第8章 Task运行过程分析
大家都知道,当我们需要编写一个简单的MapReduce作业时,只需实现map()和reduce()两个函数即可,一旦将作业提交到集群上后,Hadoop内部会将这两个函数封装到Map Task和Reduce Task中,同时将它们调度到多个节点上并行执行,而任务执行过程中可能涉及的数据跨节点传输,记录按key分组等操作均由Task内部实现好了,用户无须关心。
为了帮助读者深入了解Map Task和Reduce Task内部实现原理,在本章中,我们将Map Task分解成Read、Map、Collect、Spill和Combine五个阶段,将Reduce Task分解成Shuffle、Merge、Sort、Reduce和Write五个阶段,并依次详细剖析每个阶段的内部实现细节。
8.1 Task运行过程概述
在MapReduce计算框架中,一个应用程序被划分成Map和Reduce两个计算阶段,它们分别由一个或者多个Map Task和Reduce Task组成。其中,每个Map Task处理输入数据集合中的一片数据(InputSplit),并将产生的若干个数据片段写到本地磁盘上,而Reduce Task则从每个Map Task上远程拷贝相应的数据片段,经分组聚集和归约后,将结果写到HDFS上作为最终结果,具体如图8-1所示。总体上看,Map Task与Reduce Task之间的数据传输采用了pull模型。为了能够容错,Map Task将中间计算结果存放到本地磁盘上,而Reduce Task则通过HTTP请求从各个Map Task端拖取(pull)相应的输入数据。为了更好地支持大量Reduce Task并发从Map Task端拷贝数据,Hadoop采用了Jetty Server作为HTTP Server处理并发数据读请求。
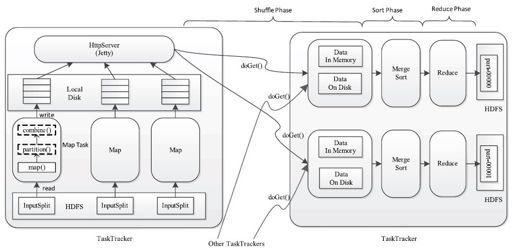
图 8-1 Map/Reduce Task运行过程
对于Map Task而言,它的执行过程可概述为:首先,通过用户提供的InputFormat将对应的InputSplit解析成一系列key/value,并依次交给用户编写的map()函数处理;接着按照指定的Partitioner对数据分片,以确定每个key/value将交给哪个Reduce Task处理;之后将数据交给用户定义的Combiner进行一次本地规约(用户没有定义则直接跳过);最后将处理结果保存到本地磁盘上。
对于Reduce Task而言,由于它的输入数据来自各个Map Task,因此首先需通过HTTP请求从各个已经运行完成的Map Task上拷贝对应的数据分片,待所有数据拷贝完成后,再以key为关键字对所有数据进行排序,通过排序,key相同的记录聚集到一起形成若干分组,然后将每组数据交给用户编写的reduce()函数处理,并将数据结果直接写到HDFS上作为最终输出结果。
在接下来的几节中,我们将逐步深入分析Map Task和Reduce Task内部实现,并剖析其设计原理和实现细节。
