3.3.2 InputFormat接口的设计与实现
InputFormat主要用于描述输入数据的格式,它提供以下两个功能。
❑数据切分:按照某个策略将输入数据切分成若干个split,以便确定Map Task个数以及对应的split。
❑为Mapper提供输入数据:给定某个split,能将其解析成一个个key/value对。
本小节将介绍Hadoop如何设计InputFormat接口,以及提供了哪些常用的InputFormat实现。
1.旧版API的InputFormat解析
如图3-8所示,在旧版API中,InputFormat是一个接口,它包含两种方法:
InputSplit[]getSplits(JobConf job, int numSplits)throws IOException;
RecordReader<K, V>getRecordReader(InputSplit split,
JobConf job,
Reporter reporter)throws IOException;
getSplits方法主要完成数据切分的功能,它会尝试着将输入数据切分成numSplits个InputSplit。InputSplit有以下两个特点。
❑逻辑分片:它只是在逻辑上对输入数据进行分片,并不会在磁盘上将其切分成分片进行存储。InputSplit只记录了分片的元数据信息,比如起始位置、长度以及所在的节点列表等。
❑可序列化:在Hadoop中,对象序列化主要有两个作用:进程间通信和永久存储。此处,InputSplit支持序列化操作主要是为了进程间通信。作业被提交到JobTracker之前,Client会调用作业InputFormat中的getSplits函数,并将得到的InputSplit序列化到文件中。这样,当作业提交到JobTracker端对作业初始化时,可直接读取该文件,解析出所有InputSplit,并创建对应的Map Task。
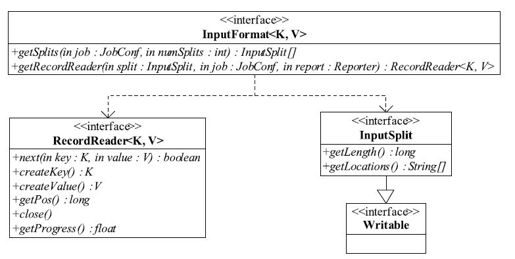
图 3-8 旧API中InputFormat类图
getRecordReader方法返回一个RecordReader对象,该对象可将输入的InputSplit解析成若干个key/value对。MapReduce框架在Map Task执行过程中,会不断调用RecordReader对象中的方法,迭代获取key/value对并交给map()函数处理,主要代码(经过简化)如下:
//调用InputSplit的getRecordReader方法获取RecordReader<K1,V1>input
……
K1 key=input.createKey();
V1 value=input.createValue();
while(input.next(key, value)){
//调用用户编写的map()函数
}
input.close();
前面分析了InputFormat接口的定义,接下来介绍系统自带的各种InputFormat实现。为了方便用户编写MapReduce程序,Hadoop自带了一些针对数据库和文件的InputFormat实现,具体如图3-9所示。通常而言,用户需要处理的数据均以文件形式存储到HDFS上,所以我们重点针对文件的InputFormat实现进行讨论。

图 3-9 Hadoop MapReduce自带InputFormat实现的类层次图
如图3-9所示,所有基于文件的InputFormat实现的基类是FileInputFormat,并由此派生出针对文本文件格式的TextInputFormat、KeyValueTextInputFormat和NLineInputFormat,针对二进制文件格式的SequenceFileInputFormat等。整个基于文件的InputFormat体系的设计思路是,由公共基类FileInputFormat采用统一的方法对各种输入文件进行切分,比如按照某个固定大小等分,而由各个派生InputFormat自己提供机制将进一步解析InputSplit。对应到具体的实现是,基类FileInputFormat提供getSplits实现,而派生类提供getRecordReader实现。
为了帮助读者深入理解这些InputFormat的实现原理,我们选取TextInputFormat与SequenceFileInputFormat进行重点介绍。
我们首先介绍基类FileInputFormat的实现。它最重要的功能是为各种InputFormat提供统一的getSplits函数。该函数实现中最核心的两个算法是文件切分算法和host选择算法。(1)文件切分算法文件切分算法主要用于确定InputSplit的个数以及每个InputSplit对应的数据段。FileInputFormat以文件为单位切分生成InputSplit。对于每个文件,由以下三个属性值确定其对应的InputSplit的个数。
❑goalSize:它是根据用户期望的InputSplit数目计算出来的,即totalSize/numSplits。其中,totalSize为文件总大小;numSplits为用户设定的Map Task个数,默认情况下是1。
❑minSize:InputSplit的最小值,由配置参数mapred.min.split.size确定,默认是1。
❑blockSize:文件在HDFS中存储的block大小,不同文件可能不同,默认是64 MB。这三个参数共同决定InputSplit的最终大小,计算方法如下:
splitSize=max{minSize, min{goalSize, blockSize}}
一旦确定splitSize值后,FileInputFormat将文件依次切成大小为splitSize的InputSplit,最后剩下不足splitSize的数据块单独成为一个InputSplit。
【实例】输入目录下有三个文件file1、file2和file3,大小依次为1 MB,32 MB和250 MB。若blockSize采用默认值64 MB,则不同minSize和goalSize下,file3切分结果如表3-1所示(三种情况下,file1与file2切分结果相同,均为1个InputSplit)。
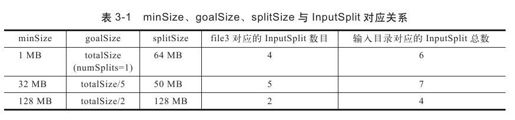
结合表和公式可以知道,如果想让InputSplit尺寸大于block尺寸,则直接增大配置参数mapred.min.split.size即可。
(2)host选择算法
待InputSplit切分方案确定后,下一步要确定每个InputSplit的元数据信息。这通常由四部分组成:<file, start, length, hosts>,分别表示InputSplit所在的文件、起始位置、长度以及所在的host(节点)列表。其中,前三项很容易确定,难点在于host列表的选择方法。
InputSplit的host列表选择策略直接影响到运行过程中的任务本地性。第2章介绍Hadoop架构时,我们提到HDFS上的文件是以block为单位组织的,一个大文件对应的block可能遍布整个Hadoop集群,而InputSplit的划分算法可能导致一个InputSplit对应多个block,这些block可能位于不同节点上,这使得Hadoop不可能实现完全的数据本地性。为此,Hadoop将数据本地性按照代价划分成三个等级:node locality、rack locality和data center locality(Hadoop还未实现该locality级别)。在进行任务调度时,会依次考虑这3个节点的locality,即优先让空闲资源处理本节点上的数据,如果节点上没有可处理的数据,则处理同一个机架上的数据,最差情况是处理其他机架上的数据(但是必须位于同一个数据中心)。
虽然InputSplit对应的block可能位于多个节点上,但考虑到任务调度的效率,通常不会把所有节点加到InputSplit的host列表中,而是选择包含(该InputSplit)数据总量最大的前几个节点(Hadoop限制最多选择10个,多余的会过滤掉),以作为任务调度时判断任务是否具有本地性的主要凭证。为此,FileInputFormat设计了一个简单有效的启发式算法:首先按照rack包含的数据量对rack进行排序,然后在rack内部按照每个node包含的数据量对node排序,最后取前N个node的host作为InputSplit的host列表,这里的N为block副本数。这样,当任务调度器调度Task时,只要将Task调度给位于host列表的节点,就认为该Task满足本地性。
【实例】某个Hadoop集群的网络拓扑结构如图3-10所示,HDFS中block副本数为3,某个InputSplit包含3个block,大小依次是100、150和75,很容易计算,4个rack包含的(该InputSplit的)数据量分别是175、250、150和75。rack2中的node3和node4,rack1中的node1将被添加到该InputSplit的host列表中。
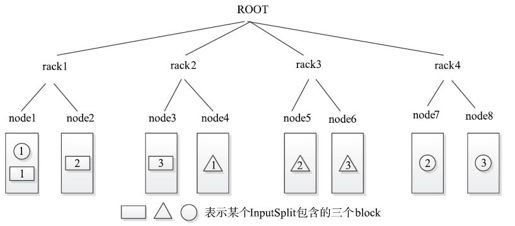
图 3-10 一个Hadoop集群的网络拓扑结构图
从以上host选择算法可知,当InputSplit尺寸大于block尺寸时,Map Task并不能实现完全数据本地性,也就是说,总有一部分数据需要从远程节点上读取,因而可以得出以下结论:
当使用基于FileInputFormat实现InputFormat时,为了提高Map Task的数据本地性,应尽量使InputSplit大小与block大小相同。
分析完FileInputFormat实现方法,接下来分析派生类TextInputFormat与Sequence-FileInputFormat的实现。
前面提到,由派生类实现getRecordReader函数,该函数返回一个RecordReader对象。它实现了类似于迭代器的功能,将某个InputSplit解析成一个个key/value对。在具体实现时,RecordReader应考虑以下两点。
❑定位记录边界:为了能够识别一条完整的记录,记录之间应该添加一些同步标识。对于TextInputFormat,每两条记录之间存在换行符;对于SequenceFileInputFormat,每隔若干条记录会添加固定长度的同步字符串。通过换行符或者同步字符串,它们很容易定位到一个完整记录的起始位置。另外,由于FileInputFormat仅仅按照数据量多少对文件进行切分,因而InputSplit的第一条记录和最后一条记录可能会被从中间切开。为了解决这种记录跨越InputSplit的读取问题,RecordReader规定每个InputSplit的第一条不完整记录划给前一个InputSplit处理。
❑解析key/value:定位到一条新的记录后,需将该记录分解成key和value两部分。对于TextInputFormat,每一行的内容即为value,而该行在整个文件中的偏移量为key。对于SequenceFileInputFormat,每条记录的格式为:
[record length][key length][key][value]
其中,前两个字段分别是整条记录的长度和key的长度,均为4字节,后两个字段分别是key和value的内容。知道每条记录的格式后,很容易解析出key和value。
2.新版API的InputFormat解析
新版API的InputFormat类图如图3-11所示。新API与旧API比较,在形式上发生了较大变化,但仔细分析,发现仅仅是对之前的一些类进行了封装。正如3.1.2节介绍的那样,通过封装,使接口的易用性和扩展性得以增强。
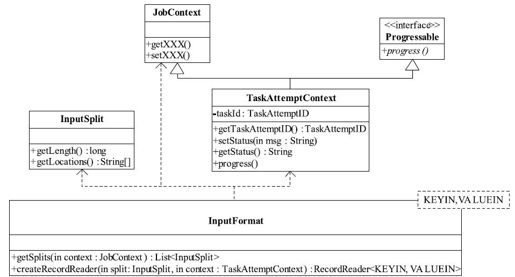
图 3-11 新API中InputFormat类图
此外,对于基类FileInputFormat,新版API中有一个值得注意的改动:InputSplit划分算法不再考虑用户设定的Map Task个数,而用mapred.max.split.size(记为maxSize)代替,即InputSplit大小的计算公式变为:
splitSize=max{minSize, min{maxSize, blockSize}}
