连接数据的障碍
希望你已经相信把不同数据源的数据整合起来有很大优势。但是存在一些原因,使得人们并没有做这件事……
展现问题
试图连接数据集所面临的最基本的问题可能是很多数据存储在非常不灵活的结构中。首先,在科学和商业中,有惊人数据量的数据就存储在Excel表单,保存在人们本地的计算机中,其他人无法访问,而且不是为整合而做出的设计。
即使在数据库可以访问的公司,数据通常是存储在关系数据库中,很多都是预先定义适合最初设计时认为重要的模式。图20-2显示了餐馆数据的关系模式的一个简单例子。这对于大的、可预测的数据集很好,因为当配置调整很少时,关系数据库的性能非常卓越,但是当应用需要新的数据类型、新的字段或者需要经常添加新的关系时,这些都对关系数据库提出了难题。
我见过人们通过很多种方式来解决这个问题,但是有两种方式很突出,主要是因为这两种解决方法刚好相反。传统的解决方式是不断地重构数据库,创建新表,给已有表增加新的字段,这个过程可能代价很高,很容易犯错误且很慢。(由于篇幅问题,我在这里就不再赘述其他例子,但是每当我谈到这个问题时,总有很多人点头。)这种解决方式使得模式变得越来越复杂,最终使得整个模式变得过于复杂,难以可视化和理解。
我见过的另一种解决方式是简单地构建一个非常基础的数据库模式,它可以支持任何类型的数据。通常的实现方式是有一个实体表、一个关系表以及如图20-3所示的UML图。
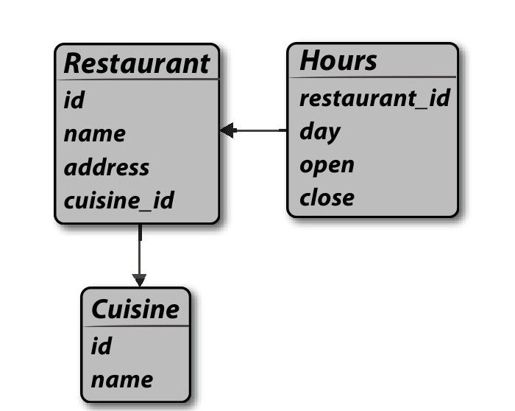
图 20-2:餐馆数据的关系数据库模式
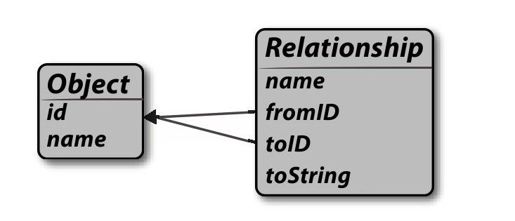
图 20-3:基础的数据库模式
这种做法有个优点,开发人员和数据加载人员可以随时给数据增加新的关系。一般来说,它把数据表示成图,而不是一组表。图20-4显示了以图形表示的餐馆,以及人们日后可以很容易增加的额外数据。
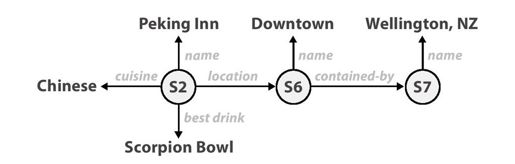
图 20-4:餐馆数据的“图形数据库”,可扩展
遗憾的是,关系数据库不是为了以这种方式来存储数据而设计的,而在该模式上做任何有用的查询将需要很多自连接操作,因此会变得非常慢。
由于这是一个非常通用的模式,因此最近几年出现了很多商业的和开源的“图形数据库”,专门为了存储这种数据而设计。以下是一些例子:
Sesame(http://openrdf. org)
一个开源的图形数据库,由荷兰的一家软件公司Aduna维护。
Jena(http://jena. sourceforge.net)
另一个开源的图形数据库,由Hewlett Packard开发。
AllegroGraph(http://agraph. franz.com)
它是一个特征更丰富的商业图形数据库,由Franz开发。
Neo4J(http://neo4j. org)
它是一个有商业授权的开源图形数据库。
虽然它们代表了在数据建模和开发实践上的转型,当从多个数据源中连接数据时,图形数据库变得更加灵活。由于这个原因,这两种数据库最近获得了很多关注,因为人们开始考虑“复杂度扩展”以及规模扩展。遗憾的是,这个属于我们连接数据时面临的最简单的问题——已经变得越来越糟糕。
共享名词和共享动词
假定你有一个非常优雅的图形或者一个完全合适的关系模式来合并两个数据库,你如何知道哪些数据项真的相互匹配?比如可口可乐公司,一个数据库可能是“Coca-Cola”,而另一个是“The Coca-Cola Company”,或者更简单的“Coke”(但是这些都和“The Coca-Cola Bottling Company”没有关系,它是独立区分开的)。
更糟糕的是,人们在命名各个字段或者对象属性时,几乎没有任何一致性可言。在一个数据库中,一个餐馆地址可能通过address字段表示,而另一个数据库可能通过location字段表示。我们如何识别一个数据库的location字段在作为餐馆的一个属性时,表示的是地址,但是当location用于描述基因序列时,表示的是在染色体中的位置。在实践中,这通常是一个人工识别过程,但是如果我们期望构建一个系统,可以很容易整合成千上万的数据,我们需要找到一些方式来消除整合过程中需要涉及的人工操作。
人们已经尝试了很多种办法来解决这些命名问题。在语义Web社区产生了“链接开源数据”,人们鼓励其他人通过标准的通用资源标识符(UI)来表示特定的对象(如一部电影、一个人或者一个餐馆),因此当两个人探讨相同的事物时,所有人都可以理解。人们已经为一组本体(otologies)进行标准化,这些本体描述了应该使用哪些字段来描述在所有情况下的餐馆或电影这类事物。
然而,到目前为止,同意使用相同的URI来表示事物以及采用相同的本体论来描述事物的组织在所有的免费数据库中只占了非常小的比例,而且几乎没有覆盖任何公司的私有数据库。在很多情况下,即使那些试着参与链接的开源数据,当前也并没有使用相同的URI来表示显然是相同的事物。这意味着,对于像我们这样试着连接数据集,我们将需要设计自动确定两种事物相同的方式。
同一事物的不同名字
和很多人一样,当我第一次试着连接数据集时,我想到了一个不错的一级假设,确定两个事物相同的最佳方式是它们有相同的名字。我甚至认为通过使用字符串距离和子串匹配就能够很有技巧地解决像“Coca-cola”和“The coca-cola company”这样的问题。这在很多情况下适用,但是在最有意思的情况下通常失败了——而且是你最感兴趣的那些情况。
我在试着结合维基百科的电影数据和Netflix网站的电影数据时遇上的一个简单的例子是《Prêt-à-Porter》。维基百科用该名字来描述这部电影(虽然实际上它是一部美国电影),但是在Netflix上,则是用英文名字《Ready to Wear》来描述。在你认为我们应该先把名字翻译成英语,再进行字符串比较时,首先应该注意的一点是存在很多电影,同一个语言有多个名称,如《B.U.S.T.E.D.》和《Everybody Loves Sunshine》,或者《Point of No Return》和《The Assassin》——这些电影或者是在不同国家有不同的名字或者包含和发布标题不同的工作标题。
因此,如果我们不依赖于搜索相似的字符串,我们如何匹配电影?原则很简单,而细节却非常困难(是很多个人和学术研究的主题)。举个例子,我们有两部电影,都是在1994年发布的,都是由Robert Altman导演,Julia Roberts和Sophia Lauren主演:它们有可能会是不同的电影吗?正如实际情况所示,只有一部电影满足这些特征,因此包含这些属性的任何电影——不考虑它的名字——一定是相同的电影。在本章后面我将探讨在实践中是如何发现这一点。
顺便说一下,字符串距离匹配很不适合电影匹配。《Ghostbusters》和《Ghostbusters 2》是非常相似的字符串,但是它们是两部不同的电影,你可以很容易发现一部在1984年上映而另一部在1989年上映。甚至无法假定电影标题后面的数字表示的是一系列电影——《The Madness of George III》和《The Madness of King George》实际上指的是同一部电影。
同一名字的不同事物
没有意识到两种事物实际上相同通常会造成很多麻烦,生成一些副本,必要的话可以在事后解决。更严重的后果是由于两个不同事物有相同的名字或者一些其他不足以确定“身份”的属性而导致不正确地确定它们是相同的事物。这种方式更危险的原因是一旦数据库中的事物不正确地合并在一起,在不需要太多人工介入的情况下,我们就没有很简单的方式来解决掉这些问题。
在威斯康星州(美国)有7个城镇名字叫“富兰克林”,其中只有一个城镇有沃尔玛。至少有四本书的名字为《City of God》。至少有50个名叫“John Smith”的人有足够的知名度出现在维基百科上。抛开考虑错误的飞行黑名单,即使两个事物具有相同的名字,很显然也不足以证明它们是相同的,尤其对于人们的名字而言。虽然对于人来说,存在唯一关键字,如在美国是社会保险号码,但是这些信息几乎从来不会出现在公众可访问的数据库上;对人的唯一识别符通常需要某种程度的保护。
除了在非常封闭的集合(比如国家名字)或者是非常罕见的名字(我想到了“Toby Segaran”),强烈建议不要仅仅基于名字来合并事物,应该使用额外的信息来设计算法,以便确定两条不同的记录确实是同一个事物。
我觉得必须指出已经付出很多努力来为某些特定事物创建经典的标识符,但是这些标识符由于隐私问题从未被成功地应用于人。在美国,我们有社会保险号码,很多政府部门和信誉机构用它来追踪我们,但是人们告诉我们不应该把这些信息和别人分享,因此我们当然不会把它放到公共数据库中以防别人可以更容易地把他们的数据和我们的数据链接起来。因此,我们永远都处于几十亿的人们有相似的名字而没有办法识别出他们。
