探索数据
有很多不错的数据分析工具。表17-2对一些最常见的工具进行了比较。
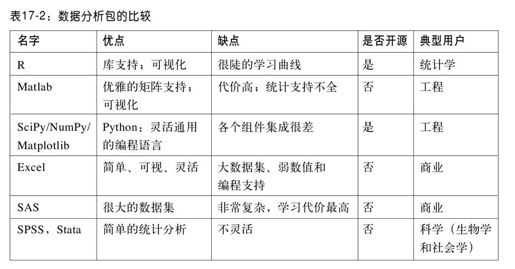
我们喜欢使用工具R,它是一个开源的统计和可视化编程环境,包含活跃的并且不断增长的开发社区。它在统计学中作为一种事实标准而产生。为了广泛的数据分析,比起其他数据分析包,我们更喜欢R工具包,因为它的图形库、便捷的索引标注以及一组优秀的复杂统计和社区维护包。你可以看看该软件,在http://www.r-project.org可以下载,并查看一下本章最后关于它的参考资料。
R提供了很多优秀的工具来查询数据的内在涵义。通过交互式注释:
Load the data>data=read.delim("http://data.doloreslabs.com/face_scores.tsv",sep="\t") and plot.>plot(data)
给定记录的基本表,R的默认描绘动作是为我们提供每个变量组的散点图矩阵(见图17-2)。一个很突出的方面是其年龄关联看起来很滑稽——最右一列和最下面一行。

图 17-2:脸部数据的初始散点图矩阵
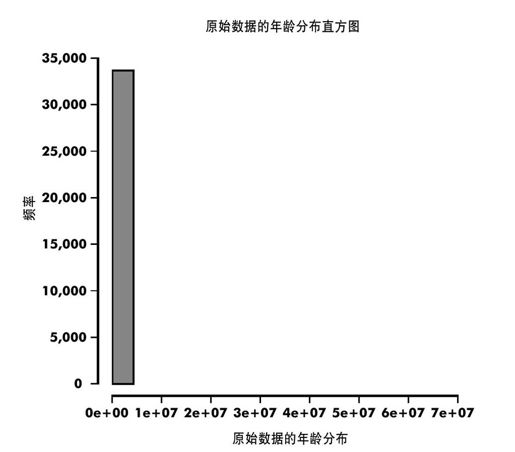
我们需要调查。第一件需要做的事是查看年龄值的分布(见图17-3)。
>hist(data$age)

图 17-3:脸部数据年龄分布的初始直方图
这看起来不正常。由于存在游离点,x轴已经横向伸长到7000万。我们一起来看包含游离点的年龄值的记录:
Select records with age greater than 100. >data[which(data$age>100),]
在初期,我们清除了非数值的年龄值,但是没有检查过分高的值。现在,最简单的操作方式是删除这些游离点。如果你之前从未使用过一种数据分析语言,注意R的丰富的下标标注,它使得基本的探索和清除变得简单有趣:
Subselect rows with age less than 100. >clean_data=data[which(data$age<100),]
我们再一次检查了直方图(见图17-4)发现我们的绝大多数用户是(或者看起来是)18~30岁,这看起来很合乎情理。
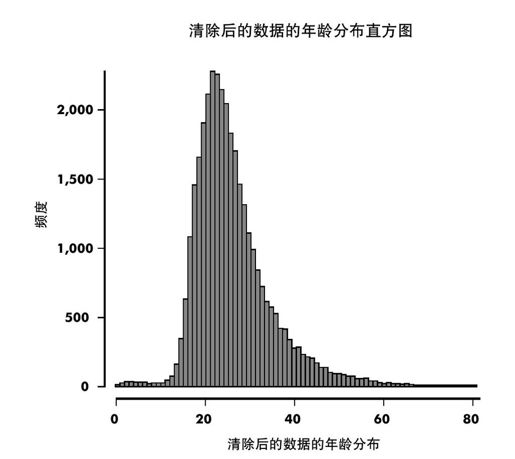
图 17-4:清除后的脸部数据的年龄分布直方图
