8.3 Map Task内部实现
前面提到,Map Task分为4种,分别是Job-setup Task、Job-cleanup Task、Task-cleanup Task和Map Task。其中,Job-setup Task和Job-cleanup Task分别是作业运行时启动的第一个任务和最后一个任务,主要工作分别是进行一些作业初始化和收尾工作,比如创建和删除作业临时输出目录;而Task-cleanup Task则是任务失败或者被杀死后,用于清理已写入临时目录中数据的任务。本节主要讲解第四种任务——普通的Map Task。它需要处理数据,并将计算结果存到本地磁盘上。
8.3.1 Map Task整体流程
Map Task的整体计算流程如图8-6所示,共分为5个阶段,分别是:
❑Read阶段:Map Task通过用户编写的RecordReader,从输入InputSplit中解析出一个个key/value。
❑Map阶段:该阶段主要是将解析出的key/value交给用户编写的map()函数处理,并产生一系列新的key/value。
❑Collect阶段:在用户编写的map()函数中,当数据处理完成后,一般会调用OutputCollector.collect()输出结果。在该函数内部,它会将生成的key/value分片(通过调用Partitioner),并写入一个环形内存缓冲区中。
❑Spill阶段:即“溢写”,当环形缓冲区满后,MapReduce会将数据写到本地磁盘上,生成一个临时文件。需要注意的是,将数据写入本地磁盘之前,先要对数据进行一次本地排序,并在必要时对数据进行合并、压缩等操作。
❑Combine阶段:当所有数据处理完成后,Map Task对所有临时文件进行一次合并,以确保最终只会生成一个数据文件。
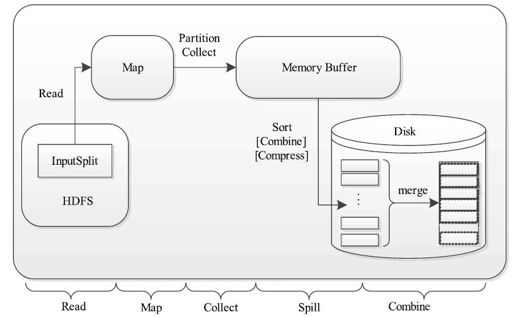
图 8-6 Map Task计算流程
MapReduce框架提供了两套API,默认情况下采用旧API,用户可通过设置参数mapred.mapper.new-api为true启用新API。新API在封装性和扩展性等方面优于旧API,但性能上并没有改进。本章主要以旧API为例进行讲解。
在Map Task中,最重要的部分是输出结果在内存和磁盘中的组织方式,具体涉及Collect、Spill和Combine三个阶段,也就是用户调用OutputCollector.collect()函数之后依次经历的几个阶段。我们将在下面几小节深入分析这几个阶段。
