10.5.2 Fair Scheduler实现
1.Fair Scheduler基本设计思想
Fair Scheduler核心设计思想是基于资源池的最小资源量和公平共享量进行任务调度。其中,最小资源量是管理员配置的,而公平共享量是根据队列或作业权重计算得到的。资源分配具体过程如下:
步骤1 根据最小资源量将所有系统中所有slot分配给各个资源池。如果某个资源池实际需要的资源量小于它的最小资源量,则只需将实际资源需求量分配给它即可。
步骤2 根据资源池的权重将剩余的资源分配给各个资源池。
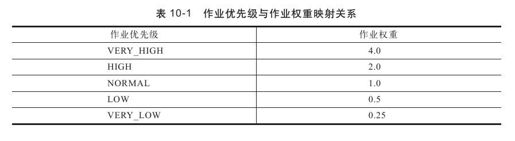
步骤3 在各个资源池中,按照作业权重将资源分配给各个作业,最终每个作业可以分到的资源量即为作业的公平共享量。其中,作业权重是由作业优先级转换而来的,它们的映射关系如表10-1所示。
用户也可以通过打开mapred.fairscheduler.sizebasedweigh参数以根据作业长度调整权重或者编写权重调整器动态调整作业权重。
【实例】如图10-7所示,假设一个Hadoop集群中共有100有slot(为了简单,不区分Map或者Reduce slot)和四个资源池(依次为P1、P2、P3和P4),它们的最小资源量依次为:25、19、26和28。如图10-7 a所示,在某一时刻,四个资源池实际需要的资源量(与未运行的任务数目相关)依次为20、26、37和30,则资源分配过程如下:
步骤1 根据最小资源量将资源分配各个资源池。对于资源池P1而言,由于它实际需要的资源量少于其最小资源量,因此只需将它实际需要的资源分配给它即可,如图10-7b和图10-7c所示。经过这一轮分配,四个资源池获得的slot数目依次为:20、19、26和28。
步骤2 经过第一轮分配后,尚剩余7个slot,此时需按照权重将剩余资源分配给尚需资源的资源池P2,P3和P4。不妨假设这三个资源池的权重依次为2.0、3.0和2.0,则它们额外分得的slot数目依次为2、3和2。这样,如图10-7 d所示,三个资源池最终获得的资源总量依次为:21、29和30。
步骤3 在各个资源池内部,按照作业的权重将资源分配给各个作业。以P4为例,假设P4中有三个作业,优先级依次为VERY_HIGH, NORMAL和NORMAL,则它们可能获得的slot数目依次为: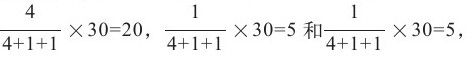 这三个值即为对应作业的公平共享量。
这三个值即为对应作业的公平共享量。
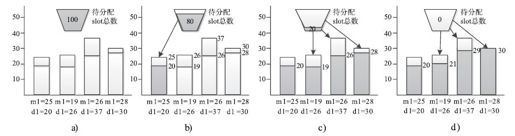
图 10-7 Fair Scheduler中的任务分配过程
注意 公平共享量只是理论上的资源分配量(理想值),在实际资源分配时,调度器应尽量将与公平共享量相等的资源分配给作业。
2.Fair Scheduler实现
Fair Scheduler内部组织结构如图10-8所示。涉及的模块有:配置文件加载模块、作业监听模块、状态更新模块和调度模块。下面分别介绍这几个模块。
❑配置文件加载模块:由类PoolManager完成,负责将配置文件fair-scheduler.xml中的信息加载到内存中。
❑作业监听模块:Fair Scheduler启动时会向JobTracker注册作业监听器JobListener,以便能够随时获取作业变化信息。
❑状态更新模块:由线程UpdateThread完成,该线程每隔mapred.fairscheduler.update.interval(默认是500毫秒)时间更新一次队列和作业的信息,以便将最新的信息提供给调度模块进行任务调度。
❑调度模块:当某个TaskTracker通过心跳请求任务时,该模块根据最新的队列和作业的信息为该TaskTracker选择一个或多个任务。
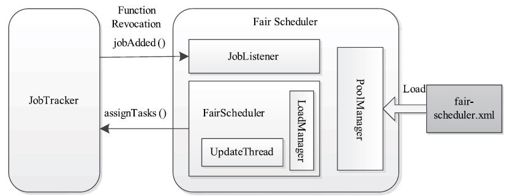
图 10-8 Fair Scheduler内部组织结构
在不同的Hadoop版本中,Fair Scheduler调度算法实现方式不同。这里介绍两个版本的实现:0.20.X版本和0.21.X/0.22.X/1.X版本。
(1)0.20.X版本
前面提到了作业公平共享量的计算方法,而调度器的任务就是将与公平共享量相等的资源分配给作业。在实际的Hadoop集群中,由于资源使用情况是动态变化的,且任务运行的时间长短不一,因此时刻保证每个作业实际分到的资源量与公平共享量一致是不可能的。为此,0.20.X版本采用了基于缺额的调度策略。该策略采用了贪心算法以保证尽可能公平地将资源分配给各个作业。
缺额(jobDeficit)是作业的公平共享量与实际分配到的资源量之间的差值。它反映了资源分配过程中产生的“理想与现实的差距”。调度器在实际资源分配时,应保证所有作业的缺额尽可能小。缺额的基本计算公式为:
jobDeficit=jobDeficit+(jobFairShare-runningTasks)×timeDelta
其中,jobFairShare为作业的公平共享量,runningTasks为作业正在运行的任务数目(对应实际分配到的资源量),timeDelta为缺额更新时间间隔。
从上面公式可以看出,作业缺额是随着时间积累的。在进行资源分配时,调度器总是优先将空闲资源分配给当前缺额最大的作业。如果在一段时间内一个作业一直没有获得资源,则它的缺额会越来越大,最终缺额变得最大,从而可以获得资源。这种基于缺额的调度机制并不能保证作业时时刻刻均能获得与其公平共享量对应的资源,但如果所有作业的运行时间足够长,则该机制能够保证每个作业实际平均分配到的资源量逼近它的公平共享量。
(2)0. 21.X/0.22.X/1.X版本
在0.21.X/0.22.X/1.X版本中,同Capacity Scheduler一样,Fair Scheduler也采用了三级调度策略,即依次选择一个资源池、该资源池中的一个作业和该作业中的一个任务,但具体采用的策略稍有不同。
选择队列
Fair Scheduler选择队列时,在不同的条件下采用不同的策略,具体如下:
❑当存在资源使用量小于最小资源量的资源池时,优先选择资源使用率最低的资源池,即runningTasks/minShare最小的资源池,其中runningTasks是资源池当前正在运行的Task数目(也就是正在使用的slot数目),minShare为资源池的最小资源量。
❑否则,选择任务权重比最小的资源池,其中资源池的任务权重比(tasksToWeightRatio)定义如下:
tasksToWeightRatio=runningTasks/poolWeight
其中,runningTasks为资源池中正在运行的任务数目;poolWeight是管理员配置的资源池权重。
选择作业
选定一个资源池后,Fair Scheduler总是优先将资源分配给资源池中任务权重比最小的作业,其中作业的任务权重比的计算方法与资源池的一致,即为该作业正在运行的任务数目与作业权重的比值。但需要注意的是,作业权重比是由作业优先级转换而来的。此外,Fair Scheduler为管理员提供了另外两种改变作业的权重的方法:
❑将参数mapred.fairscheduler.sizebasedweight置为true,则计算作业权重时会考虑作业长度,具体计算方法如下:
jobWeight=jobWeightByPriority×log2(runnableTasks)
其中,jobWeightByPriority是通过优先级转化来的权重;runnableTasks是作业正在运行和尚未运行的任务之和。
❑通过实现WeightAdjuster接口,编写一个权重调整器,并通过参数mapred.fairscheduler.weightadjuster使之生效,此时,作业权重即为WeightAdjuster中方法adjustWeight的返回值。
选择任务
任务选择策略已在第6章介绍过了,Fair Scheduler在该策略基础上又添加了延时调度机制[1],具体见下一小节。
3.Fair Scheduler优化机制
机制1:延时调度。
第6章中已讲了Map Task的数据本地性问题。我们知道,提高Map Task的数据本地性可提高作业运行效率。为了提高数据本地性,Fair Scheduler采用了延时调度机制:当出现一个空闲slot时,如果选中的作业没有node-local或者rack-local的任务,则暂时把资源让给其他作业,直到找到一个满足数据本地性的任务或者达到一个时间阈值,此时不得不为之选择一个非本地性的任务。
为了实现延时调度,Fair Scheduler为每个作业j维护三个变量:level、wait和skipped,分别表示最近一次调度时作业的本地性级别(0、1、2分别对应node-local、rack-local和off-switch)、已等待时间和是否延时调度,并依次初始化为:j.level=0、j.wait=0和j.skipped=false。此外,当不存在node-local任务时,为了尽可能选择一个本地性较好的任务,Fair Scheduler采用了双层延迟调度算法:为了找到一个node-local任务最长可等待W1或者进一步等待W2找一个rack-local任务。
总之,当JobTracker从TaskTracker上收到心跳后,Fair Scheduler按照以下算法选择Map Task:
function List<Task>assignTasks(TaskTracker tt)
taskList←null
for each job j in allJobs do
if j.skipped=true do
j.updateLocalityWaitTimes();//更新等待时间
j.skipped←false
done
end for
while n.availableSlots()>0 then//如果可用slot数目大于0
sort jobs using hierarchical scheduling policy
for j in jobs do//遍历排序后的所有作业
//查找该作业中是否包含符合node-local的Map Task
if(t=j.obtainNewNodeLocalMapTask())!=null then
j.wait←0,j.level←0
taskList.add(t);
break;
//查找该作业中是否包含符合rack-local的Map Task
else if(t=j.obtainNewNodeOrRackLocalMapTask())!=null and
(j.level>=1 or j.wait>=W1)then
j.wait←0,j.level←1
taskList.add(t)
break;
else if j.level=2 or(j.level=1 and j.wait>=W2)or
(j.level=0 and j.wait>=W1+W2)then
j.wait←0,j.level←2
//依次查找该作业中符合node-local, rack-local, off-switch的Map Task
t=j.obtainNewMapTask()
taskList.add(t);
break;
else
j.skipped←true
end if
end for
end while
return taskList;
end function
机制2:负载均衡。
Fair Scheduler为用户提供了一个可扩展的负载均衡器:CapBasedLoadManager。它会将系统中所有任务按照数量平均分配到各个节点上[2]。当然,用户也可通过继承抽象类LoadManager实现自己的负载均衡器。
机制3:资源抢占。
当一个资源池有剩余资源时,Fair Scheduler会将这些资源暂时共享给其他资源池;而一旦该资源池有新作业提交,调度器则为它回收资源。如果在一段时间后该资源池仍得不到本属于自己的资源,则调度器会通过杀死任务的方式抢占资源。Fair Scheduler同时采用了两种资源抢占方式:最小资源量抢占和公平共享量抢占。如果一个资源池的最小资源量在一定时间内得不到满足,则会从其他超额使用资源的资源池中抢占资源,这就是最小资源量抢占;而如果一定时间内一个资源池的公平共享量的一半得不到满足,则该资源池也会从其他资源池中抢占,这称为公平共享量抢占。
进行资源抢占时,调度器会选出超额使用资源的资源池,并从中找出启动时间最早的任务,再将其杀掉,进而释放资源。
[1]M. Zaharia, D.Borthakur, J.Sen Sarma, K.Elmeleegy, S.Shenker, and I.Stoica,“Delay scheduling:A simple technique for achieving locality and fairness in cluster scheduling”in Proc.of EuroSys.ACM,2010,pp.265-278.
[2]Hadoop 1. 0.X中存在一个Bug,这使得在批量调度模式下不能实现负载均衡。该Bug在1.1.0版本中已经修复,具体参考:https://issues.apache.org/jira/browse/MAPREDUCE-2905。
