6.6 任务推测执行原理
在分布式集群环境下,因为程序Bug、负载不均衡或者资源分布不均等原因,会造成同一个作业的多个任务之间运行速度不一致。有些任务的运行速度可能明显慢于其他任务(比如一个作业的某个任务进度只有50%,而其他所有任务已经运行完毕),则这些任务会拖慢作业的整体执行进度。为了避免这种情况发生,Hadoop采用了推测执行(Speculative Execution)机制。它根据一定的法则推测出“拖后腿”的任务,并为这样的任务启动一个备份任务,让该任务与原始任务同时处理同一份数据,并最终选用最先成功运行完成任务的计算结果作为最终结果。
在MapReduce应用程序中,用户可分别通过参数mapred.map.tasks.speculative.execution和mapred.reduce.tasks.speculative.execution控制是否对Map Task和Reduce Task启用推测执行功能。默认情况下,这两个参数均为true,表示启用该功能。
6.6.1 计算模型假设
Hadoop在设计之初隐含了一些假设,而正是这些假设影响了Hadoop最初的推测执行设计算法。总结起来,共有以下5个假设:
❑每个节点的计算能力是一样的。
❑任务的执行进度随时间线性增加。
❑启动一个备份任务的代价可以忽略不计。
❑一个任务的进度可以表示成已完成工作量占总工作量的比例(位于0~1之间)。对于Map Task而言,可表示成已读数据量占总数据量(任务对应的数据分片大小)的比例;对于Reduce Task而言,可将其分为三个子阶段:Shuffle、Sort和Reduce,每个阶段各占总时间的1/3。在每个阶段内部,其进度的计算方法跟Map Task一样,总结如下:
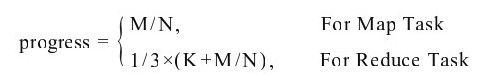
其中,M表示已读取的数据量;N表示总数据量;K=0,1,2,分别对应Shuffle、Sort和Reduce三个阶段。比如,一个Reduce Task位于Reduce阶段,且已读取数据量为120 MB,总数量为200 MB,则进度为1/3×(2+120/200)=86.7%。
❑同一个作业同种类型的任务工作量是一样的,所用总时间相同。
很明显,这些假设完全是基于同构集群和负载均衡的前提下,一旦集群异构或者负载不均衡(比如不同Reduce Task任务之间计算量差距很大),则很多机制将会产生问题。
