5.3 作业初始化过程详解
调度器调用JobTracker.initJob()函数对新作业进行初始化。作业初始化的主要工作是构造Map Task和Reduce Task并对它们进行初始化。
如图5-8所示,Hadoop将每个作业分解成4种类型的任务,分别是Setup Task、Map Task、Reduce Task和Cleanup Task。它们的运行时信息由TaskInProgress类维护,因此,创建这些任务实际上是创建TaskInProgress对象。
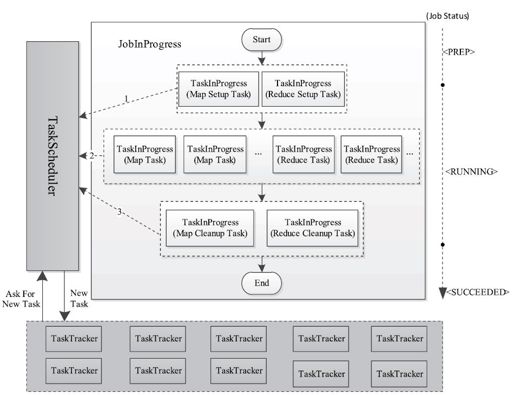
图 5-8 作业初始化过程概述
上述4种任务的作用及创建过程如下。
❑Setup Task:作业初始化标识性任务。它进行一些非常简单的作业初始化工作,比如将运行状态设置为“setup”,调用OutputCommitter.setupJob()函数等。该任务运行完后,作业由PREP状态变为RUNNING状态,并开始运行Map Task。该类型任务又被分为Map Setup Task和Reduce Setup Task两种,且每个作业各有一个。它们运行时分别占用一个Map slot和Reduce slot。由于这两种任务功能相同,因此有且只有一个可以获得运行的机会(即只要有一个开始运行,另一个马上被杀掉,而具体哪一个能够运行,取决于当时存在的空闲slot种类及调度策略)。
创建该类任务的相关代码如下:
……
//创建两个TIP, Map和Reduce各一个
setup=new TaskInProgress[2];
//setup map tip.这个Map不会使用任何split,只赋予它一个空split
setup[0]=new TaskInProgress(jobId, jobFile, emptySplit,
jobtracker, conf, this, numMapTasks+1,1);
setup[0].setJobSetupTask();
//setup reduce tip.
setup[1]=new TaskInProgress(jobId, jobFile, numMapTasks,
numReduceTasks+1,jobtracker, conf, this,1);
setup[1].setJobSetupTask();
❑Map Task:Map阶段处理数据的任务。其数目及对应的处理数据分片由应用程序中的InputFormat组件确定。
创建该类任务的相关代码如下:
//读取job.splitmetainfo文件,还原TaskSplitMetaInfo对象,每个对象描述了一个InputSplit信息
TaskSplitMetaInfo[]splits=createSplits(jobId);
numMapTasks=splits.length;
……
maps=new TaskInProgress[numMapTasks];
for(int i=0;i<numMapTasks;++i){
inputLength+=splits[i].getInputDataLength();
maps[i]=new TaskInProgress(jobId, jobFile,
splits[i],
jobtracker, conf, this, i,numSlotsPerMap);
}
❑Reduce Task:Reduce阶段处理数据的任务。其数目由用户通过参数mapred.reduce.tasks(默认数目为1)指定。考虑到Reduce Task能否运行依赖于Map Task的输出结果,因此,Hadoop刚开始只会调度Map Task,直到Map Task完成数目达到一定比例(由参数mapred.reduce.slowstart.completed.maps指定,默认是0.05,即5%)后,才开始调度Reduce Task。
创建该类任务的相关代码如下:
this.reduces=new TaskInProgress[numReduceTasks];
for(int i=0;i<numReduceTasks;i++){
reduces[i]=new TaskInProgress(jobId, jobFile,
numMapTasks, i,
jobtracker, conf, this, numSlotsPerReduce);
nonRunningReduces.add(reduces[i]);
}
❑Cleanup Task:作业结束标志性任务,主要完成一些作业清理工作,比如删除作业运行过程中用到的一些临时目录(比如_temporary目录)。一旦该任务运行成功后,作业由RUNNING状态变为SUCCEEDED状态。
随着Hadoop的普及和衍化,有人发现引入Setup/Cleanup Task会拖慢作业执行进度且降低作业的可靠性[1],这主要是因为Hadoop除了需保证每个Map/Reduce Task运行成功外,还要保证Setup/Cleanup Task成功。对于Map/Reduce Task而言,可通过推测执行机制(具体参考6.6节)避免出现“拖后腿”任务。然而,由于Setup/Cleanup Task不会处理任何数据,两种任务进度只有0%和100%两个值,从而使得推测式任务机制对之不适用。为解决该问题,从0.21.0版本开始,Hadoop将是否启用Setup/Cleanup Task变成了可配置的选项[2],用户可通过参数mapred.committer.job.setup.cleanup.needed配置是否为作业创建Setup/Cleanup Task。
这4种任务的调度顺序是Setup Task、Map Task、Reduce Task和Cleanup Task,其中,Map Task完成一定比例后便开始调用Reduce Task。这期间涉及一些任务调度策略,我们将在第6章中详细讨论。
[1]https://issues. apache.org/jira/browse/MAPREDUCE-1099
[2]https://issues. apache.org/jira/browse/MAPREDUCE-463
