5.2.2 作业文件上传
JobClient将作业提交到JobTracker端之前,需要进行一些初始化工作,包括:获取作业ID,创建HDFS目录,上传作业文件以及生成Split文件等。这些工作由函数JobClient.submitJobInternal(job)实现,具体流程如图5-3所示。在本小节中,我们将重点分析文件上传过程,而生成InputSplit文件的相关细节将放在下一小节中讨论。
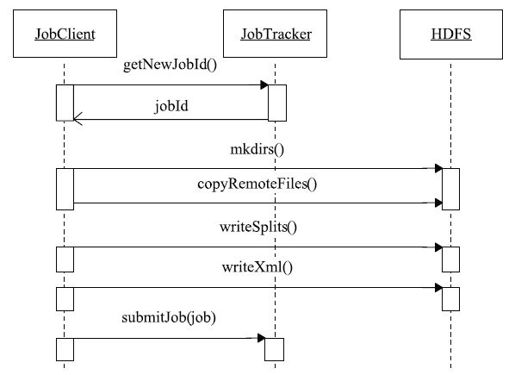
图 5-3 作业提交过程时序图
MapReduce作业文件的上传与下载是由DistributedCache工具完成的。它是Hadoop为方便用户进行应用程序开发而设计的数据分发工具。其整个工作流程对用户而言是透明的,也就是说,用户只需在提交作业时指定文件位置,至于这些文件的分发(需广播到各个TaskTracker上以运行Task),完全由DistributedCache工具完成,不需要用户参与。本小节主要涉及文件上传过程,而文件下载的相关细节将在5.4节中介绍。
通常而言,对于一个典型的Java MapReduce作业,可能包含以下资源。
❑程序jar包:用户用Java编写的MapReduce应用程序jar包。
❑作业配置文件:描述MapReduce应用程序的配置信息(根据JobConf对象生成的xml文件)。
❑依赖的第三方jar包:应用程序依赖的第三方jar包,提交作业时用参数“-libjars”指定。
❑依赖的归档文件:应用程序中用到多个文件,可直接打包成归档文件(通常为一些压缩文件),提交作业时用参数“-archives”指定。
❑依赖的普通文件:应用程序中可能用到普通文件,比如文本格式的字典文件,提交作业时用参数“-files”指定。
注意 应用程序依赖的文件可以存放在本地磁盘上,也可以存放在HDFS上,默认情况下是存放在本地磁盘上的,如上一小节中作业提交命令参数“-libjars=third-party.jar”指定的third-party.jar文件便存在于本地目录。如果程序依赖的文件已经事先上传到HDFS上,比如目录/data/中,则可以使用参数“-libjars=hdfs:///data/third-party.jar”指定。
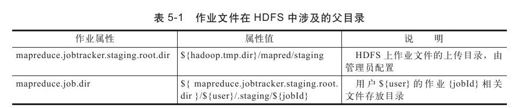
上述所有文件在JobClient端被提交到HDFS上,涉及的父目录如表5-1所示。
5.2.1节中MapReduce作业在HDFS中的目录组织结构如图5-4所示。
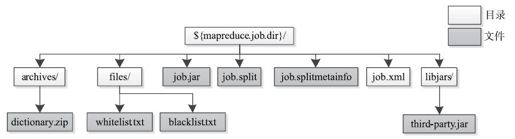
图 5-4 一个应用程序在HDFS上的目录组织结构
在这个例子中,由于参数-libjars,-archives和-files指定的文件均属于本地文件,因而JobClient会将这些文件上传到HDFS上;如果有些文件已经存在于HDFS上,则不再需要上传。
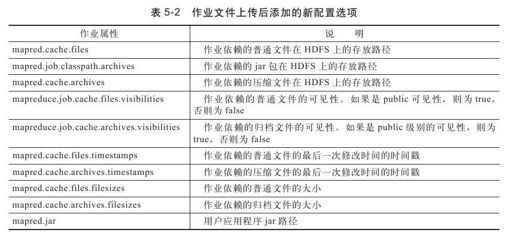
文件上传完毕后,会将这些目录信息保存到作业配置对象JobConf中,其对应的作业属性如表5-2所示。
DistributedCache将文件分为两种可见级别,分别是private级别和public级别。其中,private级别文件只会被当前用户使用,不能与其他用户共享;而public级别文件则不同,它们在每个节点上保存一份,可被本节点上的所有作业和用户共享,这样可以大大降低文件复制代价,提高了作业运行效率。一个文件/目录要成为public级别文件/目录,需同时满足以下两个条件:
❑该文件/目录对所有用户/用户组均有可读权限。
❑该文件/目录的父目录、父目录的父目录……对所有用户/用户组有可执行权限。
作业文件上传到HDFS后,可能会有大量节点同时从HDFS上下载这些文件,进而产生文件访问热点现象,造成性能瓶颈。为此,JobClient上传这些文件时会调高它们的副本数(由参数mapred.submit.replication指定,默认是10)以通过分摊负载方式避免产生访问热点。
