6.5.2 TaskTracker容错
TaskTracker负责执行来自JobTracker的各种命令,并将命令执行结果定时汇报给它。在一个Hadoop集群中,TaskTracker数量通常非常多,设计合理的TaskTracker容错机制对于及时发现存在问题的节点显得非常重要。Hadoop提供了三种TaskTracker容错机制,分别是超时机制、灰名单与黑名单机制和Exclude list与Include list。
1.超时机制
超时机制是一种在分布式环境下常用的发现服务故障的方法。如果一种服务在一定时间未响应,则可认为该服务出现了故障,从而启动相应的故障解决方案。Hadoop也采用了类似的方法发现出现故障的TaskTracker,具体如下:
❑TaskTracker第一次汇报心跳后,JobTracker会将其放入过期队列trackerExpiryQueue中,并将其加入网络拓扑结构中。
❑TaskTracker以后每次汇报心跳,JobTracker均会记录最近心跳时间(TaskTrackerStatus.lastSeen)
❑线程expireTrackersThread周期性地扫描过期队列trackerExpiryQueue,如果发现某个TaskTracker在10分钟(可通过参数mapred.tasktracker.expiry.interval配置)内未汇报心跳,则将其从集群中移除。
移除TaskTracker之前,JobTracker会将该TaskTracker上所有满足以下两个条件的任务杀掉,并将它们重新加入任务等待队列中,以便被调度到其他健康节点上重新运行。
条件1 任务所属作业处于运行或者等待状态。
条件2 未运行完成的Task(包括Map Task和Reduce Task)或者Reduce Task数目不为零的作业中已运行完成的Map Task。
注意 所有运行完成的Reduce Task和无Reduce Task的作业中已运行完成的Map Task无须重新运行,因为它们将结果直接写入HDFS中;而包含Reduce Task的作业中已运行完成的Map Task仍需重新运行,因为正常的TaskTracker无法通过HTTP获取死亡TaskTracker上的本地磁盘数据,具体原理可参考第7章。
2.灰名单与黑名单机制
这两种名单中的TaskTracker均不可以再接收作业,也就是,被宣判死亡(尽管可能还活着,但由于短时间内性能表现“太差”,JobTracker不得不让它“休息”一会)。
通过启发式算法推断出存在问题的TaskTracker被加入灰名单,一段时间之后,这些TaskTracker将重新获得一次接收任务的机会。
通过用户设定的脚本监控发现存在问题的TaskTracker被加入黑名单,这些TaskTracker不会再“复活”,直到监控脚本发现TaskTracker又活过来了。
(1)灰名单
每个作业在运行过程中会动态生成TaskTracker黑名单(一个TaskTracker列表),而位于黑名单中的TaskTracker将不会再有运行该作业的任何任务的机会。TaskTracker黑名单生成的方法是,作业在运行过程中记录每个TaskTracker使其失败的Task Attempt数目,一旦该数目超过mapred.max.tracker.failures(默认是4),对应的TaskTracker会被加入该作业的黑名单中。
JobTracker将记录每个TaskTracker被作业加入黑名单的次数#blacklist。当某个TaskTracker同时满足以下条件时,将被加入JobTracker的灰名单中:
条件1 #blacklist大小超过mapred.max.tracker.blacklists值(默认为4)。
条件2 该TaskTracker的#blacklists大小超过所有TaskTracker的#blacklist平均值的mapred.cluster.average.blacklist.threshold(默认是50%)倍。
条件3 当前灰名单中TaskTracker的数目小于所有TaskTracker数目的50%。
JobTracker为每个潜在存在问题的TaskTracker(#blacklist大于0)维护了一个环形桶数据结构。该数据结构保存了最近一段时间内TaskTracker对应的#blacklist值,由于该值随着时间推移不断变化,因此TaskTracker可能会不断进出灰名单。
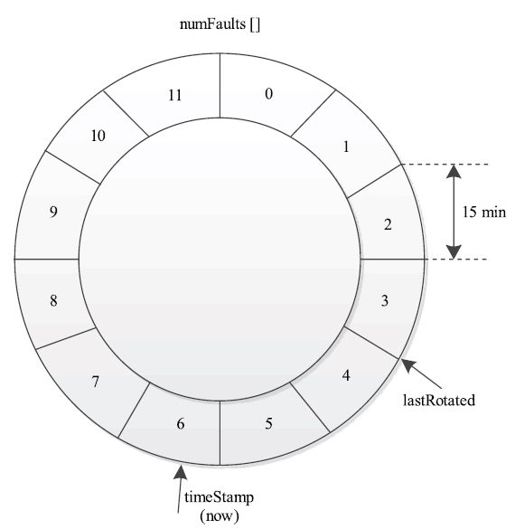
图 6-6 环形桶数据结构
一个典型的环行桶数据结构(具体参考类JobTracker.FaultInfo)如图6-6所示。默认情况下,它维护了最近mapred.jobtracker.blacklist.fault-timeout-window(默认是3小时)时间内某个TaskTracker对应的#blacklist值。为了便于计算,环形桶被分成若干个等时间片(由参数mapred.jobtracker.blacklist.fault-bucket-width配置,默认是15分钟)长度的桶,所有桶的#blacklist值由整型数组numFaults[]维护,同时由指针lastRotated指向最近一次更新所在桶的第1个毫秒位置,具体操作如下:
❑初始化操作:
lastRotated=(time/bucketWidth)bucketWidth;/其中,time为当前时间,
bucketWidth为桶宽度,经初始化后,lastRotated是bucketWidth的整数倍*/
❑checkRotation操作:将lastRotated到某个新时间点timeStamp之间的桶计数器(#blacklist)清零,同时将lastRotated移动到新时间点对应的桶第一毫秒所在位置。
void checkRotation(long timeStamp){
long diff=timeStamp-lastRotated;
while(diff>bucketWidth){
//lastRotated指向时间最久的桶(它即将成为最新的桶)第一个毫秒的位置
lastRotated+=bucketWidth;
//取得桶下标
int idx=(int)((lastRotated/bucketWidth)%numFaultBuckets);
//清空桶计数器,为写入新值做准备
numFaults[idx]=0;
diff-=bucketWidth;
}
}
❑incrFaultCount操作:将某个时间点对应的桶计数器加1,对应代码如下。
void incrFaultCount(long timeStamp){
checkRotation(timeStamp);//将lastRotated~timeStamp时间段内桶计数器清零
++numFaults[bucketIndex(timeStamp)];
}
int bucketIndex(long timeStamp){
return(int)((timeStamp/bucketWidth)%numFaultBuckets);
}
(2)黑名单
Hadoop允许用户编写一个脚本(health check script)[1]监控TaskTracker是否健康(TaskTracker可能仍然活着,但是不健康,比如资源耗光、关键服务挂掉等),并由TaskTracker通过心跳将该脚本的检测结果汇报给JobTracker,一旦发现不健康,JobTracker会将该TaskTracker加入黑名单中,此后不再向其分配任务,直到脚本检测结果为健康。具体实现见7.3节。
3.Exclude list与Include list
Exclude list是一个非法节点列表,所有位于该列表中的节点将无法与JobTracker连接(在RPC层抛出异常)。Include list是一个合法节点列表(类似于节点白名单),只有位于该列表中的节点才允许向JobTracker发起连接请求。默认情况下,这两个列表是空的,表示允许任何节点接入JobTracker。这两个名单中的节点均由管理员配置,并可以动态加载生效。
管理员可在配置文件mapred-site.xml中配置Exclude list和Include list,一个简单的实例如下:
<property>
<name>mapred.hosts</name>
<value>/etc/hadoop_hosts/include_hosts</value>
<description>合法节点所在文件,如果文件为空或者未配置,则表示所有节点均合法。</description></property>
<property>
<name>mapred.hosts.exclude</name>
<value>/etc/hadoop_hosts/exclude_hosts</value>
<description>非合法节点所在文件,如果文件为空或者未配置,则表示所有节点均合法。</description></property>
其中,include_hosts和exclude_hosts两个文件均保存了一个节点host列表,实例如下:
node0000
node0001
node0002
注意 黑名单与非法节点列表是两个不同的概念,区别主要有两个。
❑范围不同:黑名单是TaskTracker级别的,而非法节点列表是host(一个host上可以有多个TaskTracker)级别的。
❑任务运行结果不同:如果一个TaskTracker被动态添加到黑名单中,则它上面正在运行的任务可以正常运行结束(但不会为之分配新任务),但被加入非法节点列表的节点则不同,它上面所有正在运行的任务将无法成功运行完成。
综上所述,影响一个Hadoop集群中TaskTracker数量的因素如图6-7所示,管理员可根据需要,将一些节点动态加入集群或者移出集群,以更好地维护Hadoop集群或者提升它的计算能力。
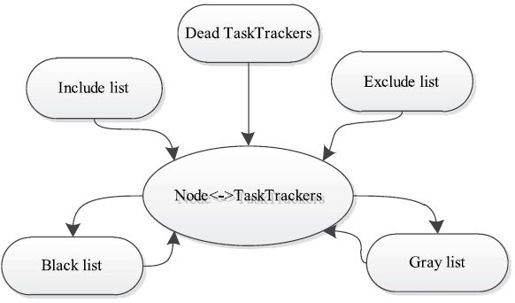
图 6-7 Hadoop集群中TaskTracker数量变化影响因素
[1]https://issues. apache.org/jira/browse/MAPREDUCE-211
