8.2.3 Reporter
前几章提到,所有Task需周期性向TaskTracker汇报最新进度和计数器值,而这正是由Reporter组件实现的。在Map/Reduce Task中,TaskReporter类实现了Reporter接口,并且以线程形式启动。TaskReporter汇报的信息中包含两部分:任务执行进度和任务计数器值。
1.任务执行进度
任务执行进度信息被封装到类Progress中,且每个Progress实例以树的形式存在。Hadoop采用了简单的线性模型计算每个阶段的进度值:如果一个大阶段可被分解成若干个子阶段,则可将大阶段看作一棵树的父节点,而子阶段可看作父节点对应的子节点,且大阶段的进度值可被均摊到各个子阶段中;如果一个阶段不可再分解,则该阶段进度值可表示成已读取数据量占总数据量的比例。
对于Map Task而言,它作为一个大阶段不可再分解,为了简便,我们直接将已读取数据量占总数据量的比例作为任务当前执行进度值。
对于Reduce Task而言,我们可将其分解成三个阶段:Shuffle、Sort和Reduce,每个阶段占任务总进度的1/3。考虑到在Shuffle阶段,Reduce Task需从M(M为Map Task数目)个Map Task上读取一片数据,因此,可被分解成M个阶段,每个阶段占Shuffle进度的1/M,具体如图8-5所示。
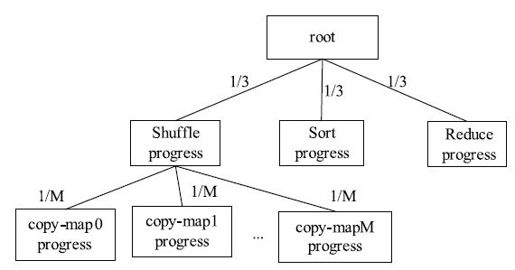
图 8-5 Reduce Task进度树
对于TaskReporter线程而言,它并不会总是每隔一段时间汇报进度和计数器值,而是仅当发现以下两种情况之一时才会汇报。
❑任务执行进度发生变化;
❑任务的某个计数器值发生变化。
在某个时间间隔内,如果任务执行进度和计数器值均未发生变化,则Task只会简单地通过调用RPC函数ping探测TaskTracker是否活着。在一定时间内,如果某个任务的执行进度和计数器值均未发生变化,则TaskTracker认为它处于悬挂(hang up)状态,直接将其杀掉。为了防止某条记录因处理时间过长导致被杀,用户可采用以下两种方法:
❑每隔一段时间调用一次TaskReporter.progress()函数,以告诉TaskTracker自己仍然活着。
❑增大任务超时参数mapred.task.timeout(默认是10 min)对应的值。
2.任务计数器
任务计数器(Counter)是Hadoop提供的,用于实现跟踪任务运行进度的全局计数功能。用户可在自己的应用程序中添加计数器。任务计数器由两部分组成:<name, value>,其中,name表示计数器名称,value表示计数器值(long类型)。计数器通常以组为单位管理,一个计数器属于一个计数器组(CounterGroup)。此外,Hadoop规定一个作业最多包含120个计数器(可通过参数mapreduce.job.counters.limit设定),50个计数器组。
对于同一个任务而言,所有任务包含的计数器相同,每个任务更新自己的计数器值,然后汇报给TaskTracker,并由TaskTracker通过心跳汇报给JobTracker,最后由JobTracker以作业为单位对所有计数器进行累加。作业的计数器分为两类:MapReduce内置计数器和用户自定义计数器。
(1)MapReduce内置计数器
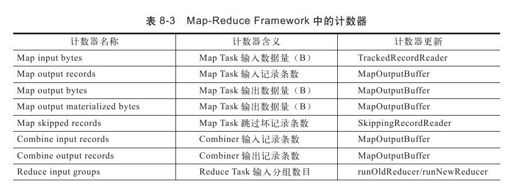
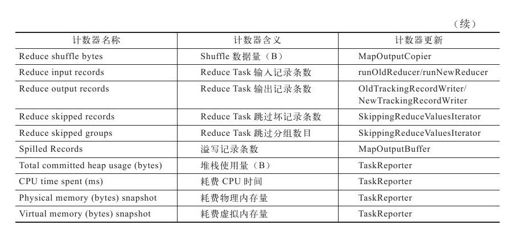
MapReduce框架内部为每个任务添加了三个计数器组,分别位于File Input Format Counters, File Output Format Counters和Map-Reduce Framework中。它们包含的计数器分别见表8-1,表8-2和表8-3。


(2)用户自定义计数器
不同的编程接口,定义计数器的方式不同。接下来,我们简要介绍Java、Hadoop Pipes和Hadoop Streaming中定义计数器的方法。
Java
Hadoop为Java应用程序提供了两种访问和使用计数器的方式:使用枚举类型和字符串类型。如果采用枚举类型,则计数器默认名称是枚举类型的Java完全限定类名,这使得计数器名称的可性读性很差,为此,Hadoop提供了基于资源捆绑修改计数器显示名称的方法:以Java枚举类型为名称创建一个属性文件。在该属性文件中,“CounterGroupName”属性用于设定整个组的显示名称,而枚举类型中每个字段均有一个属性与之对应,属性名称为“字段类型.name”,属性值即为该计数器的显示名称。比如,类Task中定义了大量表示计数器的枚举类型,而这些计数器的显示名称被统一放到同目录下的属性文件Task_Counter.properties中,且内容如下:
CounterGroupName=
Map-Reduce Framework
MAP_INPUT_RECORDS.name=
Map input records
MAP_INPUT_BYTES.name=
Map input bytes
MAP_OUTPUT_RECORDS.name=
Map output records
MAP_OUTPUT_BYTES.name=
Map output bytes
……
如果采用字符串类型,则用户可以直接在计数器API中指定计数器组,计数器名称和计数器值。基于枚举类型和字符串类型的计数器API如下:
public abstract void incrCounter(Enum<?>key, long amount);
public abstract void incrCounter(String group, String counter, long amount);
Hadoop Pipes
Hadoop Pipes提供了一套基于字符串类型的计数器API。通常使用一个计数器需分成三步,分别是定义、注册和使用,举例如下:
HadoopPipes:TaskContext:Counter*mapCounter;//定义
mapCounter=context.getCounter("counterGroup","mapCounter");//注册
context.incrementCounter(mapCounter,1);//使用
Hadoop Streaming
前面提到,Hadoop Streaming基于标准输入输出机制可支持多种语言编写MapReduce程序,而标准输入输出流包含三种:标准输入流、标准输出流和标准错误输出流,其中前两个主要用于输入输出数据,第三种则用于向Java端传递任务运行状态,包括计数器值、任务状态等。如果用户发送计数器值,则可使用标准错误输出流输出以下字符串:
reporter:counter:<group>,<counter>,<amount>
比如,使用C语言可使用以下程序段增加计数器值:
cerr<<"reporter:counter:counterGroup, mapCounter,1"
