8.3.2 Collect过程分析
待map()函数处理完一对key/value,并产生新的key/value后,会调用OutputCollector.collect()函数输出结果。本小节重点剖析该函数内部实现机制。
跟踪进入Map Task的入口函数run(),可发现,如果用户选用旧API,则会调用runOldMapper函数处理数据。该函数根据实际的配置创建合适的MapRunnable以迭代调用用户编写的map()函数,而map()函数的参数OutputCollector正是MapRunnable传入的OldOutputCollector对象。
OldOutputCollector根据作业是否包含Reduce Task封装了不同的MapOutputCollector实现,如果Reduce Task数目为0,则封装DirectMapOutputCollector对象直接将结果写入HDFS中作为最终结果,否则封装MapOutputBuffer对象暂时将结果写入本地磁盘上以供Reduce Task进一步处理。本小节主要分析Reduce Task数目非0的情况。
用户在map()函数中调用OldOutputCollector.collect(key, value)后,在该函数内部,首先会调用Partitioner.getPartition()函数获取记录的分区号partition,然后将三元组<key, value, partition>传递给MapOutputBuffer.collect()函数做进一步处理。
MapOutputBuffer内部使用了一个缓冲区暂时存储用户输出数据,当缓冲区使用率达到一定阈值后,再将缓冲区中的数据写到磁盘上。数据缓冲区的设计方式直接影响到Map Task的写效率,而现有多种数据结构可供选择,最简单的是单向缓冲区,生产者向缓冲区中单向写入输出,当缓冲区写满后,一次性写到磁盘上,就这样,不断写缓冲区,直到所有数据写到磁盘上。单向缓冲区最大的问题是性能不高,不能支持同时读写数据。双缓冲区是对单向缓冲区的一个改进,它使用两个缓冲区,其中一个用于写入数据,另一个将写满的数据写到磁盘上,这样,两个缓冲区交替读写,进而提高效率。实际上,双缓冲区只能一定程度上让读写并行,仍会存在读写等待问题。一种更好的缓冲区设计方式是采用环形缓冲区:当缓冲区使用率达到一定阈值后,便开始向磁盘上写入数据,同时,生产者仍可以向不断增加的剩余空间中循环写入数据,进而达到真正的读写并行。三种缓冲区结构如图8-7所示。
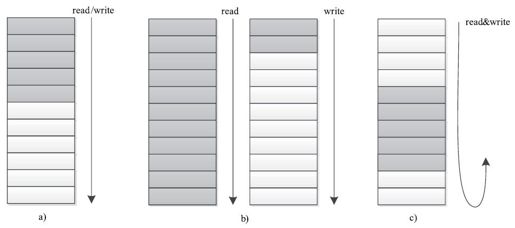
图 8-7 三种缓冲区结构
a)单向缓冲区 b)双缓冲区 c)循环缓冲区
MapOutputBuffer正是采用了环形内存缓冲区保存数据[1],当缓冲区使用率达到一定阈值后,由线程SpillThread将数据写到一个临时文件中,当所有数据处理完毕后,对所有临时文件进行一次合并以生成一个最终文件。环形缓冲区使得Map Task的Collect阶段和Spill阶段可并行进行。
MapOutputBuffer内部采用了两级索引结构(见图8-8),涉及三个环形内存缓冲区,分别是kvoffsets、kvindices和kvbuffer,这三个缓冲区所占内存空间总大小为io.sort.mb(默认是100 MB)。下面分别介绍这三个缓冲区的含义。
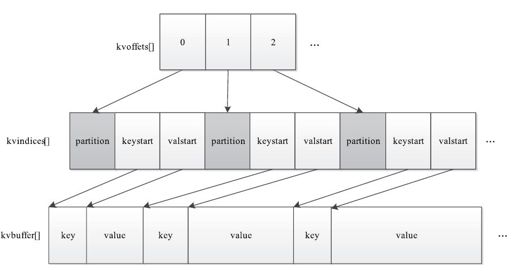
图 8-8 MapOutputBuffer的两级索引结构
(1)kvoffsets
kvoffsets即偏移量索引数组,用于保存key/value信息在位置索引kvindices中的偏移量。考虑到一对key/value需占用数组kvoffsets的1个int(整型)大小,数组kvindices的3个int大小(分别保存所在partition号、key开始位置和value开始位置),所以Hadoop按比例1:3将大小为${io.sort.record.percent}*${io.sort.mb}的内存空间分配给数组kvoffsets和kvindices,其间涉及的缓冲区分配方式见图8-9,计算过程如下:
private static final int ACCTSIZE=3;//每对key/value占用kvindices中的三项
private static final int RECSIZE=(ACCTSIZE+1)*4;//每对key/value共占用
kvoffsets和kvindices中的4个字节(4*4=16 byte)
final float recper=job.getFloat("io.sort.record.percent",(float)0.05);
final int sortmb=job.getInt("io.sort.mb",100);
int maxMemUsage=sortmb<<20;//将内存单位转化为字节
int recordCapacity=(int)(maxMemUsage*recper);
recordCapacity-=recordCapacity%RECSIZE;//保证recordCapacity是4*4的整数倍
recordCapacity/=RECSIZE;//计算内存中最多保存key/value数目
kvoffsets=new int[recordCapacity];//kvoffsets占用1:3中的1
kvindices=new int[recordCapacity*ACCTSIZE];//kvindices占用1:3中的3
当该数组使用率超过io.sort.spill.percent后,便会触发线程SpillThread将数据写入磁盘。
(2)kvindices
kvindices即位置索引数组,用于保存key/value值在数据缓冲区kvbuffer中的起始位置。
(3)kvbuffer
kvbuffer即数据缓冲区,用于保存实际的key/value值,默认情况下最多可使用io.sort.mb中的95%,当该缓冲区使用率超过io.sort.spill.percent后,便会触发线程SpillThread将数据写入磁盘。
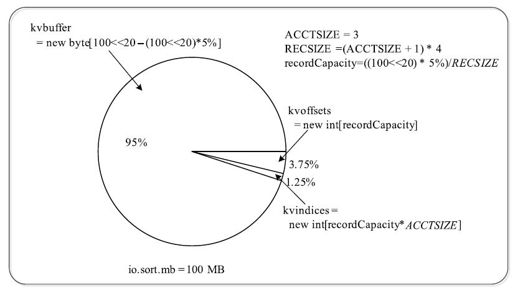
图 8-9 内存io.sort.mb的分配方式
以上几个缓冲区读写采用了典型的单生产者消费者模型,其中,MapOutputBuffer的collect方法和MapOutputBuffer.Buffer的write方法是生产者,spillThread线程是消费者,它们之间同步是通过可重入的互斥锁spillLock和spillLock上的两个条件变量(spillDone和spillReady)完成的。生产者主要的伪代码如下:
//取得下一个可写入的位置
spillLock.lock();
if(缓冲区使用率达到阈值){
//唤醒SpillThread线程,将缓冲区数据写入磁盘
spillReady.signal();
}
if(缓冲区满){
//等待SpillThread线程结束
spillDone.wait();
}
spillLock.lock();
//将数据写入缓冲区
下面分别介绍环形缓冲区kvoffsets和kvbuffer的数据写入过程。
(1)环形缓冲区kvoffsets
通常用一个线性缓冲区模拟实现环形缓冲区,并通过取模操作实现循环数据存储。下面介绍环形缓冲区kvoffsets的写数据过程。该过程由指针kvstart/kvend/kvindex控制,其中kvstart表示存有数据的内存段初始位置,kvindex表示未存储数据的内存段初始位置,而在正常写入情况下,kvend=kvstart,一旦满足溢写条件,则kvend=kvindex,此时指针区间[kvstart, kvend)为有效数据区间。具体涉及的操作如下。
操作1:写入缓冲区。
直接将数据写入kvindex指针指向的内存空间,同时移动kvindex指向下一个可写入的内存空间首地址,kvindex移动公式为:kvindex=(kvindex+1)%kvoffsets.length。由于kvoffsets为环形缓冲区,因此可能涉及两种写入情况。
情况1:kvindex>kvend,如图8-10所示。在这种情况下,指针kvindex在指针kvend后面,如果向缓冲区中写入一个字符串,则kvindex指针后移一位。
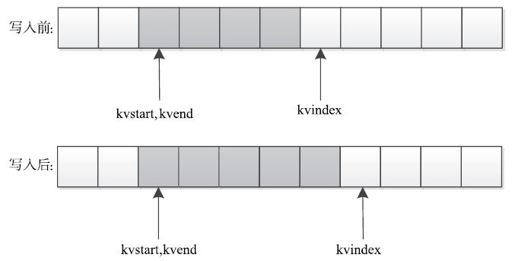
图 8-10 环形缓冲区在kvindex>kvend情况下写入数据
情况2:kvindex<=kvend,如图8-11所示。在这种情况下,指针kvindex位于指针kvend前面,如果向缓冲区中写入一个字符串,则kvindex指针后移一位。

图 8-11 环形缓冲区在kvindex<=kvend情况下写入数据
操作2:溢写到磁盘。
当kvoffsets内存空间使用率超过io.sort.spill.percent(默认是80%)后,需将内存中数据写到磁盘上。为了判断是否满足该条件,需先求出kvoffsets已使用内存。如果kvindex>kvend,则已使用内存大小为kvindex-kvend;否则,已使用内存大小为kvoffsets.length-(kvend-kvindex)。
(2)环形缓冲区kvbuffer
环形缓冲区kvbuffer的读写操作过程由指针bufstart/bufend/bufvoid/bufindex/bufmark控制,其中,bufstart/bufend/bufindex含义与kvstart/kvend/kvindex相同,而bufvoid指向kvbuffer中有效内存结束为止,kvbuffer表示最后写入的一个完整key/value结束位置,具体写入过程中涉及的状态和操作如下:
情况1:初始状态。
初始状态下,bufstart=bufend=bufindex=bufmark=0,bufvoid=kvbuffer.length,如图8-12所示。

图 8-12 初始状态下的kvbuffer
情况2:写入一个key。
写入一个key后,需移动bufindex指针到可写入内存初始位置,如图8-13所示。

图 8-13 向kvbuffer中写入一个key
情况3:写入一个value。
写入key对应的value后,除移动bufindex指针外,还要移动bufmark指针,表示已经写入一个完整的key/value,具体如图8-14所示。

图 8-14 向kvbuffer中写入一个value
情况4:不断写入key/value,直到满足溢写条件,即kvoffsets或者kvbuffer空间使用率超过io.sort.spill.percent(默认值为80%)。此时需要将数据写到磁盘上,如图8-15所示。

图 8-15 kvbuffer使用率达到阈值
情况5:溢写。
如果达到溢写条件,则令bufend←bufindex,并将缓冲区[bufstart, bufend)之间的数据写到磁盘上,具体如图8-16所示。

图 8-16 准备开始溢写
溢写完成之后,恢复正常写入状态,令bufstart←bufend,如图8-17所示。

图 8-17 溢写完成
在溢写的同时,Map Task仍可向kvbuffer中写入数据,如图8-18所示。

图 8-18 溢写的同时,被写入新数据
情况6:写入key时,发生跨界现象。
当写入某个key时,缓冲区尾部剩余空间不足以容纳整个key值,此时需要将key值分开存储,其中一部分存到缓冲区末尾,另外一部分存到缓冲区首部,具体如图8-19所示。

图 8-19 写入key时,发生越界
情况7:调整key位置,防止key跨界现象。
由于key是排序的关键字,通常需交给RawComparator进行排序,而它要求排序关键字必须在内存中连续存储,因此不允许key跨界存储。为解决该问题,Hadoop将跨界的key值重新存储到缓冲区的首位置,通常可分为以下两种情况。
❑bufindex+(bufvoid-bufmark)<bufstart:此时缓冲区前半段有足够的空间容纳整个key值,因此可通过两次内存复制解决跨行问题,具体如图8-20所示。
int headbytelen=bufvoid-bufmark;
System.arraycopy(kvbuffer,0,kvbuffer, headbytelen, bufindex);
System.arraycopy(kvbuffer, bufvoid, kvbuffer,0,headbytelen);

图 8-20 调整位置,避免key跨界
❑bufindex+(bufvoid-bufmark)>=bufstart:此时缓冲区前半段没有足够的空间容纳整个key值,将key值移到缓冲区开始位置时将触发一次Spill操作。这种情况下,可通过三次内存复制解决跨行问题:
byte[]keytmp=new byte[bufindex];//申请一个临时缓冲区
System.arraycopy(kvbuffer,0,keytmp,0,bufindex);
bufindex=0;
out.write(kvbuffer, bufmark, headbytelen);//将key值写入缓冲区开始位置
out.write(keytmp);
情况8:某个key或者value太大,以至于整个缓冲区不能容纳它。
如果一条记录的key或value太大,整个缓冲区都不能容纳它,则Map Task会抛出MapBufferTooSmallException异常,并将该记录单独输出到一个文件中。
(3)环形缓冲区优化
在Hadoop 1.X版本中,当满足以下两个条件之一时,Map Task会发生溢写现象。
条件1:缓冲区kvindices或者kvbuffer的空间使用率达到io.sort.spill.percent(默认值为80%)。
条件2:出现一条kvbuffer无法容纳的超大记录。
前面提到,Map Task将可用的缓冲区空间io.sort.mb按照一定比例(由参数io.sort.record.percent决定)静态分配给了kvoffsets、kvindices和kvbuffer三个缓冲区,而正如条件1所述,只要任何一个缓冲区的使用率达到一定比例,就会发生溢写现象,即使另外的缓冲区使用率非常低。因此,设置合理的io.sort.record.percent参数,对于充分利用缓冲区空间和减少溢写次数,是十分必要的。考虑到每条数据(一个key/value对)需占用索引大小为16 B,因此,建议用户采用以下公式[2]设置io.sort.record.percent:
io.sort.record.percent=16/(16+R)
其中R为平均每条记录的长度。
【实例】假设一个作业的Map Task输入数据量和输出数据量相同,每个Map Task输入数据量大小为128 MB,且共有1 342 177条记录,每条记录大小约为100 B,则需要索引大小为16*1 342 177=20.9 MB。根据这些信息,可设置参数如下:
❑io. sort.mb:128 MB+20.9 MB=148.9 MB
❑io. sort.record.percent:16/(16+100)=0.138
❑io. sort.spill.percent:1.0
这样配置可保证数据只“落”一次地,效率最高!当然,实际使用时可能很难达到这种情况,比如每个Map Task输出数据量非常大,缓冲区难以全部容纳它们,但你至少可以设置合理的io.sort.record.percent以更充分地利用io.sort.mb并尽可能减少中间文件数目。
尽管用户可通过该经验公式设置一个较优的io.sort.record.percent参数,但在实际应用中,估算一个非常合理的R值仍是较麻烦的。为了从根本上解决这个问题,Hadoop 0.21采用共享环形缓冲区对Map Task输出数据的组织方式进行了优化,这样,用户无须再为自己的作业设置io.sort.record.percent参数。如图8-21所示,Hadoop 0.21主要有两个修改点[3]:
❑不再将索引和记录分放到不同的环形缓冲区中,而是让它们共用一个环形缓冲区。
❑引入一个新的指针equator。该指针界定了索引和数据的共同起始存放位置。从该位置开始,索引和数据分别沿相反的方向增长内存使用空间。
通过让索引和记录共享一个环形缓冲区,可舍弃io.sort.record.percent参数,这样,不仅解决了用户设置参数的苦恼,也使得Map Task能够最大限度地利用io.sort.mb空间,进而减少磁盘溢写次数,提高效率。
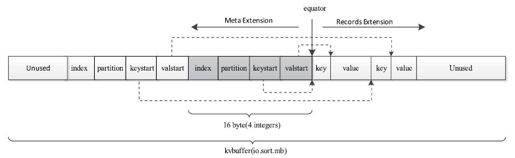
图 8-21 Hadoop 0.21中Map Task的环形缓冲区结构
[1]Hadoop也曾采用过双缓冲区,具体可参考:https://issues.apache.org/jira/browse/HADOOP-1965。
[2]Todd Lipcon, Cloudera,“Optimiziong MapReduce Job Performance”,Hadoop Summit 2012.
[3]https://issues. apache.org/jira/browse/MAPREDUCE-64
