1.5.3 Hadoop Eclipse插件介绍
Hadoop提供了一个Eclipse插件以方便用户在Eclipse集成开发环境中使用Hadoop,如管理HDFS上的文件、提交作业、调试MapReduce程序等。本小节将介绍如何使用该插件访问HDFS、运行MapReduce作业和跟踪MapReduce作业运行过程。
1.编译生成Eclipse插件
用户需要自己生成Eclipse插件。Hadoop-1.0.0生成的jar包不能直接使用,需要进行部分修改,具体参考附录A中的问题2,其代码位于Hadoop安装目录的src/contrib/eclipse-plugin下,在该目录下,输入以下命令生成Eclipse插件:
ant-Declipse.home=/home/dong/eclipse-Dversion=1.0.0
其中,eclipse.home用来指定Eclipse安装目录,version是Hadoop版本号。${HADOOP_HOME}/build/contrib目录下生成的hadoop-eclipse-plugin-1.0.0.jar文件即为Eclipse插件。
2.配置Eclipse插件
将生成的Eclipse插件hadoop-eclipse-plugin-1.0.0.jar复制到Eclipse安装目录的plugins文件夹下,然后重启Eclipse。
进入Eclipse后,按照以下步骤进行设置:在菜单栏中依次单击“Window”→“Show View”→“Other……”,在对话框中依次单击“MapReduce Tools”→“Map/Reduce Locations”,会弹出图1-13a所示的对话框,按图中提示填写内容。
经上述步骤后,回到主界面,如图1-13b所示,可在“Project Explore”视图中查看分布式文件系统的内容,说明Eclipse插件安装成功。
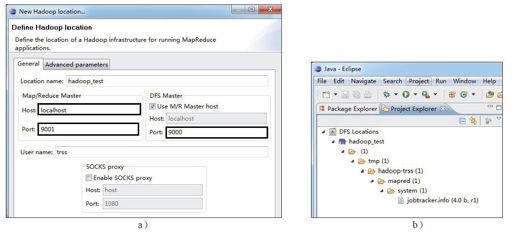
图 1-13 配置Hadoop Eclipse插件
a)配置MapReduce和HDFS的主机名和端口号 b)显示HDFS中的文件列表
3.运行MapReduce作业
前面提到,在伪分布式环境下,单个节点上会同时运行多种Hadoop服务。为了跟踪这些服务的运行轨迹,我们采用了以下方法:向Hadoop提交一个MapReduce作业,通过跟踪该作业的运行轨迹来分析Hadoop的内部实现原理。
该方法可通过以下三个步骤完成:
步骤1 新建一个MapReduce工程。在菜单栏中,依次单击“New”→“Other…”→“MapReduce Project”,会弹出图1-14所示的对话框。在该对话框中填写项目名称,并配置Hadoop安装目录,此处可直接选择前面已经建好的Java工程“hadoop-1.0.0”。
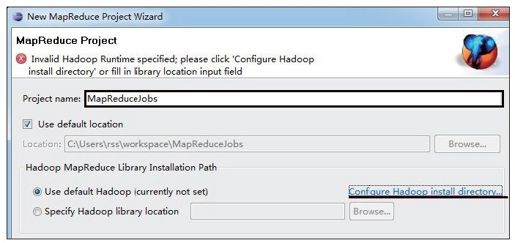
图 1-14 在Eclipse中创建MapReduce工程
步骤2 准备MapReduce作业。可直接将Hadoop源代码中src\examples\org\apache\hadoop\examples目录下的WordCount.java复制到新建的MapReduceJobs工程中。
步骤3 运行作业。
1)准备数据。如图1-15所示,在HDFS上创建目录/test/input,并上传几个文本文件到该目录中。
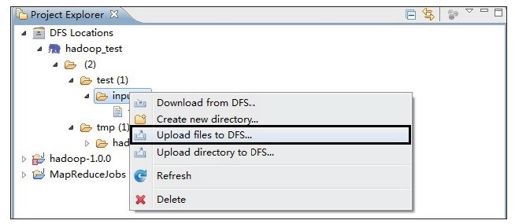
图 1-15 使用Eclipse插件上传文件到HDFS
2)配置输入/输出路径。如图1-16所示,在WordCount.java中右击,在弹出的快捷菜单中依次单击“Run As”→“Run Configurations……”,会出现图1-17所示的对话框。双击“Java Applications”选项,在新建的对话框中输入作业的输入/输出路径(中间用空格分隔),并单击“Apply”按钮保存。
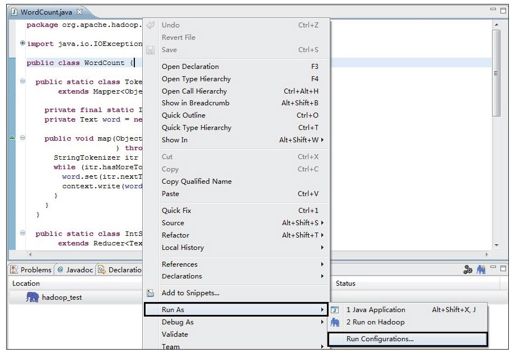
图 1-16 在Eclipse中配置作业的输入/输出路径(1)
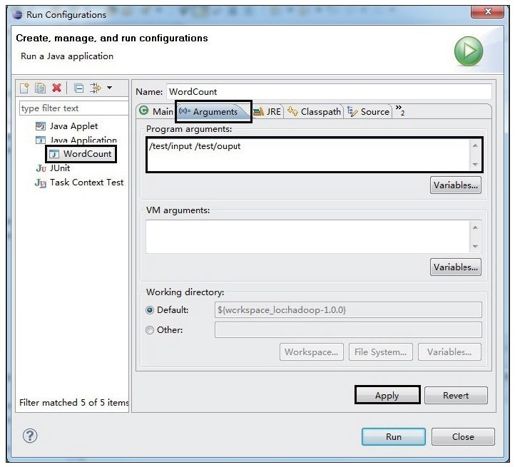
图 1-17 在Eclipse中配置作业的输入/输出路径(2)
3)运行作业。在WordCount.java中右击,在弹出的快捷菜单中依次单击“Run As”→“Run on Hadoop”,会出现如图1-18所示的对话框。按图中的提示选择后,单击“Finish”按钮,作业开始运行。
此外,有兴趣的读者可以在MapReduce作业中设置断点,对作业进行断点调试。
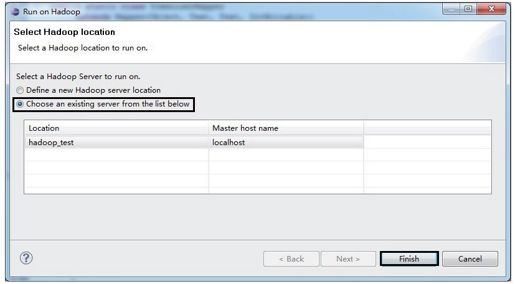
图 1-18 在Eclipse中运行作业
