6.6.3 0.21.0版本的算法
为了解决1.0.0版本中存在的问题,Hadoop 0.21.0提出了新的算法LATE(Longest Approximate Time to End)[1]。对于“适用情况考虑不全”问题,它采用了基于任务运行速度和任务最大剩余时间的策略,尽可能地提高发现“拖后腿”任务的可能性;对于“缺乏保证备份任务执行速度的机制”问题,它根据历史任务运行速度对节点进行性能评测,以识别出快节点和慢节点,并将新启动的备份任务分配给快节点;对于“参数不可配置”问题,它增加了多个配置选项,使一些常量数据尽可能地可配置,进而方便用户按照自己的应用特点和集群特点定制相应的参数值。
1.配置选项
Hadoop 0.21.0中增加了三个配置选项,用户在提交某个作业时可根据需要指定这三个参数值。
(1)mapreduce. job.speculative.slownodethreshold
这个参数用于定义该作业在任意一个TaskTracker上已运行完成任务的平均进度增长率(一个任务在单位时间内运行进度的增长量)与所有已运行完成任务的平均进度增长率的最大允许差距(标准方差的倍数)。如果超过该阈值,则认为对于该作业而言,该TaskTracker性能过低,不会在其上启动一个备份任务。该配置选项默认值是1,表示如果一个TaskTracker上已运行完成任务的平均进度增长率与所有已运行完成任务的平均进度增长率的差距超过所有已运行完成的任务进度增长率标准方差的1倍,则不会在该TaskTracker上为该作业启动任何备份任务。
(2)mapreduce. job.speculative.slowtaskthreshold
这个参数用于定义该作业的任意一个任务平均进度增长率与所有正在运行任务的平均进度增长率的最大允许差距(标准方差的倍数)。当超过该阈值时,则认为该任务运行过慢,需为之启动一个备份任务。其默认值是1,表示如果一个任务平均进度增长率与(同一个作业的)所有任务平均进度增长率的差距超过所有任务进度增长率标准方差的1倍,则需为该任务启动一个备份任务。
(3)mapreduce. job.speculative.speculativecap
这个参数用于限定该作业允许启动备份任务的任务数目占正在运行任务的百分比。其默认值为0.1,表示可为一个作业启动推测执行功能的任务数不能超过正在运行任务的10%。
2.启动备份任务
下面介绍对于一个作业J与TaskTracker X,如何判断是否能够在X上为J的某个任务(比如任务T)启动一个备份任务。首先引入以下几个变量:
❑progressRate(O)s:作业J中所有运行状态为s(可以为f或者r,分别表示已经运行完成的任务和正在运行的任务)的任务的进度增长率,O为任务集合。如果O为某个TaskTracker,则表示该TaskTracker上所有运行状态为s的任务平均进度增长率;如果O为*,则表示整个集群中所有运行状态为s的任务平均进度增长率。对于任意一个任务T,它的任务进度增长率计算方法为:
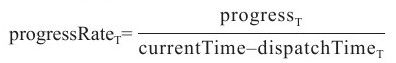
其中progressT是当前任务执行进度,currentTime为系统当前时间,dispatchTimeT任务T被调度的时间。
❑σs:作业J所有任务进度增长率的标准方差。
❑slowNodeThreshold/slowTaskThreshold/speculativeCap:分别对应以上三个配置选项的参数值。
何时选择并启动备份任务是由任务选择策略决定的,具体可参考6.7.2小节。在JobTracker端,JobInProgress类中的findSpeculativeTask方法用于选择一个需启动备份任务的Task。它通过以下四步发现一个“拖后腿”任务:
步骤1 判断X是否是一个慢TaskTracker,如果是,则不能启动任何备份任务。
为了判断一个TaskTracker是否适合启动备份任务,Hadoop通过该TaskTracker运行作业J的其他任务时的性能表现对其进行评估,如果满足以下条件,则认为该TaskTracker有能力启动一个备份任务:
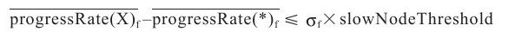
步骤2 检查作业J已经启动的任务数是否超过限制。
由于一个任务一旦启动了备份任务,则需要两倍的计算资源处理同样的数据,为了防止推测执行机制滥用,Hadoop要求同时启动的备份任务数目与所有正在运行任务的比例不能超过speculativeCap,即满足以下条件:
speculativeTaskCount/numRunningTask<speculativeCap
其中,speculativeTaskCount表示作业J已经启动的备份任务数目,numRunningTask表示作业J正在运行的任务总数。
步骤3 筛选出作业J中满足以下条件的所有任务,并保存到数组candidates中。
❑该任务未在TaskTracker X上运行失败过。
❑该任务没有其他正在运行的备份任务。
❑该任务已运行时间超过60秒。
❑该任务已经出现“拖后腿”的迹象,主要判断准则是:

步骤4 按照运行剩余时间由大到小对candidates中的任务进行排序,并选择剩余时间最大任务为其启动备份任务。
当数组candidates中有多个待选任务时,Hadoop倾向于选择剩余时间最长的任务,因为这样的任务使得其备份任务替代自己的可能性最大。为此,Hadoop采用了一个简单的线性模型估算一个任务的剩余时间timeLeft:
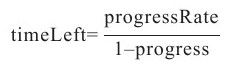
LATE算法并不是完美的。在实际使用时,由于LATE算法采用了静态方式计算任务的进度(对应前面的假设3),可能导致性能仍然比较低下,主要体现在以下两个方面。
❑任务进度和任务剩余时间估算不准确:这会导致部分正常任务被误认为是“拖后腿”任务,从而造成资源浪费。
❑未针对任务类型对节点分类:尽管LATE算法可通过任务执行速度识别出慢节点,但它未分别针对Map Task和Reduce Task做出更细粒度的识别。而实际应用中,一些节点对于Map Task而言是慢节点,但对Reduce Task而言则是快节点。
为了解决这些问题,论文《SAMR:A Self-adaptive MapReduce Scheduling Algorithm in Heterogneous Environment》[2]在LATE算法基础上进行了改进,提出了SAMR(Self Adaptive MapReduce)算法。该算法通过历史信息调整各个参数以提高估算任务进度和任务剩余时间的准确性,同时分别针对Map Task和Reduce Task将节点分成快节点和慢节点。
[1]Matei Zaharia, Andrew Konwinski, Anthony D. Joseph, Randy Katz, and Ion Stoica, Improving MapReduce Performance in Heterogeneous Environments,8th USENIX Symposium on Operating Systems Design Implementation, pp.29-42,San Diego, CA, December,2008.
[2]Quan Chen, Daqiang Zhang, Minyi Guo, Qianni Deng, Song Guo,"SAMR:A Self-adaptive MapReduce Scheduling Algorithm in Heterogeneous Environment,"Computer and Information Technology(CIT),2010 IEEE 10th International Conference.
