5.4.2 工作原理分析
Hadoop DistributedCache工作原理如图5-9所示。它主要的功能是将作业文件分发到各个TaskTracker上,具体流程可分为4个步骤:
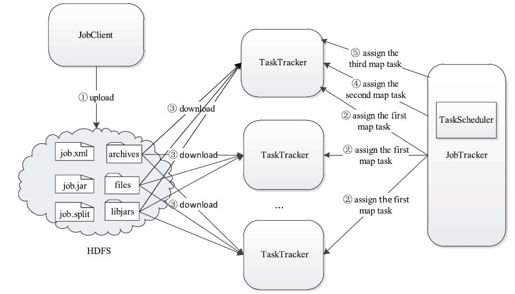
图 5-9 Hadoop DistributedCache工作原理图
步骤1 用户提交作业后,DistributedCache将作业文件上传到HDFS上的固定目录中,具体见5.2.2节。
步骤2 JobTracker端的任务调度器将作业对应的任务发派到各个TaskTracker上。
步骤3 任何一个TaskTracker收到该作业的第一个任务后,由DistributedCache自动将作业文件缓存到本地目录下(对于后缀为.zip、.jar、.tar、.tgz或者.tar.gz的文件,会自动对其进行解压缩),然后开始启动该任务。
步骤4 对于TaskTracker接下来收到的任务,DistributedCache不会再重复为其下载文件,而是直接运行。
下面分析TaskTracker中作业目录组织结构,具体如图5-10所示。在TaskTracker本地目录中,不同可见级别的文件被存放于不同的目录。对于public级别的文件,会被保存到公共目录${mapred.local.dir}/taskTracker/distcache中,该目录中的文件可被该TaskTracker上所有用户共享,也就是说,这些文件只会被下载一遍,后面的任何用户的作业可直接使用;对于private级别的文件,则被保存到用户私有目录${mapred.local.dir}/taskTracker/${user}下,在该目录下,将DistributedCache文件和作业运行需要文件分别放到子目录distcache和jobcache中,其中jobcache目录相当于作业的工作目录,它里面的文件大多是指向其他文件和目录的软连接,这些目录中的文件只能被该用户的作业共享。
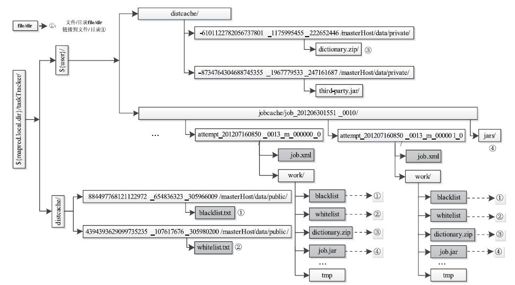
图 5-10 TaskTracker端作业目录组织结构
DistributedCache中的文件或者目录并不是用完后立即被清理的,而是由专门的一个线程根据文件大小上限(由参数local.cache.size设定,默认是10 GB)和文件/目录数目上限(由参数mapreduce.tasktracker.local.cache.numberdirectories设定,默认是10 000)周期性(由参数mapreduce.tasktracker.distributedcache.checkperiod设定,默认是60)地进行清理。
Hadoop DistributedCache的实现在包org.apache.hadoop.filecache中,主要包括DistributedCache、TaskDistributedCacheManager和TrackerDistributedCacheManager三个类。它们的功能如下。
❑DistributedCache类:可供用户直接使用的外部类。它提供了一系列addXXX、setXXX和getXXX方法以配置作业需借用DitributedCache分发的只读文件。
❑TaskDistributedCacheManager类:Hadoop内部使用的类,用于管理一个作业相关的缓存文件。
❑TrackerDistributedCacheManager类:Hadoop内部使用的类,用于管理一个TaskTracker上所有的缓存文件。它只用于缓存public可见级别的文件,而对于private可见级别的文件,则由org.apache.hadoop.mapred包中的JobLocalizer类进行缓存。
