6.7 Hadoop资源管理
Hadoop资源管理由两部分组成:资源表示模型和资源分配模型。其中,资源表示模型用于描述资源的组织方式,Hadoop采用“槽位”(slot)组织各节点上的资源;而资源分配模型则决定如何将资源分配给各个作业/任务,在Hadoop中,这一部分由一个插拔式的调度器完成。
Hadoop引入了“slot”概念表示各个节点上的计算资源。为了简化资源管理,Hadoop将各个节点上的资源(CPU、内存和磁盘等)等量切分成若干份,每一份用一个slot表示,同时规定一个Task可根据实际需要占用多个slot[1]。通过引入“slot”这一概念,Hadoop将多维度资源抽象简化成一种资源(slot),从而大大简化了资源管理问题。
更进一步说,slot相当于任务运行“许可证”。一个任务只有得到该“许可证”后,才能够获得运行的机会,这也意味着,每个节点上的slot数目决定了该节点上的最大允许的任务并发度。为了区分Map Task和Reduce Task所用资源量的差异,slot又被分为Map slot和Reduce slot两种,它们分别只能被Map Task和Reduce Task使用。Hadoop集群管理员可根据各个节点硬件配置和应用特点为它们分配不同的Map slot数(由参数mapred.tasktracker.map.tasks.maximum指定)和Reduce slot数(由参数mapred.tasktracker.reduce.tasks.maximum指定)。
在分布式计算领域中,资源分配问题实际上是一个任务调度问题。它的主要任务是根据当前集群中各个节点上的资源(包括CPU、内存和网络等资源)剩余情况与各个用户作业的服务质量(Quality of Service)要求,在资源和作业/任务之间做出最优的匹配。由于用户对作业服务质量的要求是多样化的,因此,分布式系统中的任务调度是一个多目标优化问题,更进一步说,它是一个典型的NP问题。
在Hadoop中,由于Map Task和Reduce Task运行时使用了不同种类的资源(不同种类的slot),且这两种资源之间不能混用,因此任务调度器分别对Map Task和Reduce Task单独进行调度。而对于同一个作业而言,Reduce Task和Map Task之间存在数据依赖关系,默认情况下,当Map Task完成数目达到总数的5%(可通过参数mapred.reduce.slowstart.completed.maps配置)后,才开始启动Reduce Task(Reduce Task开始被调度)。
一个作业从提交到开始执行的过程如图6-10所示,整个过程大约需7步。
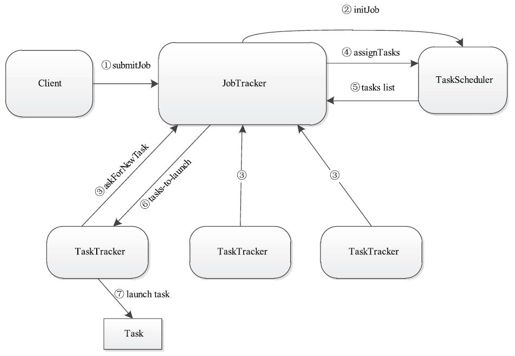
图 6-10 作业从提交到开始执行的过程
步骤1 客户端调用作业提交函数将程序提交到JobTracker端;
步骤2 JobTracker收到新作业后,通知任务调度器(TaskScheduler)对作业进行初始化;
步骤3 某个TaskTracker向JobTracker汇报心跳,其中包含剩余的slot数目和能否接收新任务等信息;
步骤4 如果该TaskTracker能够接收新任务,则JobTracker调用TaskScheduler对外函数assignTasks为该TaskTracker分配新任务;
步骤5 TaskScheduler按照一定的调度策略为该TaskTracker选择最合适的任务列表,并将该列表返回给JobTracker;
步骤6 JobTracker将任务列表以心跳应答的形式返回给对应的TaskTracker;
步骤7 TaskTracker收到心跳应答后,发现有需要启动的新任务,则直接启动该任务。
本小节重点关注Hadoop的资源分配模型,它由一个插拔式的调度器TaskScheduler实现。下一小节主要介绍TaskScheduler的架构与设计思路。
6.7.1 任务调度框架分析
在Hadoop中,任务调度是一个可插拔的模块。用户可以根据自己的实际应用需求设计调度器,然后在配置文件中指定相应的调度器(可通过参数mapred.jobtracker.taskScheduler配置),这样JobTracker启动时便会加载该调度器。
Hadoop提供了一个调度器公共基础类TaskScheduler,用户只需继承该类并根据需要重新实现其中的若干个函数便可以实现自己的调度器。TaskScheduler类的主要定义如下:
abstract class TaskScheduler implements Configurable{
……
protected TaskTrackerManager taskTrackerManager;//实际就是JobTracker
public synchronized void setTaskTrackerManager(
TaskTrackerManager taskTrackerManager){
this.taskTrackerManager=taskTrackerManager;
}
//初始化函数
public void start()throws IOException{
//do nothing
}
//结束函数
public void terminate()throws IOException{
//do nothing
}
//为TaskTracker分配新任务
public abstract List<Task>assignTasks(TaskTracker taskTracker)
throws IOException;
……
}
在Hadoop中,任务调度器和JobTracker之间存在函数相互调用的关系,它们彼此都拥有对方需要的信息或者功能。对于JobTracker而言,它需要调用任务调度器中的assignTasks函数为TaskTracker分配新的任务,同时,JobTracker内部保存了整个集群中的节点、作业和任务的运行时状态信息,这信息是任务调度器进行调度决策时需要用到的。JobTracker与调度器之间的函数调用关系如图6-11所示,需要注意以下几点:
1)任务调度器需要通过一个或者多个JobInProgressListener对象从JobTracker端监听作业状态的变化,包括作业添加、作业更新和作业删除等。
2)任务调度器包括两个主要功能:作业初始化和任务调度。其中,作业初始化发生在JobInProgressListener#jobAdded(JobInProgress)之后,TaskScheduler#assignTasks(TaskTrack er)之前,通过调用函数JobInProgress.initJob(JobInProgress)完成。
3)任务调度器中最重要的对外函数是assignTasks。JobTracker收到能够接收新任务的TaskTracker后,会调用该函数为它分配新任务。它的输入参数是一个TaskTracker对象,输出参数是为该TaskTracker分配的任务列表。
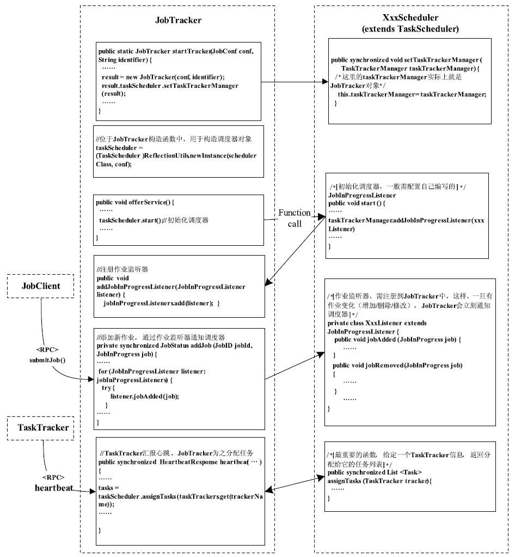
图 6-11 JobTracker与调度器之间的函数调用关系
Hadoop以队列为单位管理作业和资源,每个队列分配有一定量的资源,同时管理员可指定每个队列中资源的使用者以防止资源滥用。添加“队列”这一概念后,现有的Hadoop调度器本质上均采用了三级调度模型。如图6-12所示,当一个TaskTracker出现空闲资源时,调度器会依次选择一个队列、(选中队列中的)作业和(选中作业中的)任务,并最终将这个任务分配给TaskTracker。
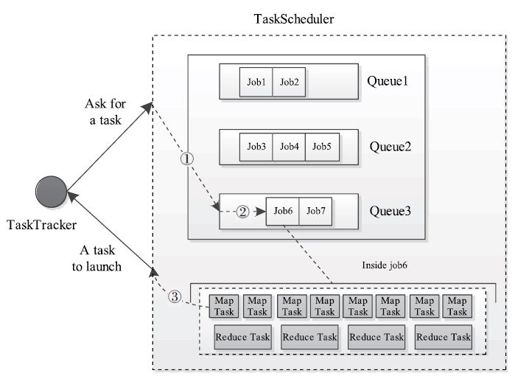
图 6-12 三级调度模型
①选择一个队列②选择一个作业③选择一个任务
在Hadoop中,不同任务调度器的主要区别在于队列选择策略和作业选择策略不同,而任务选择策略通常是相同的,也就是说,给定一个节点,从一个作业中选择一个任务需考虑的因素是一样的,均主要为数据本地性(data-locality)。总之,一个任务调度器通用的assignTasks函数伪代码实现如下:
//为TaskTracker分配任务,并返回任务列表
List<Task>assignTasks(TaskTracker taskTracker):
List<Task>taskList;
while taskTracker.askForTasks()://不断分配新的任务
Queue queue=selectAQueueFromCluster();//从系统中选择一个队列
JobInProgress job=selectAJobFromQueue(queue);//从队列中选择一个作业
Task task=job.obtainNewTask(job);//从作业中选择一个任务
taskList.add(task);
taskTracker.addNewTask(task);
return taskList;
由于不同调度器采用的任务选择策略是一样的,因此Hadoop将之封装成一个通用的模块供各个调度器使用,具体存放在JobInProgress类中的obtainNewMapTask和obtainNewReduceTask方法中。我们将在下一小节分析这两个方法的实现机制。
[1]一个Task可使用多少slot完全由调度器决定。当前大部分调度器只支持一个Task占用一个slot,比如FIFO和Fair Scheduler;而Capacity Scheduler则可根据Task内存需求为其分配多个slot。
