附录 作者简介
Ben Blackburne是Wellcome Trust Sanger Institute的序列分析和汇编研究组的博士后。
Jean-Claude Bradley是Drexel大学化学专业的副教授以及艺术和科学学院的网络学习协调员。他带领UsefulChem项目,该项目在2005年夏天启动,目标是通过实时地把所有的研究工作发表到公开博客、wiki和其他Web页面,使得科学过程尽可能透明化。Jean-Claude发明术语“Open Notebook Science”以便和更严格的“Open Science”等其他方式区别开。他教大学生组织化学课程,其绝大部分课程内容都能够通过公开博客、wiki、游戏和音频视频来自由获取。他在组织化学专业获得博士学位,在合成和机械化学、基因治疗、纳米技术和科学知识管理领域发表过论文和获得专利。
Lukas Biewald是Dolores实验室的创始人和CEO,该公司致力于使“开放来源”(cowdsourcing)变得容易简单。Dolores实验室的博客(htp://blog.doloreslabs.com)充满了有趣的“开放来源”技术和数据可视化实验。在创办Dolores实验室之前,他是Powerset公司的资深科学家;在加入Powerset之前,他构建了Yahoo!Japan的搜索引擎排序算法。他在斯坦福大学获得了数学学士和计算机硕士学位,他在人工智能实验室工作,并发表了两篇有关机器学习应用的论文。他的个人网站是:http://lukasbiewald.com/。此外,Lukas还是个专家级别的围棋手。
Brian Cooper是雅虎研究院的首席科学家。在加入雅虎之前,他是Georgia Tech的助理教授。在那之前,他在斯坦福大学获得了博士学位。他的研究兴趣是构建分布式系统,尤其是通过数据库方式管理和处理数据的分布式系统。在雅虎,他的工作是构建庞大的分布式数据存储和处理系统。早期,他的工作方向是自适应的P2P系统、分布式流事件处理、可靠的分布式存档数据存储和XML索引。
Jason Dykes从20世纪90年代早期就一直设计和开发用于探索的交互式空间接口。他使用了一系列灵活的技术进行快速开发,包括使用Tcl/Tk、SVG/JavaScript和Processing来开发创新的软件应用和显示地理结构的创新视图。作为伦敦城市大学(htp://gicentre.org)的资深讲师,1990年他在牛津大学获得地理专业学士学位,2000年在Leicester大学获得博士学位。Jason是在地理可视化方面的国际制图联委会(Iternational Cartographic Association Commission)的联合主席。
Jonathan Follett是Hot Knife Design公司的总裁和首席创意官。他在国际上发表了关于用户体验、信息设计和虚拟团队方面的作品。他在《A List Apart》、《Digital Web》和《UXmatters》上都发表过作品,给Boston区的技术组织做Web相关的主题讲座。他的文章被翻译为中文、印度语、葡萄牙语、俄语和西班牙语。Jon的虚拟设计作品获得多个美国图形设计奖、一个Horizon交互奖和其他业界的认可。
Andrew Gelman是哥伦比亚大学的统计学和政治科学教授。他最近出版的书有《Data Analysis Using Regression and Multilevel/Hierarchical Models》(剑桥大学出版社)、《Red State,Blue State,Rich State,Poor State:Why Americans Vote the Way They Do》(普林斯顿大学出版社)和《A Quantitative Tour of the Social Sciences》(剑桥大学出版社)。
Yair Ghitza是哥伦比亚大学的政治学专业博士生,致力于研究美国政治学和量化方法。他之前在政治分析公司工作,包括Catalist公司和Copernicus Analytics公司。
Rajarshi Guha是NIH化学基因组中心的科学家,研究高吞吐量屏蔽问题的各个方面。在这之前,他是Indiana University信息学院的访问学者。在过去几年,他研究了化学信息学和计算药物发现,范围从QSAR建模和算法开发到工具箱的软件工程和部署化学信息方法和模型的Web服务基础设施。
Alon Halevy他领导一个结构化数据管理研究组。在这之前,他是西雅图华盛顿大学计算机专业的教授。在1999年,Halevy博士是Nimble Technology公司的创始人之一,该公司是第一个在企业信息集成空间领域的公司;在2004年,他成立了Transformic公司,为Deep Web发明搜索引擎,该公司后被G公司收购。Halevy博士是Computing Machinery组织的会员,在2000年获得为科学家和工程师颁发的Presidential Early Career Award(PECASE);他是Sloan会员(1999~2000)。他发表了150多篇技术论文。他于1993年在斯坦福大学获得了计算机专业的博士学位。
Jeff Hammerbacher是Cloudera公司的产品副总裁和首席科学家。在加入Cloudera之前,Jeff是Accel Partners公司的一个企业家。在加入Accel之前,他在Facebook构思、创建和领导了数据组。在Facebook,数据组是负责驱动很多统计和机器学习应用,以及构建为大数据集支持这些任务的基础平台。该数据组发表了一些学术论文和两个开源项目:Hive是在Hadoop上构建的离线分析系统;Cassandra是在P2P网络上的结构化存储系统。在加入Facebook前,Jeff是华尔街的定量分析师。Jeff在哈佛大学获得数学专业的学士学位。
Jeffrey Heer是斯坦福大学计算机专业的助理教授,他主要研究人机交互、交互可视化和社会计算。他的工作成果包含探索数据的创新性可视化技术,简化可视化创建和定制软件工具以及为最大化利用多个分析员的洞察力的协作分析系统。他是开源可视化工具箱prefuse和flare的作者,这两个工具当前被可视化研究组织和很多公司采用。在过去几年里,他也曾就职于Xerox PARC、IBM Research、Microsoft Research和Tableau Software。他在加州大学伯克利分校获得计算机专业的学士、硕士和博士学位。
Matthew Holm是波斯顿的Hot Knife Design公司的咨询创造主管,工作主要涉及公司的战略、HTML/CSS的开发以及CMS驱动的Web站点。Matt当前是Oregon的人机交互论坛的副总裁(te Oregon chapter of the Association of Computing Machinery's Special Interest Group on Computer-Human Interaction,CHIFOO)。除了在线网络领域的工作,Matt还是专业的儿童书籍作者和解说员。他的作品图片小说《Babymouse》(Rndom House出版社)备受赞誉且获得奖项,目前已经印刷超过100万册。
J. M.Hughes是一位嵌入式系统和软件工程师,对实时控制、数据采集和图像处理特别感兴趣。从2003~2007年,他负责设计、实现和测试火星着陆器凤凰号的表面成像软件。他当前致力于多波长的激光干扰仪系统的电子和控制软件,该系统可以为NASA项目验证望远镜镜片分割。他和妻子、女儿一起住在亚利桑那州的Tucson。
Jeff Jonas是IBM首席科学家、IBM实体分析组(IM Entity Analytics Group)和杰出工程师。IBM实体分析组是基于系统研究和开发的技术成立的,由Jonas在1984年创办,2005年被IBM收购。Jonas的博客是http://jeffjonas.typepad.com。
Jonathan P. Kastellec是普林斯顿大学的政治学教授。他在《Journal of Law》、《Economics&Organization》、《Journal of Empirical Legal Studies》和《Perspective on Politics》发表过论文。
Valdean Klump目前居住在旧金山,是一名作家,在一家创意实验室工作。
Aaron Koblin是一名来自旧金山的艺术家,他的可视化数据项目Flight Patterns、The Sheep Market和Ten Thousand Cents都广为人知。他是视频“House of Cards”的技术主任,当前是一家创意实验室的设计技术带领人。
Coco Krumme是MIT Media Lab的研究生。她同时也为在旧金山的Metaweb Technologies公司工作。
Andrew Lang是Oral Roberts大学的数学教授。他的博士研究领域是弯曲时空的量子理论。在该领域他还很活跃,同时他也喜欢参与跨项目的协作工作,范围从篮球自由投篮建模到在冲击力下的旋转宇宙飞船的稳定性。他当前的研究兴趣包含多维数据可视化、科学和科幻小说的关系、技术和形而上学自然主义在认识论上的区别。
Pierre Lindenbaum 2000年获得病毒学的博士学位,当时他研究virushost交互。后来他转行研究生物信息学,在French National Center of Genotyping工作一年后,他在2001年加入了French startup Integragen。他现在作为生物信息学家,在巴黎的遗传研究中心Fondation Jean Dausset-CEPH工作。
Jayant Madhavan是一名资深软件工程师,是Deep Web爬虫项目计划的技术带领人。在这之前,他是Tranformic公司(2005年被G公司收购)的首席架构师,Tranformic公司为Deep Web发明了搜索引擎。Madhavan博士2005年在华盛顿大学获得计算机专业博士学位。
Michal Migurski是Stamen Design公司的合伙人,同时是该公司的技术和研究方面的带领人。他从1995年开始就一直构建Web,专于处理大规模的、振奋人心的数据集,以及这些数据和大量的客户端的用户进行通信和分发的方式。他公开为学术和工业领域做一些主题讲座,积极参加各种开源开发项目,积极维护Web博客:http://mike.teczno.com。他在加州大学伯克利分校获得学位。
Cameron Neylon是在跨领域工作的生物物理学家,著名的开源研究实践和改进的数据管理的倡导者。他当前作为生物分子科学的资深科学家,在Science and Technology Facilities Council(STFC)的ISIS Neutron Scattering facility工作。在学术研究上,他经常在科学Web技术和成功的(和不成功的)通用和设定设计工具的应用方面发表论文或进行演讲。
Peter Norvig他是AAAI和ACM的会员,合著了《Artificial Intelligence:A Modern Approach》(Pentice Hall出版社)一书,这是在人工智能领域的一流的教材。在这之前,他是NASA计算机科学的负责人、USC和Berkeley的教师。
Brendan O'Connor是机器学习和自然语言处理的研究员。他是Dolores实验室的科学顾问,先前作为相关性技术工程师在Powerset公司工作。他从斯坦福大学获得符号系统学的学士和硕士学位,目前回到学术领域,作为研究生去卡内基梅隆大学就读。他的博客名为“Artificial Intelligence and Social Science”,可以访问:http://anyall.org/blog。
David Poole在AT&T实验室的统计研究部门工作,目前是美国统计协会(Aerican Statistical Association)的统计计算部门秘书和财务主任。他在大规模的数据挖掘方面很有经验,如通信工程的客户呼叫数据分析和欺诈识别。
Raghu Ramakrishnan是雅虎Audience and Cloud Computing的首席科学家,是一名研究员。他在数据库系统的工作——主要研究数据挖掘、查询分析和Web规模的数据管理——影响了商业数据库系统的查询优化和SQL:1999的窗口函数的设计。他的Birch聚类算法论文,获得了SIGMOD 10-Year Test-of-Time奖,他还著有被广泛采用的教材《Database Management Systems》(和Johannes Gehrke合著;McGraw-Hill出版社)。他是ACM SIGMOD的主席,ACM和IEEE的成员。
Toby Segaran是O'Reilly的两本很受欢迎的书:《Programming Collective Intelligence》和最近出版的《Programming the Semantic Web》的作者。他当前在Metaweb工作,在那里他开发了大规模的协调算法,目的是为所有其他公共数据库创建包含共享关键字的免费数据库。在加入Metaweb之前,他成立了生物技术软件公司,2003年被Genstruct收购,Genstruct是系统生物公司。Toby在MIT获得了计算机学士学位,现在和妻子Brooke一起居住在旧金山。在他的博客上你可以读到更多关于他的文章和数据实验:http://blog.kiwitobes.com。
Lisa Sokol当前是IBM全球商务服务组的顾问,专门做实体分析。她的主要研究领域是帮助执法人和情报组织发现深埋在大数据集中的“可采取措施的信息”(Ationable Information)。她架构了大量的系统来检测评估相对于欺诈、恐怖主义、反间谍和犯罪活动的威胁风险。她还帮助开拓了一些技术的应用,如数据挖掘、文本挖掘和机器翻译,用来探索共享情报环境中的可访问信息。Sokol博士在这些领域发表了无数篇论文。她在Massachusetts大学获得操作研究的博士学位。
Utkarsh Srivastava是雅虎研究院的资深研究科学家。他的主要研究领域是构建系统来解决大规模数据管理系统。在开发PNUTS之前,他在开发Pig项目中发挥了重要作用,Pig是在Hadoop之上的描述查询语言。他在斯坦福大学获得了博士学位,在那里他的研究工作是流数据的查询处理和一些查询优化问题。
Deborah Swayne在AT&T实验室的统计研究部门工作,是美国统计协会的成员,统计图形学的ASA部门的前主席。她是已经被广泛使用的多维数据可视化软件ggobi的作者之一。
Jud Valeski是Gnip公司的CTO和创始人之一。Gnip公司致力于开发数据便携式软件。从客户端用户接触的产品到大规模后台基础设施项目,Jud工作了20多年,并乐在其中。他在IBM、Netscape、onebox.com、AOL和me.dium加入过工程师、产品和M&A团队。在发布的由几千万的用户使用的产品中,Jud发挥了重要的作用。
Hadley Wickham是Rice大学的助理教授,研究兴趣是开发工具(包括计算和认知两个方面)使得数据准备、可视化和分析变得简单。他开发了15个统计工具R的工具包,在2006年,由于在ggplot软件上的工作以及重塑了统计工具R的工具包,Hadley获得了统计计算的John Chambers Award。
Antony Williams是ChemZoo公司的总裁,提供ChemSpider服务,为化学家提供在线免费访问服务,目的是为科学家构建以结构为中心的组织。他在商业科学软件领域的Advanced Chemistry Development(ACD/Labs)当了10多年的首席科学官,任期中监督产品开发、市场和销售团队。他是个成就很高的NMR光谱学家,发表了100多篇论文。他曾经是Eastman Kodak Company的NMR技术带头人,在学术领域和政府研究所都工作过。他最近热衷于提供ChemSpider服务,为大众提供化学相关的信息和软件服务。
Egon Willighagen是瑞典Uppsala大学的科学家,主要研究制药生命科学领域的数据分析。他主要研究设计统计方法的开发和生物分子化学计量学和蛋白质化学计量学。他是Chemistry Development Kit和Metware的发布主管,在其他化学信息学开源项目工作了10多年,其中两个项目是Jmol和Bioclipse。
Jo Wood是伦敦城市大学giCentre(http://gicentre.org)地理信息学的读者。他从1990年就一直致力于山水地貌的分析,在GIS上发表了《LandSerf》,用于进行表面视觉探索。作为地理学家和程序员,他在过去几乎10年的时间中一直在用Java开发软件为数据分析问题找到地理可视化的解决方案。他的著作有《Java Programming for Spatial Sciences》(CC)。当不用计算机分析地形地貌时,他经常骑车兜风。
Matt Wood是Wellcome Trust Sanger Institute的产品软件的负责人,在那里他负责驱动该研究所的世界级的序列设备的软件。
Nathan Yau是加州大学洛杉矶分校的统计学博士生,在加州大学伯克利分校获得了电子工程和计算科学的学士学位。他的主要研究兴趣包括数据可视化、自我监督以及数据本身和物理世界如何纠织在一起。深受暑期《New York Times》的图形编辑实习生工作的启发,Yau维护了一个领先的统计学和数据可视化博客:FlowingData(http://flowingdata.com/)。该博客主要涉及设计家、统计学家和计算机科学家如何使用数据帮助我们做出更好的决策。
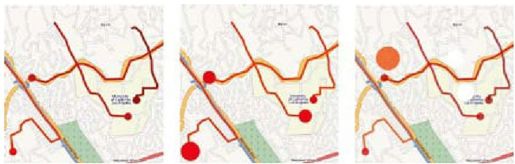
彩图 1(图1-1) 我们在地图上对不同的视觉提示进行实验,通过影响和排放值来最佳展示地理数据。以上展示了我们初始设计的三次迭代。最左边的地图显示根据碳影响所呈现的彩色GPS轨迹;对于中间的地图,我们通过单色的圆圈面(aea circle)来表示影响;对于右边的地图,我们结合了GPS数据来呈现用户什么时候有空,然后重新采用单色的颜色编码方案
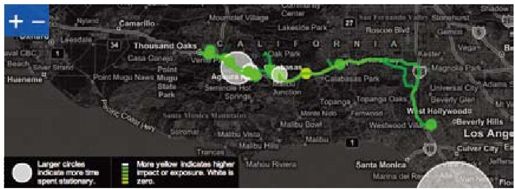
彩图 2(图1-2) 在当前的映射机制中,我们采用颜色过滤器来高亮显示数据。地图仅仅是提供上下文信息。链接的直方图显示映射后的数据的影响和排放值分布。当用户通过滚动条看直方图的某一栏,相应的GPS数据会在地图上高亮显示

彩图 3(图1-4) PEIR的Facebook应用允许用户分享他们对影响和排放值的发现,以及与朋友的进行比较
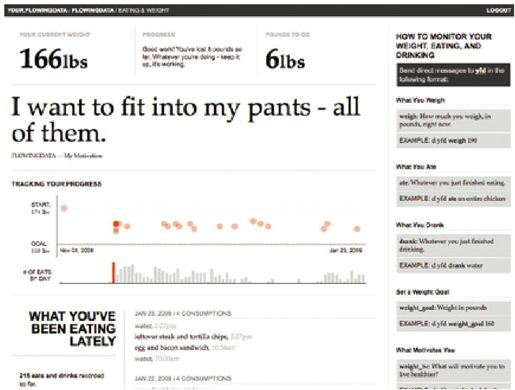
彩图 4(图1-5) 人们为不同原因跟踪他们的体重和饮食。YFD把这些动机作为用户界面的焦点
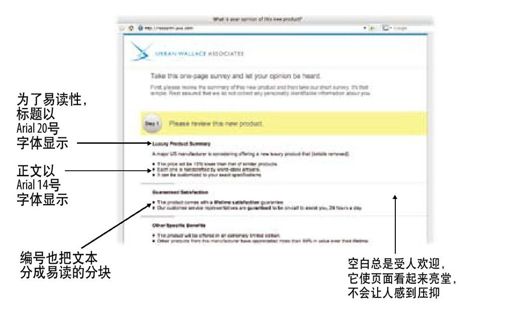
彩图 5(图2-2) 为易读性而设计
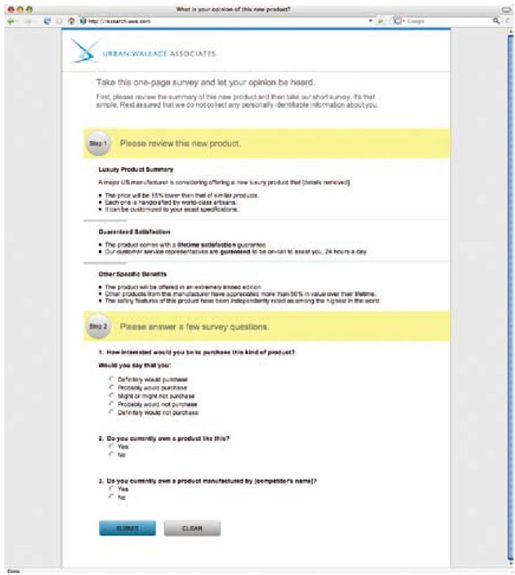
彩图 6(图2-3) 调查开始只有3个问题
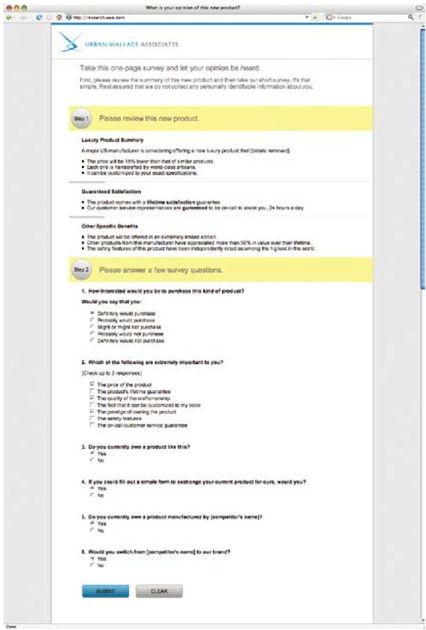
彩图 7(图2-4) 基于用户输入,调查可能会扩展到6个问题

彩图 8(图2-5) 调查细节——当用户对问题1回答“Yes”时
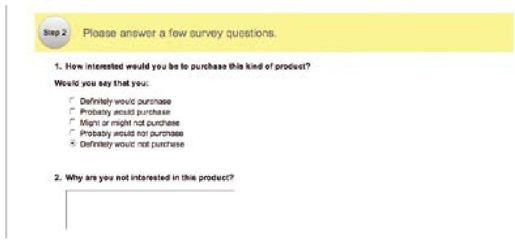
彩图 9(图2-6) 调查细节——当用户对问题1回答“No”时

彩图 10(图3-1) 凤凰号火星探测器在火星上的着陆效果图(图像来源:美国航空航天局和喷气推进实验室NASA/JPL)

彩图 11(图3-2) 立体表面成像器(图像来源:Arizona大学/NASA/JPL)

彩图 12(图6-1) Aberuchill附近的小路。远处是Bioran Dalchonzie。这是Geograph项目的网站出现的第100万张图片(htp://www.geograph.org.uk/photo/1006884)。图片版权归Dr.Richard Murray所有,由Creative Commons License(http://creativecommons.org/licenses/by-sa/2.0/)授权使用

彩图 13(图6-2) Norfolk海岸的地理马赛克图。每个图片都是根据其地理位置进行映射,表示了1平方公里的景观。图片由Creative Commons License(http://creativecommons.org/licenses/by-sa/2.0)授权使用

彩图 14(图6-4) 对于六种选定的场景类型,其出现在地理标题和评论的描述的树形图。节点大小表示术语的出现频率。颜色突出了包含一种继承随机方案的场景类型/刻面(fcet)/描述符分类。布局采用“有序的方块化”方法来维持节点之间的方块形状

彩图 15(图6-5) 对于六种选定的场景类型,其出现在地理标题和评论的描述的树形图。节点大小表示术语出现频率。颜色突出了包含一种继承的随机方案的场景类型/刻面/描述符分类。布局采用“切片和切块”的方法来增强维度(上图)间的比较和“切片和切块/有序的方块化”方法来改进标注的可读性,如下部的图

彩图 16(图6-6) “有序的方块化”树形图,其颜色是通过CIELab颜色模型的一种色彩空间来显示绝对的地理位置,在该空间中,主观感觉到的颜色区别和地理位置的差异紧密相关

彩图 18(图6-8) 对于六种选定的场景类型,其出现在地理标题和评论的描述的空间树形图。节点大小表示词频,颜色表示使用CIELab方案的绝对空间地理位置。位移向量表示非叶子节点的绝对地理位置如场景类型、刻面和描述符

彩图 17(图6-7) “有序的方块化”树形图,通过CIELab色彩空间的颜色显示绝对的地理位置。包含描述符节点的叶子节点,使用空间有序算法,通过地理位置做关联排序

彩图 19(图6-9) 对于六种选定的场景类型,其出现在地理标题和评论的词汇的空间树形图。位移向量表示非叶子节点的绝对地理位置(共现词),并提供了关于位移的空间聚类和空间趋势的信息来满足树形图的空间填充目标

彩图 20(图6-10) 在beach基础区块中出现的对选定元素的描述符在地理标题和评论中出现的术语的空间树形图。位置向量表示图6-9中放大部分的叶子节点的绝对地理位置
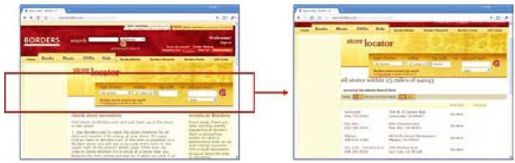
彩图 21(图9-1) Borders商店定位表单和提交特定表单得到的Deep Web结果页
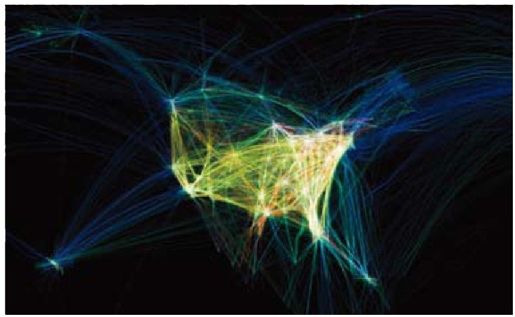
彩图 22(图10-1) 来自“飞行模式”的静态图片(2005)

彩图 23(图10-3) 派对场景的一张静态图片,通过Velodyne的Lidar拍摄。注意该图片上方的分辨率更高,这是由于在上斜岸的激光的触发速率更快
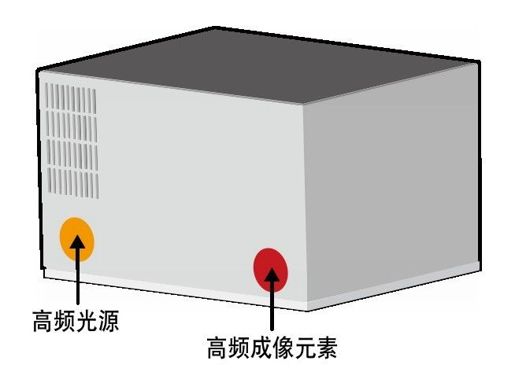
彩图 24(图10-4) Geometric Informatics系统(图像来源:Geometric Informatics公司)

彩图 25(图10-5) Velodyne Lidar的一个激光器捕捉到的数据

彩图 26(图10-6) Velodyne Lidar捕捉到的另一幅景观图片

彩图 27(图10-7) 派对场景的一个静态图片,Velodyne Lidar捕捉,数据有64条线,每条线由Lidar的一个激光器生成

彩图 28(图10-8) 歌手Thom Yorke在Radiohead视频中的一张静态图片
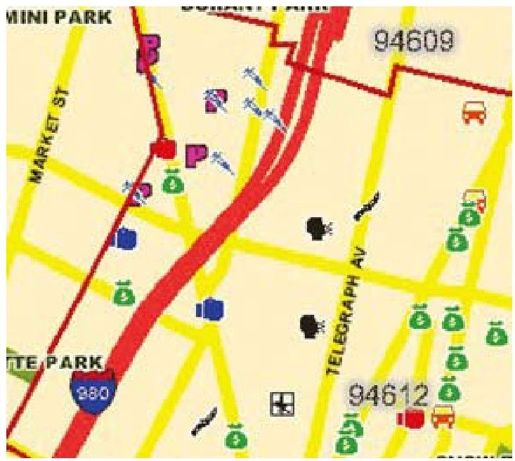
彩图 29(图11-2) CrimeWatch的样本数据显示了盗窃、毒品、抢劫、盗窃车辆等犯罪活动
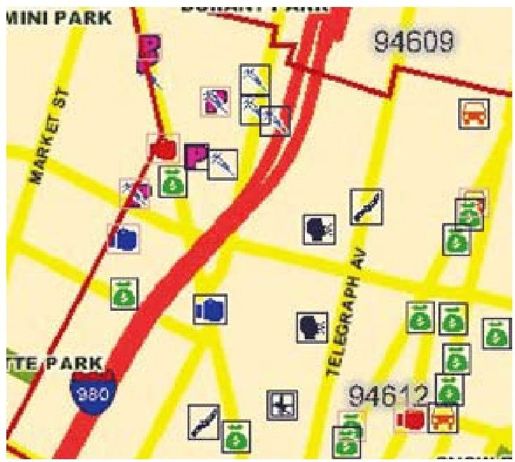
彩图 30(图11-3) CrimeWatch相同的样本数据,突出显示了程序可识别的图标
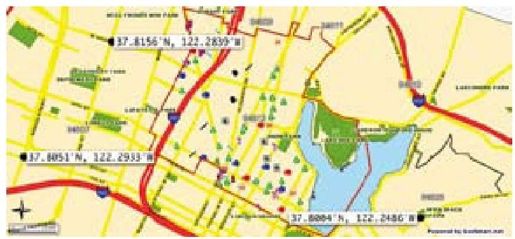
彩图 31(图11-5) 奥克兰商业区地图,为三角测量所显示的三个参照点
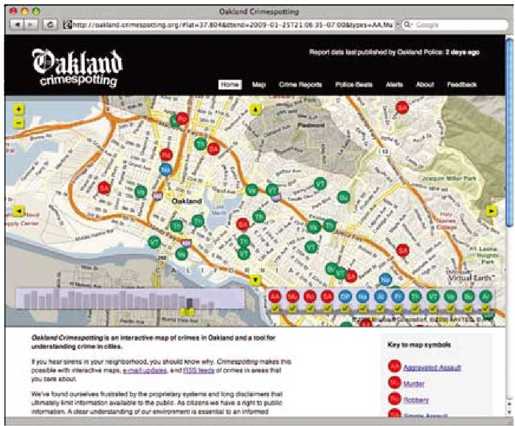
彩图 32(图11-6) 奥克兰Crimespotting项目的主页显示了从上周开始的犯罪报告地图
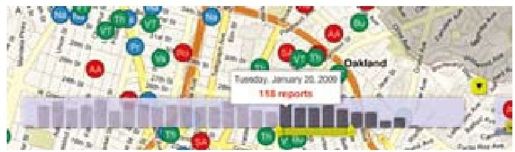
彩图 33(图11-7) Crimespotting的主地图上的时间选择器界面
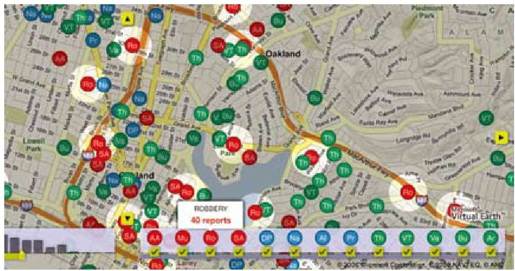
彩图 34(图11-8) 类型选择器显示了在选定时间范围内的每种报告类型的总数
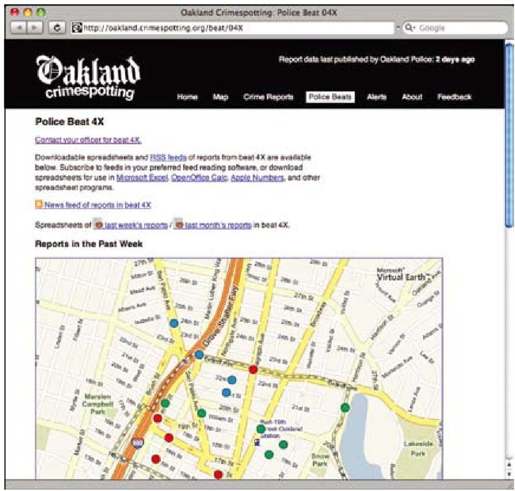
彩图 35(图11-10) 巡警区专用页面允许居民为在当地巡逻的警官提供反馈
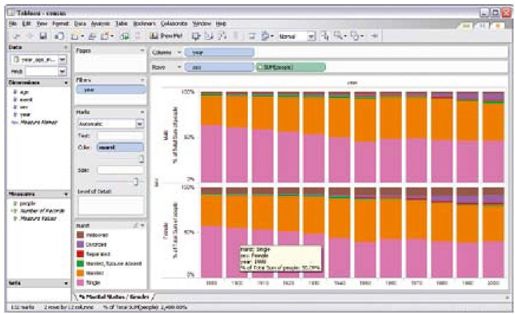
彩图 36(图12-3) 使用Tableau工具构建的显示几十年间婚姻状态分布的原型系统可视化
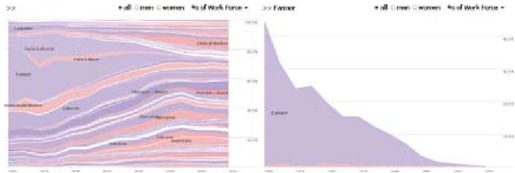
彩图 37(图12-4) 工作向导可视化:左图显示在过去150年间劳动力组成概要视图,右图显示过滤后农民工的比例的视图

彩图 38(图12-5) 出生地向导可视化:左图显示在过去150年间出生地的分布概要,右图显示过滤后欧洲移民的总数的视图
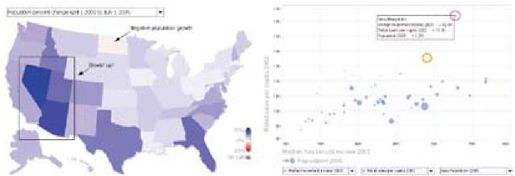
彩图 39(图12-6) (左图)交互式国家地图显示每个州2000~2005年的人口变化,(右图)美国散点图显示了平均家庭收入(x轴)和零售额(y轴),新罕布什尔州和特拉华州有最高的零售额

彩图 40(图12-7) 人口金字塔可视化:(左图)2000年的每个年龄组的男性和女性的总人口数量的比较,(右图)2000年学校出席人数的分布(标注重点突出了成人教育的流行率)
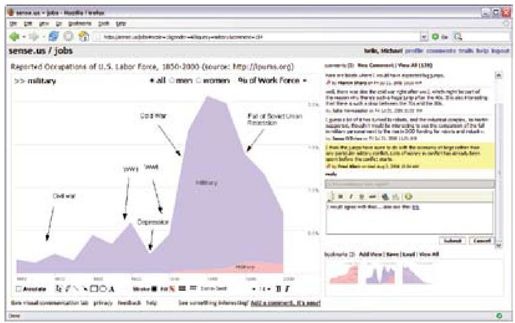
彩图 41(图12-8) sense.us协作式可视化系统:a)交互式可视化应用小程序,图形化标注出当前选定的评论。该可视化是按照性别划分的美国劳动力人数的叠加式时间序列可视化。该图显示了军事职位的劳动力比率;b)一组图形化标注工具;c)保存的视图书签索引;d)添加评论的文本入口区域。可以拖动书签到文本区域,为评论中的视图增加链接;e)在当前视图添加相同主题的评论;f)该应用当前状态对应的URL。该URL随着可视化状态变化自动更新
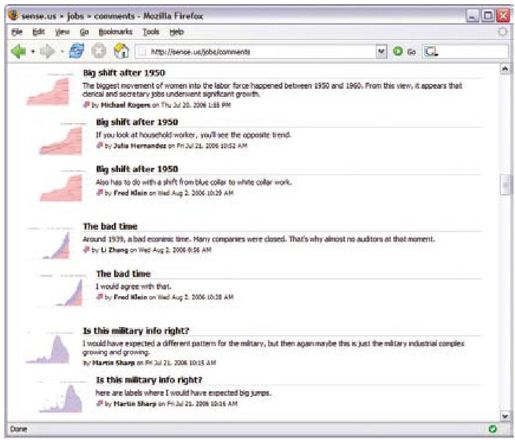
彩图 42(图12-9) sense.us评论列表页面,评论列表显示可视化的所有评论,提供链到评论的可视化视图的链接
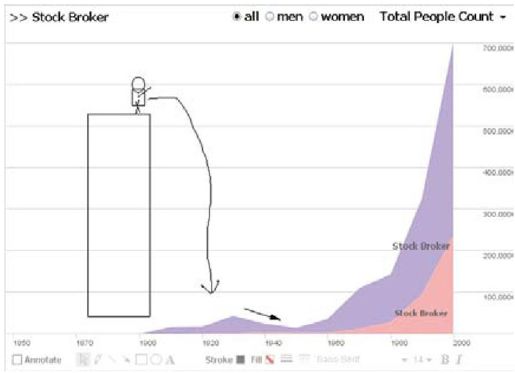
彩图 43(图12-10) 股票经纪人的标注视图;其评论意思是“大萧条‘杀死’了很多经纪人”
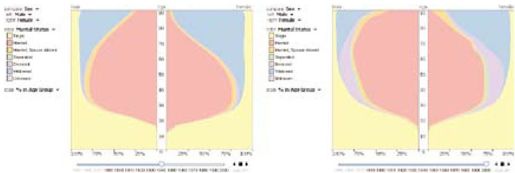
彩图 44(图12-11) 人口金字塔显示在1940年(左图)和2000年(右图)每个年龄组的婚姻状态分布
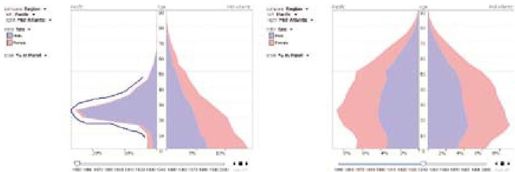
彩图 45(图12-12) 人口金字塔比较了在1850年(左图)和1940年(右图)西海岸和大西洋中部地区的人口
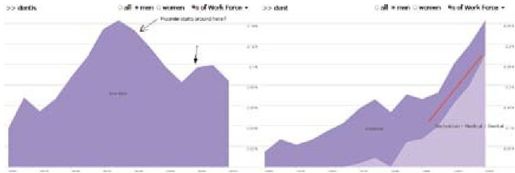
彩图 46(图12-13) 标注的工作向导视图(左图)突出显示了1930年后牙医人数的减少,(右图)由于牙医人员排序的上升,牙医从业人数得到增长
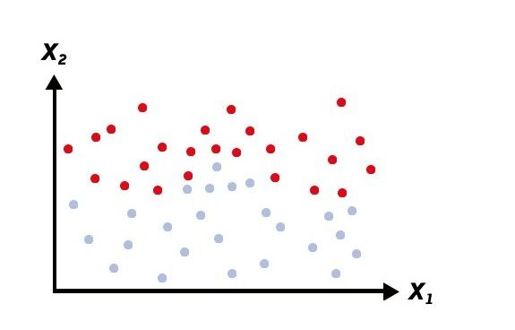
彩图 47(图13-2) 我们可以构建模型来区分两组数据集
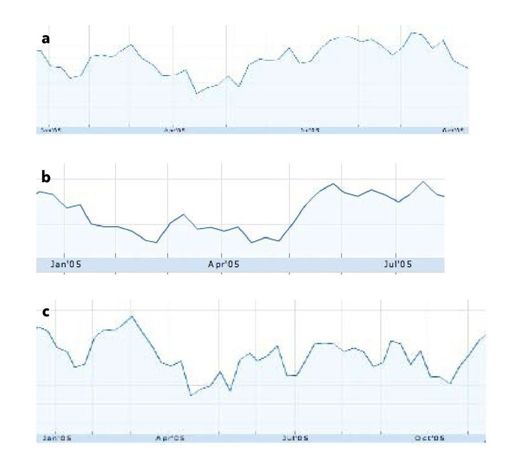
彩图 48(图13-3) 三只股票(a、b和c)在2005年的业绩
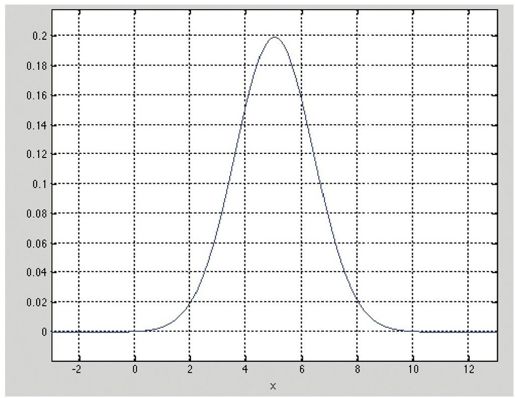
彩图 49(图13-4) 正态分布
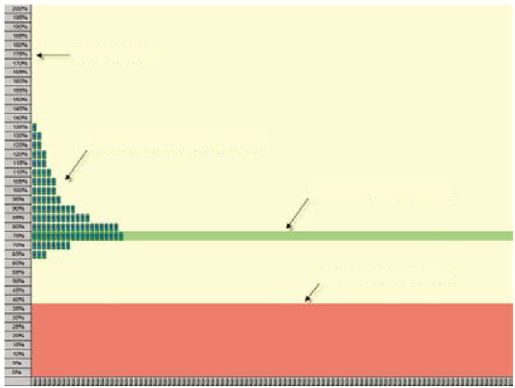
彩图 50(图13-6) Goldstein等开发的工具帮助人们理解作为一组结果的分布
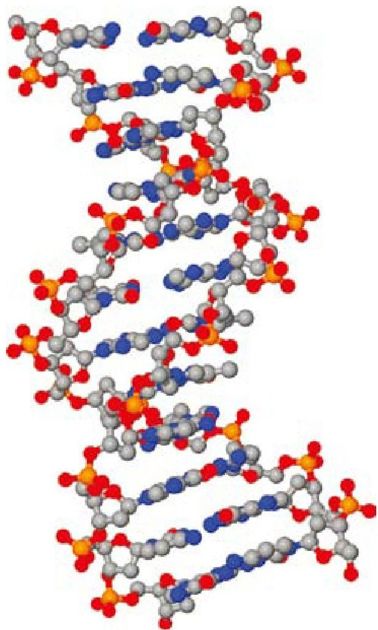
彩图 51(图15-1) DNA中的一个小片段,由POV-Ray软件从PDB文件1BNA生成,doi:10.2210/pdb1bna/pdb
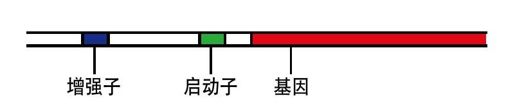
彩图 52(图15-2) 图示为一个DNA片段,其中包含一个基因,以及基因周围用来和细胞调控机制相互作用来限制基因表达的区域。这里基因由一个启动子和一个增强子引导,这样基因就被做了标记,使得细胞知道何时应当表达该基因

彩图 53(图16-1) 使用免费通用服务来托管实验工作记录及处理过的数据。A)单个实验测量时期的一部分;B)Flickr上实验中所拍照片;C)托管在Gdoc上主要数据仓库的一部分
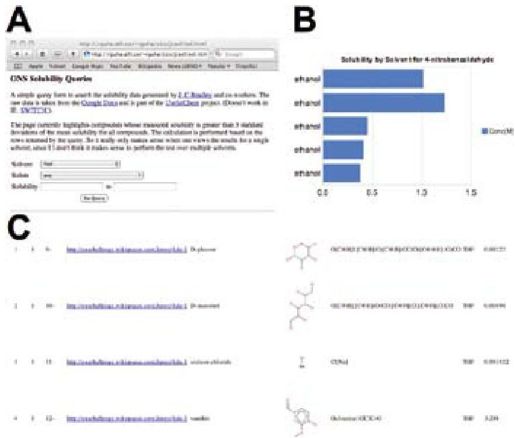
彩图 54(图16-2) 用于检视溶解度数据的可视化工具。A)采用JavaScript和G公司Doc API生成的一个简单表单输入界面;B)溶解度数值的图形化表示;C)带有二维化学结构渲染图的数据表格输出。可以从http://toposome.chemistry.drexel.edu/~rguha/jcsol/sol.html访问此服务。请注意:本服务与这里提到的其他服务都是动态的,可能得到与上图所示不同的查询结果
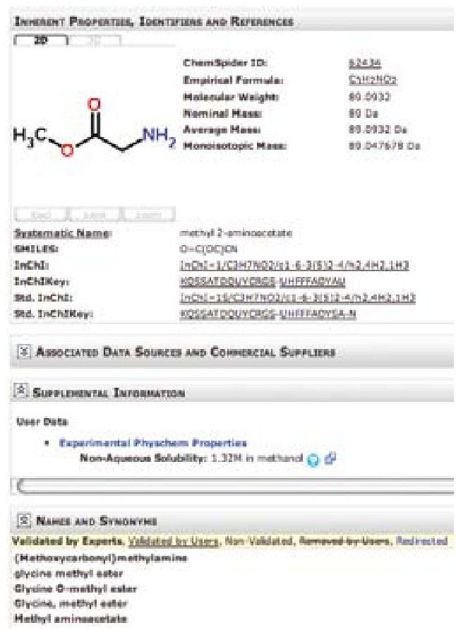
彩图 55(图16-3) 这是ChemSpider条目显示溶解度数据与原始数据链接的例子
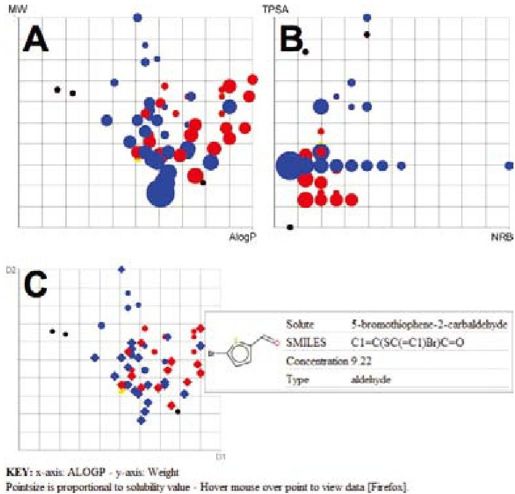
彩图 56(图16-5) 化学空间溶解度数据的图表展示。A和B给出了同一数据组在表示不同化学特性的数轴上的两个可视化图表。点的颜色表示化合物的类型(红色的为醛类,蓝色为羧酸类,黄色的为胺类,黑色表示其他),点的大小表示溶解度的值。C显示了可点击的界面,其中有单个数据点的化合物结构和溶解度值
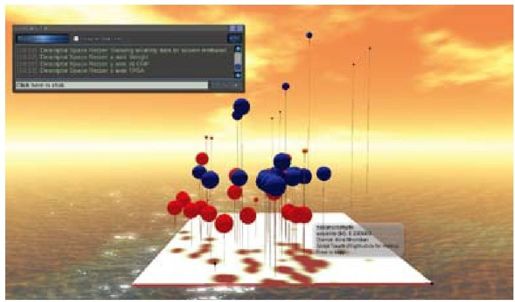
彩图 57(图16-6) 使用Second Life展示多维数据。三个空间轴分别表示三个化学描述符。球的颜色表示化合物的类别(和图16-5的定义一样),球的大小表示在当前溶剂中的溶解度。此可视化图表可以在http://slurl.com/secondlife/Drexel/165/178/24找到,即Second Life中的Drexel岛
彩图 58(图17-1) FaceStat的评判界面
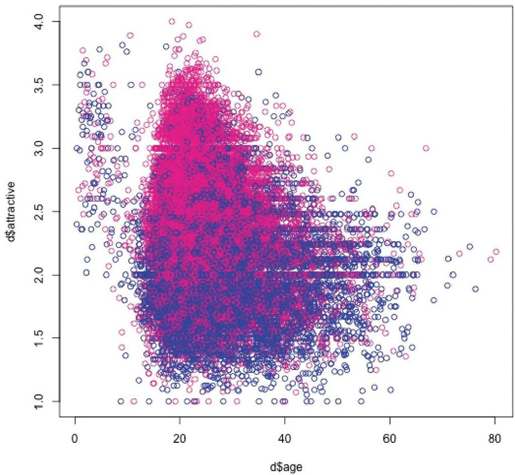
彩图 59(图17-5) 魅力和年龄关系的散点图,通过性别进行着色
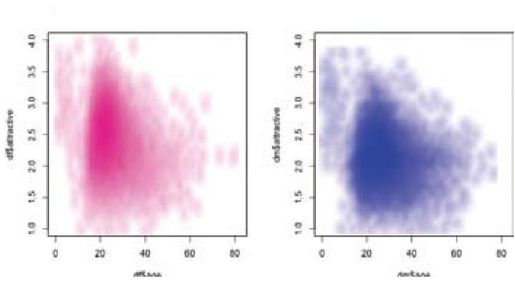
彩图 60(图17-6) 魅力和年龄关系的平滑散点图,每个性别一个图
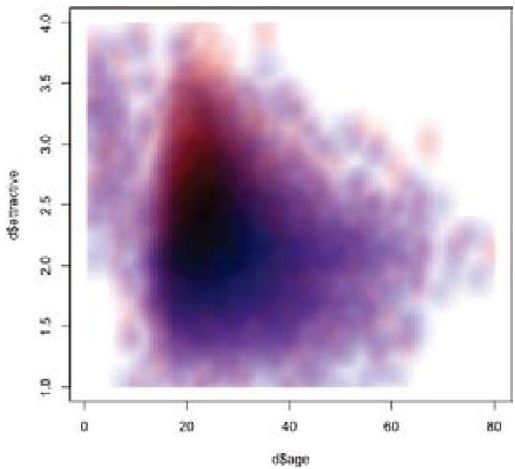
彩图 61(图17-7) 魅力和年龄关系的平滑散点图,通过性别着色,在一张图上交叠显示
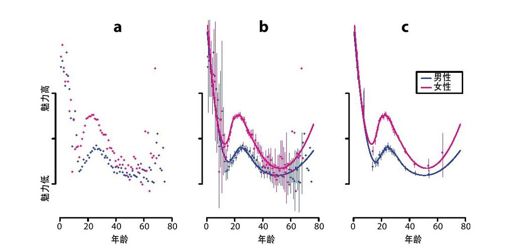
彩图 62(图17-8) 魅力和年龄以及性别的关系的三种迭代绘图:a)平均值在桶内区间的每个年龄;b)每个桶95%置信区间,以及局部加权回归曲线;c)更大的桶,其中数据更稀疏
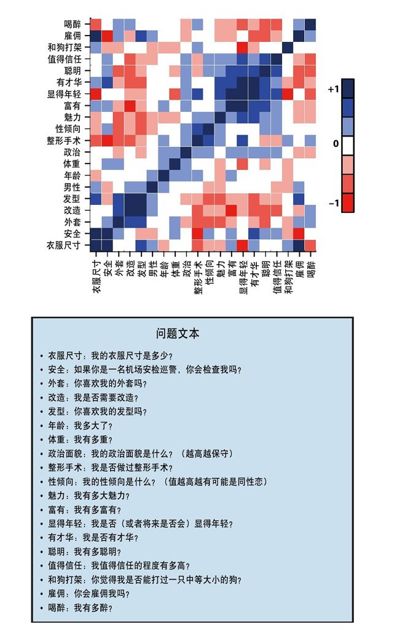
彩图 63(图17-9) Pearson关联矩阵,蓝色方块的属性对和上升的斜线是正向关联,而红色方块的属性对和下降的斜线是逆相关
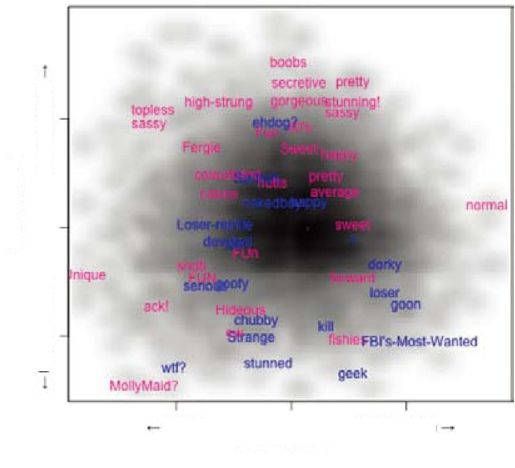
彩图 64(图17-12) 基于平滑后的魅力与年龄描绘的标签样本图
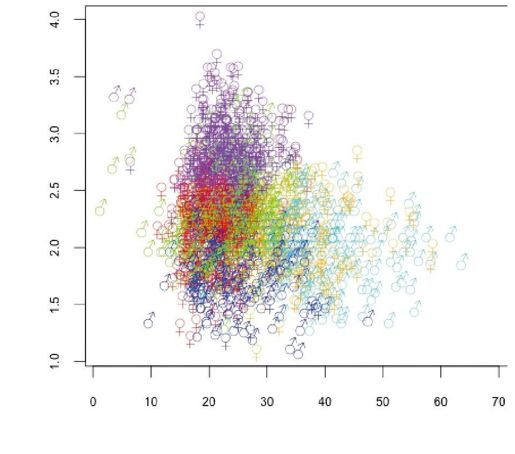
彩图 65(图17-13) 魅力和年龄的关系,通过集群着色,显示了包含2000个点的子样本

彩图 66(图17-15) 集群的质心点、标签和例子
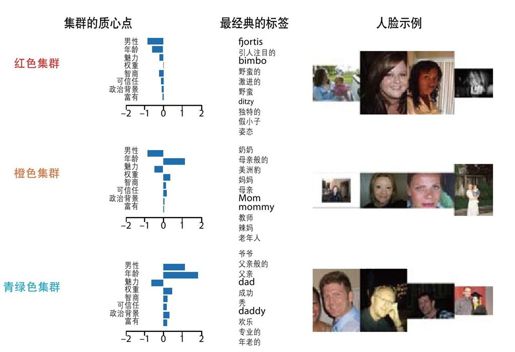
彩图 67(图17-16) 集群的质心点、标签和例子
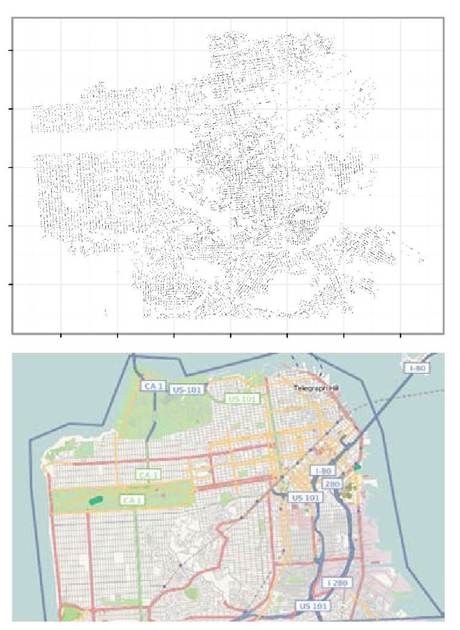
彩图 68(图18-13) (上图)对于数据中的每个住宅销售都画出了一个小点,它给我们非常好的旧金山布局的感觉;(下图)为了比较,显示的是一张旧金山的街道地图,来自http://openstreetmap.com
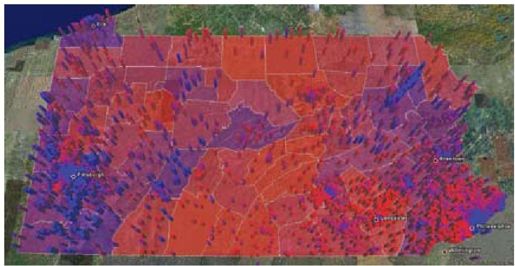
彩图 69(图19-5) 宾夕法尼亚州的地理党派。基础层显示了根据2004年总统竞选公布的数据对宾夕法尼亚州进行的分块着色显示,蓝色表示对民主党候选人John Kerry的支持度更高,红色表示对共和党候选人George W.Bush的支持度更高,而紫色分区表示介于这二者之间。分散的柱面图表示对于该州4000个随机注册的投票人的本地党派,定义为居住在1公里范围内支持民主党的人们的概率。每个圆柱面都是基于在投票人的住宅为中心,1公里范围内为界限,因此复制该党派衡量方式的区域。蓝色圆柱面表示更支持民主党的地区——这次考虑个人层次的注册——红色圆柱面表示更支持共和党的地区,而紫色表示介于二者之间的区域。该图之美在于它显示了在国家级别、州级别,甚至是县级别,红区和蓝区的思想观念的复杂性
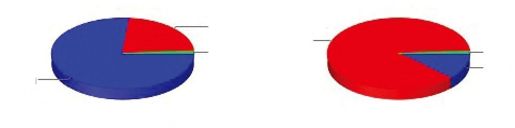
彩图 70(图20-1) 证券交易委员会的数据和责任政治中心提供的政治贡献相关的数据的饼图
