10.2.2 HOD作业调度
理解了Torque工作原理后,HOD调度器工作原理便一目了然:首先利用Torque向物理集群申请一个虚拟机群,然后将Hadoop守护进程包装成一个Torque作业,并在申请的节点上启动,最后用户可直接向启动的Hadoop集群中提交作业。通过HOD调度器申请集群和运行作业的主要流程如下:
步骤1 用户向HOD调度器申请一个包含一定数目节点的集群,并要求该集群中运行一个Hadoop实例。
步骤2 HOD客户端利用资源管理器接口qsub提交一个被称为RingMaster的进程作为Torque作业,同时申请一定数目的节点。这个作业被提交到pbs_server上。
步骤3 在各个计算节点上,守护进程pbs_mom接受并处理pbs_server分配的作业。RingMaster进程在其中一个计算节点上开始运行。
步骤4 RingMaster通过Torque的另外一个接口pbsdsh在所有分配到的计算节点上运行第二个HOD组件HodRing,即运行于各个计算节点上的分布式任务。
步骤5 HodRing初始化之后会与RingMaster通信以获取Hadoop指令,并根据指令启动Hadoop服务进程。一旦服务进程开始启动,它们会向RingMaster登记,提供关于守护进程的信息。
注意 Hadoop实例所需的配置文件全部由HOD自己生成。HOD客户端保持和RingMaster的通信,可以获取MapReduce和HDFS守护进程所在的位置。
步骤6 Hadoop实例启动之后,用户可以向集群中提交MapReduce作业。
步骤7 如果一段时间内Hadoop集群上没有作业运行,Torque会回收该虚拟Hadoop集群的资源。
管理员将一个物理集群划分成若干个Hadoop集群后,用户可将不同类型的应用程序提交到不同Hadoop集群上,这样可避免不同用户或者不同应用程序之间争夺资源,从而达到多用户共享集群的目的。
从集群管理和资源利用率两方面看,这种基于完全隔离的集群划分方法存在诸多问题。
❑从集群管理角度看,多个Hadoop集群会给运维人员造成管理上的诸多不便。
❑多个Hadoop集群会导致集群整体利用率低下,这主要是负载不均衡造成的,比如某个集群非常忙碌时另外一些集群可能空闲,也就是说,多个Hadoop集群无法实现资源共享。
❑考虑到虚拟集群回收后数据可能丢失,用户通常将虚拟集群中的数据写到外部的HDFS上。如图10-2所示,用户通常仅在虚拟集群上安装MapReduce,至于HDFS,则使用一个外部全局共享的HDFS。很明显,这种部署方法会导致丧失部分数据的本地特性。为了解决该问题,一种更好的方法是在整个集群中只保留一个Hadoop实例,而通过Hadoop调度器将整个集群中的资源划分给若干个队列,并让这些队列共享所有节点上的资源,当前Yahoo!的Capacity Scheduler和Facebook的Fair Scheduler正是采用了这个设计思路。
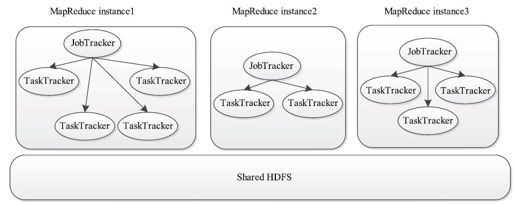
图 10-2 基于外部HDFS的多个虚拟MapReduce集群
