8.2 基本数据结构和算法
在Map Task和Reduce Task实现过程中用到了大量数据结构和算法,我们选取了其中几个非常核心的部分进行介绍。
前面提到,用户可通过InputFormat和OuputFormat两个组件自定义作业的输入输出格式,但并不能自定义Map Task的输出格式(也就是Reduce Task的输入格式)。考虑到Map Task的输出文件需要到磁盘上并被Reduce Task远程拷贝,为尽可能减少数据量以避免不必要的磁盘和网络开销,Hadoop内部实现了支持行压缩的数据存储格式——IFile。
按照MapReduce语义,Reduce Task需将拷贝自各个Map Task端的数据按照key进行分组后才能交给reduce()函数处理,为此,Hadoop实现了基于排序的分组算法。但考虑到若完全由Reduce Task进行全局排序会产生性能瓶颈,Hadoop采用了分布式排序策略:先由各个Map Task对输出数据进行一次局部排序,然后由Reduce Task进行一次全局排序。
在任务运行过程中,为了能够让JobTracker获取任务执行进度,各个任务会创建一个进度汇报线程Reporter,只要任务处理一条新数据,该线程将通过RPC告知TaskTracker,并由TaskTracker通过心跳进一步告诉JobTracker。
8.2.1 IFile存储格式
IFile是一种支持行压缩的存储格式。通常而言,Map Task中间输出结果和Reduce Task远程拷贝结果被存放在IFile格式的磁盘文件或者内存文件中。为了尽可能减少Map Task写入磁盘数据量和跨网络传输数据量,IFile支持按行压缩数据记录。当前Hadoop提供了Zlib(默认压缩方式)、BZip2等压缩算法。如果用户想启用数据压缩功能,则需为作业添加以下两个配置选项。
❑mapred. compress.map.output:是否支持中间输出结果压缩,默认为false。
❑mapred. map.output.compression.codec:压缩器(默认是基于Zlib算法的压缩器DefaultCodec)。任何一个压缩器需实现CompressionCodec接口以提供压缩输出流和解压缩输入流。
一旦启用了压缩机制,Hadoop会为每条记录的key和value值进行压缩。
IFile定义的文件格式非常简单,整个文件顺次保存数据记录,每条数据记录格式为:
<key-len, value-len, key, value>
由于Map Task会按照key值对输出数据进行排序,因此IFile通常保存的是有序数据集。
IFile文件读写操作由类IFile实现,该类中包含两个重要内部类:Writer和Reader,分别用于Map Task生成IFile和Reduce Task读取一个IFile(对于内存中的数据读取,则使用InMemoryReader)。此外,为了保证数据一致性,Hadoop分别为Writer和Reader提供了IFileOutputStream和IFileInputStream两个支持CRC32校验的类,具体如图8-2所示。
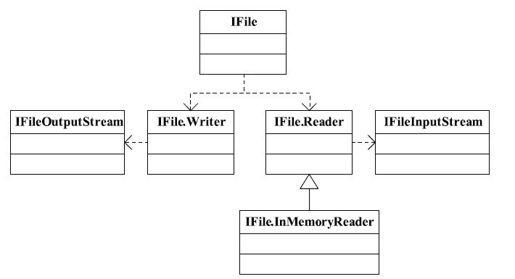
图 8-2 IFile类关系图
