表示数据丢失或者未知值。

图 12-7:人口金字塔可视化:(左图)2000年的每个年龄组的男性和女性的总人口数量的比较,(右图)2000年学校出席人数的分布(标注重点突出了成人教育的流行率)(见彩图40)金字塔下方的时间线使得可以在整个人口统计期间进行时间探索,而回放特征使金字塔可以随时间动态变化。举个例子,随着时间对人口变化的动画显示显著突出了战后期间
社会出现的婴儿高潮。由于多层次色彩和泡沫式动画的结合,用户亲切地把我们的人口金字塔重命名为“Georgia O'Keefe的熔岩灯”(lva lamp)。
最后,我们支持四种尺度来衡量数据:人口总数、10年内人口比率、(金字塔)图面内(pnel)比率(当金字塔两边不协调时有用)和年龄组比率(为了探索不同年龄间的比率区别)。我们发现每一种衡量尺度都有助于揭示某些特定的故事。例如,年龄组比率显示说明了年纪大的男人比年纪大的女人更容易结婚,推测原因是女人平均活得更长,因而成为了寡妇。
实现细节
我们把每一种可视化作为Java Applet(Java应用小程序)实现,这样我们可以把它嵌入到Web页面。选择Java而不是Flash,一部分是由于性能原因,但更重要的是当时有现成的Java可视化框架。堆栈图和人口金字塔是通过开源工具包Prefuse(http://prefuse.org)构建的。每一种可视化是通过从人口统计数据库中抽取出来的纯文本文件来支持的。对于人口金字塔,我们为每种可能的人口统计变量组合生成了一个文件,预计算数据的所有相关投影。这种方式避免了在服务器端处理数据的需求,生成方便管理的存储历史:虽然刚开始数据库包含3GB多的数据,在最后部署时数据减少到仅仅稍多于3MB!当然,这种方法确实存在其局限性:它阻碍了用户探索新的人口统计变量组合,并且使得要求服务器端处理数据的可视化变得复杂。
