6.5.4 Record容错
MapReduce采用了迭代式处理模型。它将输入数据解析成一个个key/value进行迭代处理,然而,在数据处理过程中,可能由于存在一些坏记录,导致任务总是运行失败。为此,MapReduce引入了Record级别的容错机制。它能够“有记忆”地运行任务,即它会记录前几次任务尝试中导致任务失败的Record,并在下次运行时自动跳过这些坏记录[1]。
在实际应用场景中,有多种原因使得坏记录导致任务运行失败,常见原因有两个:
❑某些记录的key或者value超大,导致内存溢出(Out Of Memory, OOM)。
❑用户应用程序使用了第三方的jar包或者静态库/动态库(不可获取源代码),由于这些程序中存在Bug,使得某些记录总是处理失败,进而导致任务运行崩溃或者任务悬挂[2](一旦任务长时间无响应,TaskTracker会将其杀掉)。
对于第一种情况,MapReduce允许用户在InputFormat组件中设置key或者value的最大长度(如果使用TextInputFormat,可配置参数mapred.linerecordreader.maxlength),一旦超过该长度,则直接截断字符串以防止OOM。
对于第二种情况,MapReduce采用了一种智能的有记忆尝试运行机制。前面提到,每个任务会尝试运行多次,直到任务运行成功或者达到运行次数上限。对于一个任务,MapReduce会先尝试运行几次,如果总是失败,则会自动进入skip mode模式。在该模式下,每个Task Attempt不断将接下来要处理的数据区间发送给TaskTracker,再由TaskTracker通过心跳发送给JobTracker,因此,JobTracker时刻保存了尚未处理完成的数据所在区间,这样,如果因某条坏记录导致任务运行失败,JobTracker很容易推断出坏记录所在区间。当重新运行失败任务时,JobTracker将过去识别出的所有坏记录区间“告诉”新的Task Attempt,从而可在运行过程中自动跳过这些坏记录区间。通过这种机制,Hadoop以丢失少量坏记录为代价保证整个任务运行成功,这对于很多数据密集型作业(比如日志分析)是可以接受的。
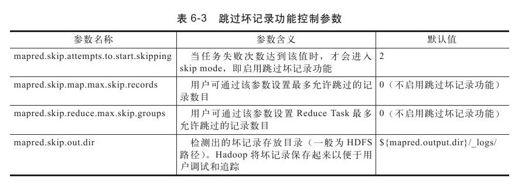
用户可通过SkipBadRecords类控制该机制。它提供了表6-3所示的几个可配置参数。
设mapred.skip.attempts.to.start.skipping值为k(k>=0),mapred.skip.map.max.skip.records值为N(N>0),mapred.map.max.attempts值为M(M>k),failedRanges为坏记录区间列表,保存了已运行失败的Task Attempt检测出的坏记录区间。以Map Task为例,跳过坏记录工作流程可分为以下几个步骤:
步骤1 每个任务先尝试运行k次,如果任务运行成功则停止,否则进入skip mode,令i←k+1并进入步骤2。
步骤2 第i个Task Attempt不断地(通常是每处理一条汇报一次)将接下来要处理的数据区间Range[offset, length][3]汇报给TaskTracker, TaskTracker将之保存到变量nextRecordRange中。需要注意的是,Task Attempt会判断接下来要处理的数据是否在坏记录区间列表failedRanges中,如果是,则跳过对应区间。
步骤3 TaskTracker通过心跳将每个任务最近的nextRecordRange值汇报给JobTracker。
步骤4 如果第i个Task Attempt运行失败,则JobTracker将查看最近一次数据处理区间长度是否超过N,如果是,则将其不断二等分,直到区间长度小于N,并依次选择这几个区间作为新Task Attempt的输入数据,以期望这些Task Attempt探测出失败记录所在的区间。设其中第j个Task Attempt运行失败,则它所处理的数据区间即为坏记录所在区间,JobTracker将该区间添加到坏记录区间列表failedRanges中。
步骤5 令i←(i+j),并将最新的failedRanges值作为下一个Task Attempt的已知信息,重复步骤2~4,直到i>=M或者任务运行成功。
下面介绍Task Attempt如何锁定将要处理的数据区间。对于每个处于skip mode的Task Attempt而言,均包含两个指针用于锁定接下来要处理的数据区间:currentRecStartIndex和nextRecIndex。它们分别表示下一条将被RecordReader解析的数据记录索引(前面的数据已确认被成功处理完)和已被RecordReader解析但未交给Mapper/Reducer处理的记录索引。区间Range[currentRecStartIndex, nextRecIndex-currentRecStartIndex+1]为将要处理的数据区间。其中,nextRecIndex值的增加由Hadoop框架控制,而currentRecStartIndex通常由用户控制,它的值随着Hadoop内部已定义好的两个计数器值的改变而改变,这两个计数器分别是位于SkippingTaskCounters组的MapProcessedRecords和ReducerProcessedRecords中。这两个计数器在不同类型的应用程序中控制方法不同。以Map Task为例,对于Java应用程序而言,如果采用默认的MapRunner,则每处理完一条记录后,会自动对MapProcessedRecords计数器加1;然而对于Pipes/Streaming应用程序而言,由于数据处理逻辑通常由另外一种语言(非Java语言)实现,用户可能在Mapper中对记录进行缓存,因而需要用户在应用程序中根据实际逻辑增加该计数器值。
为了帮助读者更深入了解跳过坏记录的工作原理,我们接下来举一个简单的例子。假设用户需要处理一个文本文件skip-bad-records-test.txt,它的每一行是一个字符串,如果某一行内容是“Bad”,则认为它是坏记录,否则是正常记录,直接输出即可。文件内容举例如下:
Good
Good
Good
……
Bad
……
为了方便,我们使用Awk语言编写mapper.awk脚本作为Mapper:
!/bin/awk-f
{
if($1~/^bad$/){#这一行是坏记录
exit 1;#模拟异常退出
}else{
print"reporter:counter:SkippingTaskCounters, MapProcessedRecords,1"\
>"/dev/stderr";#通过标准错误输出修改Counter
print$1;#输出结果
}
}
我们使用Hadoop Streaming运行以上程序,Shell运行脚本如下:
HADOOP_HOME=/opt/dongxicheng/hadoop-1.0.0
$HADOOP_HOME/bin/hadoop jar\
$HADOOP_HOME/contrib/streaming/hadoop-streaming-1.0.0.jar\
-D mapred.job.name="Skip-Bad-Records-Test"\
-D mapred.map.tasks=1\
-D mapred.reduce.tasks=0\
-D mapred.skip.map.max.skip.records=1\
-D mapred.skip.attempts.to.start.skipping=2\
-D mapred.map.max.attempts=6\
-input"/test/input/skip-bad-records-test.txt"\
-output"/test/output"\
-mapper"mapper.awk"\
-file"mapper.awk"
假设输入文件中只在361行(从第0行开始计算)中有一条坏记录。根据跳过坏记录算法,仅有的一个Map Task需要尝试运行5次才会最终运行成功,如图6-8所示,过程如下:
1)前两个Task Attempt尝试处理该文件,但每次到361行均异常退出,导致任务运行失败。
2)从第三个Task Attempt开始进入skip mode。该Task Attempt在处理数据过程中,会不断将接下来的数据处理区间汇报给TaskTracker,再由TaskTracker汇报给JobTracker,当处理到第361行时出现错误,此时,JobTracker最后收到的数据处理区间是Range[361,2][4]。
3)由于数据处理区间长度超过1(一次最多可跳过坏记录条数为1),JobTracker采用二分法将该区间分裂成两段,分别是Range[361,1]和Range[362,1],并将第四个Task Attempt作为测试任务,指定其数据处理区间为Range[361,1],即跳过区间Range[0,361]和Range[362,∞],只处理第361行记录。
4)第四个Task Attempt仍然运行失败,此时JobTracker可推断出Range[361,1]为坏记录所在区间,同时将Range[362,1]标注为正常数据区间,并将该信息传递给第五个Task Attempt。
5)第五个Task Attempt在运行过程中跳过坏记录区间Range[361,1],最终运行成功。
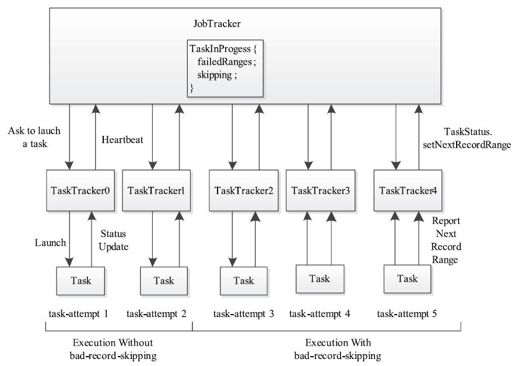
图 6-8 一个跳过坏记录实例
[1]https://issues. apache.org/jira/browse/HADOOP-153
[2]任务悬挂是一种常见的现象,通常对外表现为任务阻塞,不再汇报进度和状态。
[3]Range[offset, length]:表示一个数据处理区间,其中offset为区间中第一条记录在整个数据块中的偏移量(以记录为单位),length为区间长度。
[4]由于存在操作系统缓存,Awk脚本程序向Hadoop框架传递计数器时不能一个一个传递,即数据区间长度大于1。
