7.4.3 杀死任务
Hadoop中存在多种场景将一个任务杀死,它们涉及的过程基本相同,均是通过JobTracker向TaskTracker发送KillTaskAction命令完成的。本小节分析用户使用Shell命令杀死任务的整个过程,具体如图7-5所示。
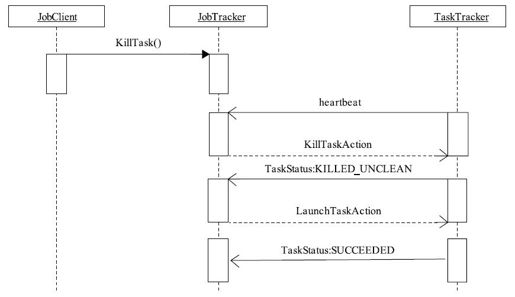
图 7-5 杀死任务序列图
用户输入“bin/hadoop job-kill-task<task-attempt-id>”后,JobClient内部调用RPC函数KillTask杀死该Task Attempt,整个过程如下:
1)JobTracker收到来自JobClient的杀死任务请求后,将该任务添加到待杀死任务列表tasksToKill中。
2)之后某个时刻,Task Attempt所在的TaskTracker向JobTracker发送心跳,JobTracker收到心跳后,将该任务封装到KillTaskAction命令中,并通过心跳应答发送给TaskTracker。
3)TaskTracker收到KillTaskAction命令后,将该任务从作业列表runningJobs中清除,并将运行状态从RUNNING转化为KILLED_UNCLEAN,同时通知directoryCleanupThread线程清理其工作目录,释放所占槽位,最后缩短心跳时间间隔,以便将该任务状态迅速通过带外心跳告诉JobTracker。
4)JobTracker收到状态为KILLED_UNCLEAN的Task Attempt后,将其类型改为task-cleanup task(这种任务的输入数据为空,但ID与被杀Task Attempt的ID相同,其目的是清理被杀Task Attempt已经写入HDFS的临时数据),并添加到待清理任务队列mapCleanupTasks/reduceCleanupTasks中,在接下来的某个TaskTracker的心跳中,JobTracker将其封装到LaunchTaskAction中发送给TaskTracker。
5)TaskTracker收到LaunchTaskAction后,启动JVM(或重用已启动的JVM)执行该任务。由于该任务属于task-cleanup task,因此它只需清理被杀死的Task Attempt已写入HDFS的临时数据(如果没有则直接跳过),之后其运行状态变为SUCCEEDED,并由TaskTracker通过下一次心跳告诉JobTracker。
6)JobTracker收到运行状态为SUCCEEDED的Task Attempt后,首先检查它是否位于任务列表tasksToKill中,显然该任务在该列表中,这表明它已经被杀死,于是将其状态转化为KILLED,同时修改相应的各个数据结构。
从上面整个过程可以看出,JobClient向JobTracker发出“kill task”请求后,JobTracker不会返回任何确认消息。这主要是由于杀死任务的过程比较复杂,要经历多个心跳时间,JobClient需等待很长时间才可能知道任务是否被成功杀死。
