5.2 作业提交过程详解
在第3章中,我们介绍了Hadoop提供的三种应用程序开发方法,包括原始Java API、Hadoop Streaming和Hadoop Pipes,考虑到后两种方法的底层实际上均调用了Java API,因此,在本节中,我们以Java MapReduce程序为例讲解作业提交过程。
5.2.1 执行Shell命令
假设用户采用Java语言编写了一个MapReduce程序,并将其打包成xxx.jar,然后通过以下命令提交作业:
$HADOOP_HOME/bin/hadoop jar xxx.jar\
-D mapred.job.name="xxx"\
-D mapred.reduce.tasks=2\
-files=blacklist.txt, whitelist.txt\
-libjars=third-party.jar\
-archives=dictionary.zip\
-input/test/input\
-output/test/output
当用户输入以上命令后,bin/hadoop脚本根据“jar”命令将作业交给RunJar类处理,相关shell代码如下:
……
elif["$COMMAND"="jar"];then
CLASS=org.apache.hadoop.util.RunJar
……
RunJar类中的main函数经解压jar包和设置环境变量后,将运行参数传递给MapReduce程序,并运行之。
用户的MapReduce程序已经配置了作业运行时需要的各种信息(如Mapper类,Reducer类,Reduce Task个数等),它最终在main函数中调用JobClient.runJob函数(新MapReduce API则使用job.waitForCompletion(true)函数)提交作业,这之后会依次经过图5-2所示的函数调用顺序才会将作业提交到JobTracker端。
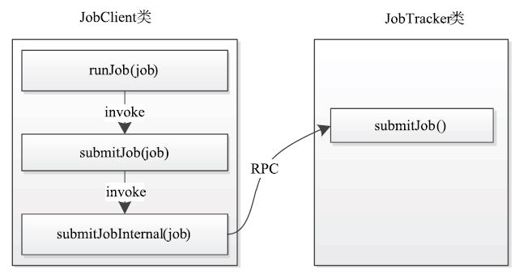
图 5-2 作业提交过程中函数调用关系
