在线发布数据
我们的目标是让所有的实验记录与处理后的数据可以在线得到。如何在Web中以一种有用的格式发布数据产生了一系列的问题,其中包括标准标识符、可视化工具和数据集成方式的选择。
化学实体的唯一标识符
要让我们的数据有用,使用公认的标准来描述化学实体就很重要。如果不这么做,数据集的集成就会变得很困难或者不可能。在化学中,有些人认为使用CAS注册号[1](htp://en.wikipedia.org/wiki/CAS_registry_number)标识化学实体很理想。不过,CAS号本质上是私有的,而且不能转化为化学结构,只能用作查询,而且依赖与一个外部的组织来进行编号。我们更倾向于本质上开放的标识符,可以自由地进行交换,并可以同化学连接表[2]双向转换。
IUPAC[3]国际化学标识符(IChI,发音为“INchee”)提供了一个非私有的标准与算法以及相应开源支持软件(htp://en.wikipedia.org/wiki/Inchi)用于标识字符串的生成及标识符到化学结构逆转换(参见http://www.qsarworld.com/INCHI1.php的最近讨论)。InChI作为一个标准正在获得软件厂商、出版商和开发者的鼎力支持。InChI算法——即对同一结构生成多个不同InChI的可能性——已经通过标准InChI(Standard InChI)的开发得到了解决。对于某些用途,InChIKey(InChI的一种hash码)已经很实用,可是InChIKey不能转换成结构,而且只能在搜索化学结构的查找表中使用。
SMILES(http://en. wikipedia.org/wiki/SMILES)是一种标识化合物的常见结构,其字符串编码非常紧凑,并且可以和化学结构双向转换。但是,SMILES算法有多种形式与实现,导致了同一化学实体有不同的SMILES。现在我们在此项工作中使用SMILES是由于其简单且搜索容易。正如本章的“通过唯一标识符与自描述数据格式实现数据集成”所述,将我们的SMILES转换为InChI是可行的,从而我们可以自动将数据集成到由InChI标识的数据网络中。
开放数据与可访问服务提供了广泛的可视化与分析选择
有了一个标准、自由、可访问的原始溶解度数据贮存构架,下一步就是分析数据。分析可以是简单地生成所有已完成测量的汇总,也可以是来自数据衍生模型的复杂统计描述。不论是哪种情况,都有必要通过自动化的方式访问数据以进行处理。采用其他来源的信息来丰富数据也是值得一做的。这反过来又要求主要数据需以通用的标准发布。
电子表格包含了若干列,每一行是一条测量值。溶剂和溶质都采用了两种格式表示:人类可读的通用名及机器可读的SMILES编码。由于选择GDoc作为数据的主要发布形式,为了让数据集发挥最大优势,采用机器和人类可读的两种表示是非常重要的。唯一不需要采用两种表示方式的是采用数值表示的溶解度本身。
前面已经提到,我们决定不从主数据集中剔除有问题的数值。这产生了一个机器可读性的问题,因为并没有通行的方式来表示“这个数字有一点狡猾”。对于这项工作,我们决定在人工判读之后来标记那些被认为是不准确的数据,并给出理由。这使得任何用户在做任何分析时都可以选择采用那些记录,不管是采用人工还是自动的方式。任何进一步的详细分析都需要访问电子表格中的数据。最简单的方式就是把数据导出,比如导出为CSV文件,然后用其他软件来分析。但这样会导致无法获取到最新的数据。G公司的Doc API则可以让创建Web应用变得简单,同时又维持着与“实况”数据的连接。
作为这种应用的示例,我们创建了一个Web服务来让用户查询电子表格中储存的数据并获取表格汇总(见图16-2)。这个基于表单的查询界面为获取相关数据提供了一个快速直观的访问方式。整个页面只由HTML与JavaScript构成,不需要任何的服务器端软件。数据是通过G公司提供的API从GDoc中异步访问的。获取数据之后,就可以进行一系列的计算。在这里,我们要计算溶解度的平均值和标准差,可以用于动态高亮反常数据。不仅原始数据子集的表格输出很有用,可视化技术也可有效地概括查询结果。这个查询应用采用G公司Visualization API生成电子表格中提取数据的柱状图。从电子表格提取数据很容易,生成一系列可视化图表也是很容易的。在我们的案例中,一个显示某化合物在不同溶剂中溶解度的简单柱状图就可以提供结果的简要概括。
本应用的另外一个值得注意的地方是表格中包含化学结构的二维渲染图,渲染图是通过美国Indiana University基于REST的服务提供的。通过在服务URL中传递SMILES代码,可以将化学结构的二维图片插入到任何网页中。同样,这些特性也不需要服务器端软件的支持。分发这种应用变得非常容易,仅仅只需要把HTML页面拷贝到另一个Web服务器上即可。
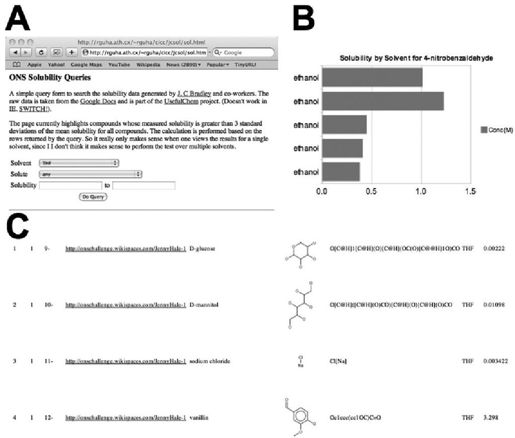
图 16-2:用于检视溶解度数据的可视化工具。A)采用JavaScript和G公司Doc API生成的一个简单表单输入界面;B)溶解度数值的图形化表示;C)带有二维化学结构渲染图的数据表格输出,可以从http://toposome.chemistry.drexel.edu/~rguha/jcsol/sol.html访问此服务。请注意:本服务与这里提到的其他服务都是动态的,可能得到与上图所示不同的查询结果(见彩图54)
虽然这只是一个相当简单的应用程序,但它突出了这种解决方案的分布式本质,即把开放数据与具有多个来源的免费可视化方法结合起来。更重要的是,这个系统的分布式本质和可自由获得的数据使得来自不同领域的专家们——测量数据的实验员、制作接口的软件开发者以及制作创建统计模型的计算建模人员——可以更好地将他们的专业技术结合起来。开放数据、开放服务以及支持它们的生态系统的真正前途在于:这种专业技术的结合不需要建立任何正式的合作关系。研究人员可以用一种数据的测量者所想不到的方式来使用数据。不管是进行补充实验,还是做新的分析,或者提供处理数据的新服务,这样做都可以使原始的数据集更有价值,同时加强它周围的生态系统。而且不管什么时候,都可以找到指向原始记录的链接。
通过中心聚合服务集成数据
对于我们主张的方式存在一个合理反对意见,那就是:如果此方式被广泛采用,那么将会导致很多分散、不相连的数据源出现。尽管,从技术上可以利用搜索工具将这些资源汇总起来,但对于研究人员来说,这仍然是一个问题。因为他们通常习惯于使用几种他们喜欢的服务。有人校对的化学信息数据集中,美国化学会的化学文摘服务(Cemical Abstract Service,CAS)是黄金标准。CAS注册集中覆盖了超过四千万种物质(htp://www.cas.org/newsevents/connections/derivative.html),其中包含的数据来自出版物、专利、化合物目录以及越来越多的在线数据源,比如ChemSpider(http://www.chemspider.com/blog/caschemspider-connectivies-and-unintended-collaboration.html)。
ChemSpider是以“构建以结构为中心的化学家社区”为目的为化学家创建的Web资源。有来自超过150个数据源的两千余万不同的化学实体,ChemSpider已经成为了化学家寻找化学实体信息的主要Internet资源之一。每个化合物都有不同类型的信息相互关联起来,这些信息包括不同的标识符(系统命名、商品名、注册号、各语种命名),理化性质的预测值,实验获得的物理、化学与光谱数据来自一系列数据源(htp://www.chemspider.com/DataSources.aspx)的指向链接。因此ChemSpider可以看做一个指向其他资源且基于结构的链接农场[4]。同时,ChemSpider还提供了一个操作环境,以便用户在线简要或者扩展显示数据。用户可以批注、校对数据,从而删除化学实体的错误关联,并且添加他们自己的信息,包括指向外部资源的链接或者其他数据批注。用户也可以向数据库中储存新化学结构,并为之关联光谱数据、图片,甚至是视频文件。ChemSpider中有很多种搜索功能,包括搜索预测的数据、基于结构或子结构的搜索[5]。
ChemSpider中数据主键通常是分子的通用标识符,如此就为连接其他来源的化学信息提供了一个理想的环境。ChemSpider不仅提供了化学数据搜索的中心资源,同时也是用户的数据银行,其他研究人员就可以很容易地通过它找到我们的数据。尽管一些ChemSpider关联的数据是由在线资源抓取的数据搜集的,但是对这种方式需要小心处理(htp://www.chemspider.com/blog/care-in-nomenclature-handling-andwhy-visual-inspection-will-remain.html),更多的数据是在进行了某种形式的人工校对后添加的。
非水溶剂溶解度数据是作为ONS-Solubility[6]项目的一部分添加到ChemSpider中的。目前一些在线可得的数据是作为补充信息和化合物数据中可能有的其他理化数据放在一起的。溶解度数据有一个链接指向实验记录页面,这样既和ChemSpider作为指向原始数据源的链接方式一致又和我们指向原始记录的方式一致。图16-3给出了一个ChemSpider的示例。记录中有了越来越多的非水溶剂溶解度数值,可能是人工测定或者机器测定的,这些数据都会发布出来,其相应的原始来源信息也可以点击可得。

图 16-3:这是ChemSpider条目显示溶解度数据与原始数据链接的例子(见彩图55)
以后会有更多质量与校对程度参差不齐的数据在线发布,可以预想到数据提取过程会自动化。在现在的项目中我们已经在努力利用自动化过程,不过自动化过程可以推广之前有两大困难需要克服。第一个问题是信任问题:哪些来源的数据可以给予充分的信任然后自动提取?对这些数据源应该进行何种程度的人工校对?目前对GDoc电子表格主数据的校对程度是否足够?是否还需要进一步的过滤?对目前的情况来说,我们采取的方式对一个致力于提供化学家可以无条件信任的服务还有差距。随着研究者发布更多的原始数据以及自动数据提取的增多,需要详细讨论数据应该在何时以怎样的方式发布,数据放置在上千白名单中需要怎样的标记。数据发布的认证过程会越来越多,从而为发布的数据提供质量和功能的双重标记。
第二个主要问题是功能问题:关联到ChemSpider的数据集目前来说还不多,在大多数情况下也是稳定不变的,所以人工提取过程尽管需要工作较多但是更实用一些。随着数据集的增多,这种人工过程会变得不可能。将数据作为在线电子表格发布出来对研究组来说很方便,但是并不能映射进ChemSpider或者其他中心汇总服务的数据结构中。ChemSpider是基于微软SQL Server的关系型数据库的。ChemSpidr标准Web页面中显示的理化数据是保存在数据库的数据表中的。在有数以万计数据供应者创建各种数据的世界中,需要一个通用语言来使广泛的数据重用于汇总成为可能。描述化学信息有多种相互竞争的标准。最可以信赖的方式是开发一种方法让数据尽可能以通用的形式展示。然后,就可以开发在不同描述标准间转换的服务。
通过唯一标识符与自描述数据格式实现数据集成
尽管G公司的Doc API提供了为数据集开发分析工具与可视化方法的简单途径,但是问题仍然存在,数据的展示并不是标准格式,连唯一标识符也是如此。那些工具是根据GDoc电子表格为此数据集所写的。简单来说,它们需要人类来理解电子表格的每一列是什么描述符什么数值。尽管利用程序来判断包含SMILES代码的列是可行的,但是机器却不能知道它是溶剂还是溶质,甚至根本就不能判断到底是不是溶解度数据。要实现相互连接数据的希望(即支持ChemSpider和其他服务的自动提取),要以最通用的方式将数据提供给其他研究人员,那么就有必要提供一种遵守语法标准与描述符标准的格式。
资源描述框架(Te Resource Description Framework,RDF),提供了将数据集以一种公认的机器可读格式发布的方式。有了这种格式,任何信息都可以转换为一条由一个“主语”、一个“谓语”和一个“值”组成的语句。举例来说,下面代码片段中所示代码表明电子表格中找到的对象叫做solute#59,在给出的URL中定义为资源。RDF使用“命名空间”,或者说采用公认概念集来定义“资源”之间的关系,资源可以是由唯一标识符指向的任何对象。这里一共有四个主命名空间。第一个是RDF命名空间本身,它定义了文件是RDF格式的,提供了诸如“由……定义”或者“是一个资源”这样的顶层概念。第二个命名空间是包含数据的电子表格,其本身也是个资源,在这里由命名空间ons定义,其中又包含了某些资源,每个单元格即是一个资源。第三个命名空间是Dublin Core(dc),包含了诸如名称、作者和版本的概念。第四个命名空间是chem,托管在http://rdf.openmolecules.net(RON),用来指定某个单元格定义的分子是被定义为一个资源的。
如前面所说,电子表格有它自己的数据结构,大体上是每一行指向一个测量值。G公司的Doc API可以让一个简单URL就可以引用一个单元格。要将此写入RDF声明中,我们需要描述单元格内容间的关系,比如“2-辛酸”和其他资源间的关系。一个简单关系指出“2-辛酸”由RON的某个资源定义,RON通过简单的HTTP URL引用。有了定义好的单元格内容,就可以使用外部资源来找出关于这个分子更多的信息。解析这个URL就可以获得RON服务定义的更多关于这个分子的RDF语句。类似地,它也可以给出SMILES和分子的名称,这些都是从电子表格中取得的。对我们数据中每条表示分子的记录都无一例外地可以定义一个标准描述让和包括系统命名、InChI和SMILES在内的其他标准定义连接起来。
<ons:Solute rdf:about="http://spreadsheet.google.com/……/onto#solute59"> <rdfs:isDefinedBy rdf:resource="http://rdf.openmolecules.net/?InChI= 1/C8H14O2/c1-2-3-4-5-6-7-8(9)10/h6-7H,2-5H2,1H3,(H,9,10)"/> <chem:inchi>InChI=1/C8H14O2/c1-2-3-4-5-6-7-8(9)10/h6-7H,2-5H2,1H3, (H,9,10)</chem:inchi> <chem:smiles>CCCCCC=CC(=O)O</chem:smiles> <dc:title>2-octenoic acid</dc:title> </ons:Solute>
定义了电子表格中找到的每个化学实体之后,我们就可以将每个测量值类似上述的RDF片短表达。RDF定义了新的测量值,给出了溶剂、溶质、溶解度和测量值所属的实验。由于我们已经用化学表达定义了每个溶质和溶剂的ID,这个测量值信息也可以被其他描述同一分子的RDF文件链接并使用。下面的RDF片段使用XML实体ons作为http://spreadsheet.google.com/plwwufp30hfq0udnEmRD1aQ/onto#的别名来让XML可读性更好。(masurement179可以扩展为添加了“measurement179”的完整URL。)
<ons:Measurement RDF:about="measurement179"> <ons:solubility>0.44244235315106</ons:solubility> <ons:solvent RDF:resource="solvent8"/> <ons:solute RDF:resource="solute26"/> <ons:experiment RDF:resource="experiment2"/> </ons:Measurement>
这些语句,或者说三元组[7]可以用任何RDF引擎和诸如SPARQL的查询系统读取或者分析。通过使用合适的命名空间,尤其是那些被承认和分享的命名空间,可以生成基本上自描述的数据文件。我们开发了一个解析器(htp://github.com/egonw/onssolubility/tree/)来生成完整的RDF文档,可以在http://github.com/egonw/onssolubility/tree/master/ons.solubility.RDF/ons.RDF下载。化学开发工具包(Te Chemistry Development Kit,CDK;参见http://cdk.sourceforge.net/)用来从SMILES中获得包括InChI在内的分子属性。这是关键一步:将实验特定信息转换为可以有任何支持RDF系统或服务读取的数据文件。这种服务不需要理解如何处理新命名空间的特定概念,但是却可以知道如何处理这些概念所属的类别,从而可以将数据解析为使用相同命名空间的其他资源。
RDF的真正力量在于将多个资源通过链接连接起来(见图16-4)。举例来说,可以将我们的实验数据连接到DBPedia的数据中,DBPedia(http://dbpedia.org)是一个由RDF呈现的在线信息资源。DBPedia使用名为简单知识组织系统(Smple Knowledge Organization System,SKOS;参见http://www.w3.org/TR/skos-primer/)的命名空间来引入诸如“类别”的概念。在DBPedia中,不同的溶剂被描述为属于不同的类表,如碳水化合物或者醚类。通过将我们的数据与DBPedia中的RDF语句结合起来,可以对我们的实验数据进行诸如按照不同溶剂类别中的测量值进行查询。之所以是这样可能是因为RON中的资源将某些概念(分子的ID)与我们的数据和DBPedia中的资源链接了起来。尽管DBPedia中可能包含错误的化学命名(只要对象关联了正确的InChI即可);尽管我们的数据没有溶剂类别的概念;尽管DBPedia对ONS命名空间一无所知,RDF还是做到了。
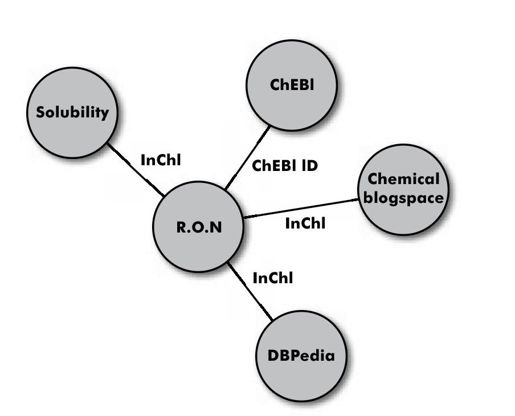
图 16-4:通过R D F将溶解度测量值和更广阔的数据网连接到一起。RO N(http://rdf.openmolecules.net)即将DBPedia、Chemical Blogspace和ChEBI(欧洲生物信息学研究所的化学资源)中的记录连接到一起
将此更进一步,可以把我们的实验数据连接到Web上更广阔的天地中去,举例来说,可以利用RON中的RDF识别出讨论某个特定化合物的博客。此RDF包含了指向Chemical blogspace(http://cb.openmolecules.net/)的链接,同时共享唯一识别符(在这里,InChI以URI的形式得到了使用)。rdf.openmolecules.net连接到了一系列数据源,这样又为不同来源的数据和分析结合在一起铺平了道路。RDF方式的价值在于可以在此图的任何一个地方插入附加数据。共享更多共同的词汇元素可以让数据集成变得更好,不过只要有一个共同的标识符,数据集成就可以开始。
[1]CAS注册号是一种化学物质的人工编号方法,如甲苯的CAS注册号为108-88-3。
[2]化学连接表是在计算机中表示化学分子结构的一类常见格式。其基本原理为储存每个原子信息与原子之间的连接关系。
[3]IUPAC,国际纯粹与应用化学联合会。
[4]即link farm,指本身并无内容,但提供大量链接的网站。
[5]结构搜索指的是以化学拓扑结构为查询对象,采用拓扑结构匹配而非字符串查询来进行化学搜索的方式。
[6]即Open Notebook Science-Solubility,开放记录本科学溶解度项目。
[7]即包括“主语”、“谓语”和“值”的RDF语句。
