10.4.2 Capacity Scheduler实现
1.Capacity Scheduler整体架构
第5章中已经讲了作业从提交到调度所经历的几个步骤。对于Capacity Scheduler而言,JobTracker启动时,会自动加载调度器类org.apache.hadoop.mapred.CapacityTaskScheduler(管理员需在参数mapred.jobtracker.taskScheduler中指定),而CapacityTaskScheduler启动时会加载自己的配置文件capacity-scheduler.xml,并向JobTracker注册监听器以随时获取作业变动信息。待调度器启动完后,用户可以提交作业。如图10-3所示,一个作业从提交到开始调度所经历的步骤大致如下:
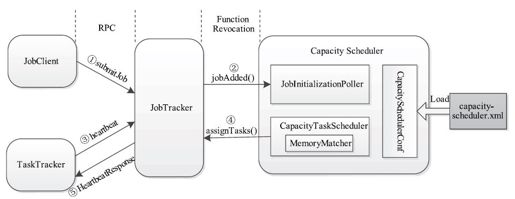
图 10-3 作业从提交到开始调度的整个过程
步骤1 用户通过Shell命令提交作业后,JobClient会将作业提交到JobTracker端。
步骤2 JobTracker通过监听器机制,将新提交的作业同步给Capacity Scheduler中的监听器JobQueuesManager;JobQueuesManager收到新作业后将作业添加到等待队列中,由JobInitializationPoller线程按照一定的策略对作业进行初始化。
步骤3 某一时刻,一个TaskTracker向JobTracker汇报心跳,且它心跳信息中要求JobTracker为其分配新的任务。
步骤4 JobTracker检测到TaskTracker可以接收新的任务后,调用CapacityTaskScheduler.assignTasks()函数为其分配任务。
步骤5 JobTracker将分配到的新任务返回给对应的TaskTracker。
接下来将重点介绍作业初始化和作业调度相关实现。
2.作业初始化
一个作业经初始化后才能够进一步得到调度器的调度而获取计算资源,因此,作业初始化是作业开始获取资源的前提。一个初始化的作业会占用JobTracker内存,因此需防止大量不能立刻得到调度的作业被初始化而造成内存浪费。Capacity Scheduler通过优先初始化那些最可能被调度器调度的作业和限制用户初始化作业数目来限制内存使用量。
由于作业经初始化后才能得到调度,因此,如果任务初始化的速度慢于被调度速度,则可能会产生空闲资源等待任务的现象。为了避免该问题,Capacity Scheduler总会过量初始化一些任务,从而让一部分任务处于等待资源的状态。
Capacity Scheduler中作业初始化由线程JobInitializationPoller完成。该线程由若干个(可通过参数mapred.capacity-scheduler.init-worker-threads指定,默认是5)工作线程JobInitializationThread组成,每个工作线程负责一个或者多个队列的作业初始化工作。作业初始化流程如下:
步骤1 用户将作业提交到JobTracker端后,JobTracker会向所有注册的监听器广播该作业信息;Capacity Scheduler中的监听器JobQueuesManager收到新作业添加的信息后,检查是否能够满足以下三个约束,如果不满足,则提示作业初始化失败,否则将该作业添加到对应队列的等待作业列表中:
❑该作业的任务数目不超过maximum-initialized-active-tasks-per-user。
❑队列中等待初始化和已经初始化的作业数目不超过(init-accept-jobs-factor)×(maximum-system-jos)×capacity/100。
❑该用户等待初始化和已经初始化的作业数目不超过[(maximum-system-jobs)×capacity/100.0×(minimum-user-limit-percent)100.0]×(init-accept-jobs-factor)。
步骤2 在每个队列中,按照以下策略对未初始化的作业进行排序:如果支持作业优先级(supports-priority为true),则按照FIFO策略(先按照作业优先级排序,再按照到达时间排序)排序,否则,按照作业到达时间排序。每个工作线程每隔一段时间(可通过参数mapred.capacity-scheduler.init-poll-interval设定,默认是3 000毫秒)遍历其对应的作业队列,并选出满足以下几个条件的作业:
❑队列已初始化作业数目(正运行的作业数目与已初始化但未运行作业数目之和)不超过[(maximum-system-jobs)×capaity/100.0]。
❑队列中已初始化任务数目不超过maximum-initialized-active-tasks。
❑该用户已经初始化作业数目不超过[(maximum-system-jobs)×capacity/100.0×(minimum-user-limit-percent)/100.0]。
❑该用户已经初始化的任务数目不超过maximum-initialized-active-tasks-per-user。
步骤3 调用JobTracker.initJob()函数对筛选出来的作业进行初始化。
3.任务调度
每个TaskTracker周期性向JobTracker发送心跳汇报任务进度和资源使用情况,并在出现空闲资源时请求分配新任务。当需要为某个TaskTracker分配任务时,JobTracker会调用调度器的assignTasks函数为其返回一个待运行的任务列表。对于Capacity Scheduler而言,该assignTasks函数由类CapacityTaskScheduler实现。其主要工作流程如图10-4所示,主要分为三个步骤:
步骤1 更新队列资源使用量。在选择任务之前,需要更新各个队列的资源使用信息,以便根据最新的信息进行调度。更新的信息包括队列资源容量、资源使用上限[1]、正在运行的任务和已经使用的资源量等。
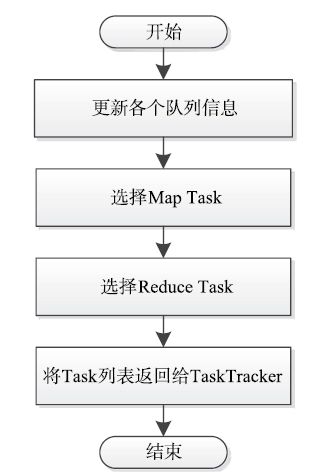
图 10-4 Capacity Scheduler中任务分配过程
步骤2 选择Map Task。正如第6章所述,Hadoop调度器通常采用三级调度策略,即依次选择一个队列、该队列中的一个作业和该作业中的一个任务,Capacity Scheduler也是如此。下面分别介绍Capacity Scheduler采用的调度策略。
❑选择队列:Capacity Scheduler总是优先将资源分配给资源使用率最低的队列,即numSlotsOccupied/capacity最小的队列,其中numSlotsOccupied表示队列当前已经使用的slot数目,capacity为队列的资源容量。
❑选择作业:在队列内部,待调度作业排序策略与待初始化作业排序策略一样,即如果支持作业优先级(supports-priority为true),则按照FIFO策略排序,否则,按照作业到达时间排序。当选择任务时,调度器会依次遍历排好序的作业,并检查当前TaskTracker剩余资源是否足以运行当前作业的一个任务(注意,一个任务可能同时需要多个slot),如果满足,则从该作业中选择一个任务添加到已分配任务列表中。任务分配过程如图10-5所示。
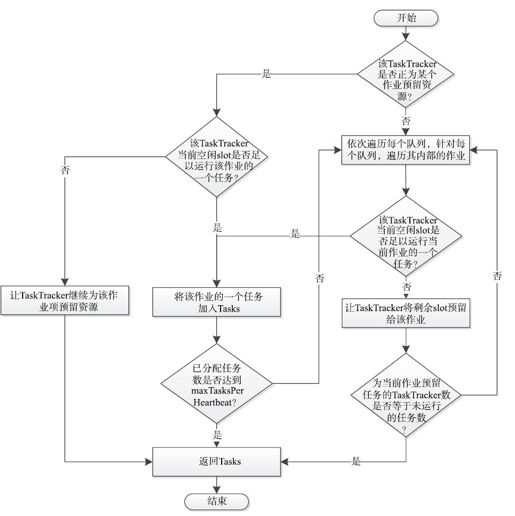
图 10-5 Capacity Scheduler任务分配流程图
Capacity Scheduler调度过程用到了以下几个机制。
机制1:大内存任务调度。
Capacity Scheduler提供了对大内存任务的调度机制。默认情况下,Hadoop假设所有任务是同质的,任何一个任务只能使用一个slot,考虑到一个slot代表的内存是一定的,因此这并没有考虑那些内存密集型的任务。为解决该问题,Capacity Scheduler可根据任务的内存需求量为其分配一个或者多个slot。如果当前TaskTracker空闲slot数目小于作业的单个任务的需求量,调度器会让TaskTracker为该作业预留[2]当前空闲的slot,直到累计预留的slot数目满足当前作业的单个任务需求,此时,才会真正地将该任务分配给TaskTracker执行。
默认情况下,大内存任务调度机制是关闭的,只有当管理员配置了mapred.cluster.map.memory.mb、mapred.cluster.reduce.memory.mb、mapred.cluster.max.map.memory.mb、mapred.cluster.max.reduce.memory.mb四个参数后,才会支持大内存任务调度,此时,调度器会按照以下公式计算每个Map Task需要的slot数(Reduce Task计算方法类似):
「${mapred. job.map.memory.mb}/${mapred.cluster.map.memory.mb}」
机制2:通过任务延迟调度以提高数据本地性。
第6章提到,当任务的输入数据与分配到的slot位于同一个节点或者机架时,称该任务具有数据本地性。数据本地性包含三个级别,分别是node-local(输入数据和空闲slot位于同一个节点)、rack-local(输入数据和空闲slot位于同一个机架)和off-switch(输入数据和空闲slot位于不同机架)。由于为空闲slot选择具有本地性的任务可避免通过网络远程读取数据进而提高数据读取效率,所以Hadoop会优先选择node-local的任务,然后是rack-local,最后是off-switch。
为了提高任务的数据本地性,Capacity Scheduler采用了作业延迟调度的策略:当选中一个作业后,如果在该作业中未找到满足数据本地性的任务,则调度器会让该作业跳过一定数目的调度机会,直到找到一个满足本地性(node-local或rack-local)的任务或者达到跳过次数上限(requiredSlots×localityWaitFactor),其中,localityWaitFactor可通过参数mapreduce.job.locality.wait.factor配置,默认情况下,计算方法如下:
localityWaitFactor=min{jobNodes/clusterNodes,1}
其中,jobNodes表示该作业输入数据所在的节点总数;clusterNodes表示整个集群中节点总数。
requiredSlots计算方法如下:
requiredSlots=min{(numMapTasks-finishedMapTask),numTaskTrackers}
其中,numMapTasks、finishedMapTasks分别表示该作业总的Map Task数目和已经运行完成的Map Task数目;numTaskTrackers表示整个集群中的TaskTracker数目(注意,由于一个节点上可能用于多个TaskTracker,因此numTaskTrackers与clusterNodes可能不相等)。
机制3:批量任务分配。
为了加快任务分配速度,Capacity Scheduler支持批量任务分配,管理员可通过参数mapred.capacity-scheduler.maximum-tasks-per-heartbeat(默认是Short.MAX_VALUE)指定一次性为一个TaskTracker分配的最多任务数。需要注意的是,该机制倾向于将任务分配给优先发送心跳的TaskTracker,也就是说,当系统slot数目大于任务需要的数目时,会使得任务集中运行在少数几个节点上,且同一个作业的任务也可能会集中分配到几个节点上,这不利于负载均衡。
步骤3:选择Reduce Task。
相比于Map Task, Reduce Task选择机制就简单多了。它仅采用了大内存任务调度策略,至于其他策略,如任务延迟调度(Reduce Task没有数据本地性)和批量任务分配等,不再采用。调度器只要找到一个合适的Reduce Task便可以返回。
[1]队列的资源容量和资源使用上限是在配置文件中配置的百分比。在一个运行的Hadoop集群中,节点的数目是不断变化的,因此,通过该百分比求出来的资源量也是变化的。
[2]预留:暂时占下slot,尽管没有实际使用,但可防止被其他任务占用。
