2.4.2 Hadoop MapReduce架构
同HDFS一样,Hadoop MapReduce也采用了Master/Slave(M/S)架构,具体如图2-5所示。它主要由以下几个组件组成:Client、JobTracker、TaskTracker和Task。下面分别对这几个组件进行介绍。
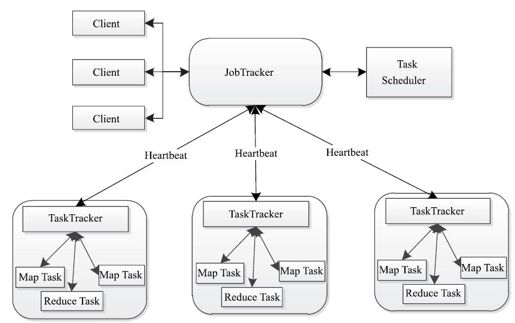
图 2-5 Hadoop MapReduce架构图
(1)Client
用户编写的MapReduce程序通过Client提交到JobTracker端;同时,用户可通过Client提供的一些接口查看作业运行状态。在Hadoop内部用“作业”(Job)表示MapReduce程序。一个MapReduce程序可对应若干个作业,而每个作业会被分解成若干个Map/Reduce任务(Task)。
(2)JobTracker
JobTracker主要负责资源监控和作业调度。JobTracker监控所有TaskTracker与作业的健康状况,一旦发现失败情况后,其会将相应的任务转移到其他节点;同时,JobTracker会跟踪任务的执行进度、资源使用量等信息,并将这些信息告诉任务调度器,而调度器会在资源出现空闲时,选择合适的任务使用这些资源。在Hadoop中,任务调度器是一个可插拔的模块,用户可以根据自己的需要设计相应的调度器。
(3)TaskTracker
TaskTracker会周期性地通过Heartbeat将本节点上资源的使用情况和任务的运行进度汇报给JobTracker,同时接收JobTracker发送过来的命令并执行相应的操作(如启动新任务、杀死任务等)。TaskTracker使用“slot”等量划分本节点上的资源量。“slot”代表计算资源(CPU、内存等)。一个Task获取到一个slot后才有机会运行,而Hadoop调度器的作用就是将各个TaskTracker上的空闲slot分配给Task使用。slot分为Map slot和Reduce slot两种,分别供Map Task和Reduce Task使用。TaskTracker通过slot数目(可配置参数)限定Task的并发度。
(4)Task
Task分为Map Task和Reduce Task两种,均由TaskTracker启动。从上一小节中我们知道,HDFS以固定大小的block为基本单位存储数据,而对于MapReduce而言,其处理单位是split。split与block的对应关系如图2-6所示。split是一个逻辑概念,它只包含一些元数据信息,比如数据起始位置、数据长度、数据所在节点等。它的划分方法完全由用户自己决定。但需要注意的是,split的多少决定了Map Task的数目,因为每个split会交由一个Map Task处理。
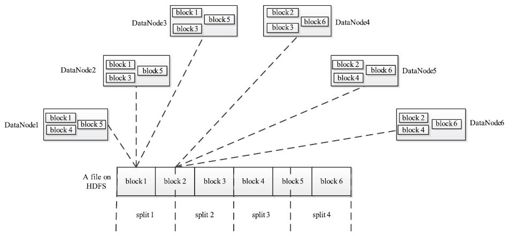
图 2-6 split与block的对应关系
Map Task执行过程如图2-7所示。由该图可知,Map Task先将对应的split迭代解析成一个个key/value对,依次调用用户自定义的map()函数进行处理,最终将临时结果存放到本地磁盘上,其中临时数据被分成若干个partition,每个partition将被一个Reduce Task处理。
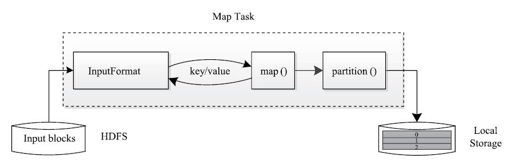
图 2-7 Map Task执行流程
Reduce Task执行过程如图2-8所示。该过程分为三个阶段①从远程节点上读取Map Task中间结果(称为“Shuffle阶段”);②按照key对key/value对进行排序(称为“Sort阶段”);③依次读取<key, value list>,调用用户自定义的reduce()函数处理,并将最终结果存到HDFS上(称为“Reduce阶段”)。
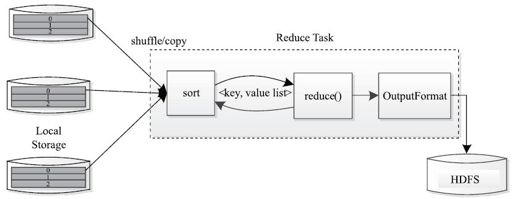
图 2-8 Reduce Task执行过程
