6.2.3 各种线程功能
函数offerServer会启动JobTracker内部几个比较重要的后台服务线程,分别是expireTrackersThread、retireJobsThread、expireLaunchingTaskThread和completedJobsStoreThread。下面分别介绍这几个服务线程。
(1)expireTrackersThread线程
该线程主要用于发现和清理死掉的TaskTracker。每个TaskTracker会周期性地通过心跳向JobTracker汇报信息,而JobTracker会记录每个TaskTracker最近的汇报心跳时间。如果某个TaskTracker在10分钟内未汇报心跳,则JobTracker认为它已死掉,并将它的相关信息从数据结构trackerToJobsToCleanup、trackerToTasksToCleanup、trackerToTaskMap、trackerToMarkedTasksMap中清除,同时将正在运行的任务状态标注为KILLED_UNCLEAN。
(2)retireJobsThread线程
该线程主要用于清理长时间驻留在内存中的已经运行完成的作业信息。JobTracker会将已经运行完成的作业信息存放到内存中,以便外部查询,但随着完成的作业越来越多,势必会占用JobTracker的大量内存,为此,JobTracker通过该线程清理驻留在内存中较长时间的已经运行完成的作业信息。
当一个作业满足如下条件1、2或者条件1、3时,将被从数据结构jobs转移到过期作业队列中。
条件1 作业已经运行完成,即运行状态为SUCCEEDED、FAILED或KILLED。
条件2 作业完成时间距现在已经超过24小时(可通过参数mapred.jobtracker.retirejob.interval配置)。
条件3 作业拥有者已经完成作业总数超过100(可通过参数mapred.jobtracker.completeuserjobs.maximum配置)个。
过期作业被统一保存到过期队列中。当过期作业超过1 000个(可通过参数mapred.job.tracker.retiredjobs.cache.size配置)时,将会从内存中彻底删除。
(3)expireLaunchingTaskThread线程
该线程用于发现已经被分配给某个TaskTracker但一直未汇报信息的任务。当JobTracker将某个任务分配给TaskTracker后,如果该任务在10分钟内未汇报进度,则JobTracker认为该任务分配失败[1],并将其状态标注为FAILED。
(4)completedJobsStoreThread线程
该线程将已经运行完成的作业运行信息保存到HDFS上,并提供了一套存取这些信息的API。该线程能够解决以下两个问题。
❑用户无法获取很久之前的作业运行信息:前面提到线程retireJobsThread会清除长时间驻留在内存中的完成作业,这会导致用户无法查询很久之前某个作业的运行信息。
❑JobTracker重启后作业运行信息丢失:当JobTracker因故障重启后,所有原本保存到内存中的作业信息将会全部丢失。
该线程通过保存作业运行日志的方式,使得用户可以查询任意时间提交的作业和还原作业的运行信息。
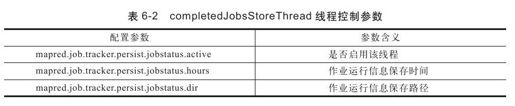
默认情况下,该线程不会启用,用户可通过表6-2所示的几个参数配置并启用该线程。
[1]JobTracker总是假设TaskTracker是不可靠的,它总是认为TaskTracker可能会只接收新任务但不启动它。
