10.2 HOD
HOD(Hadoop On Demand)调度器[1]是一个在共享物理集群上管理若干个Hadoop集群的工具。用户可通过HOD调度器在一个共享物理集群上快速搭建若干个独立的虚拟Hadoop集群,以满足不同的用途,比如不同集群运行不同类型的应用程序,运行不同的Hadoop版本进行测试等。HOD调度器可使管理员和用户轻松地快速搭建和使用Hadoop。
HOD调度器首先使用Torque资源管理器[2]为一个虚拟Hadoop集群分配节点,然后在分配的节点上启动MapReduce和HDFS中的各个守护进程,并自动为Hadoop守护进程和客户端生成合适的配置文件(包括mapred-site.xml, core-site.xml和hdfs-site.xml等)。接下来将分别介绍Torque资源管理器和HOD调度器的基本工作原理。
10.2.1 Torque资源管理器
HOD调度器的工作过程实现中依赖于一个资源管理器来为它分配、回收节点和管理各节点上的作业运行的情况,如监控作业的运行、维护作业的运行状态等。而HOD只需在资源管理器所分配的节点上运行Hadoop守护进程和MapReduce作业即可。当前HOD采用的资源管理器是开源的Torque资源管理器。
一个Torque集群由一个头节点和若干个计算节点组成。头节点上运行一个名为pbs_server的守护进程,主要用于管理计算节点和监控各个作业的运行状态。每个计算节点上运行一个名为pbs_mom的守护进程,用于执行主节点分配的作业。此外,用户可将任何节点作为客户端,用于提交和管理作业。
头节点内部还运行了一个调度器守护进程。该守护进程会与pbs_server进行通信,以决定对资源使用和作业分配的本地策略。默认情况下,调度守护进程采用了FIFO调度机制,它将所有作业存放到一个队列中,并按照到达时间依次对它们进行调度。需要注意的是,Torque中的调度机制是可插拔的,Torque还提供许多其他可选的作业调度器。
如图10-1所示,用户可通过qsub命令向物理集群中提交作业,而Torque内部执行流程如下:
步骤1 当pbs_server收到新作业后,会进一步通知调度器。
步骤2 调度器采用一定的策略为该作业分配节点,并将节点列表与节点对应的作业执行命令返回给pbs_server。
步骤3 pbs_server将作业发送给第一个节点。
步骤4 第一个节点启动作业,作业开始运行(该作业会通知其他节点执行相应命令)。
步骤5 作业运行完成或者资源申请到期后,Torque会回收资源。
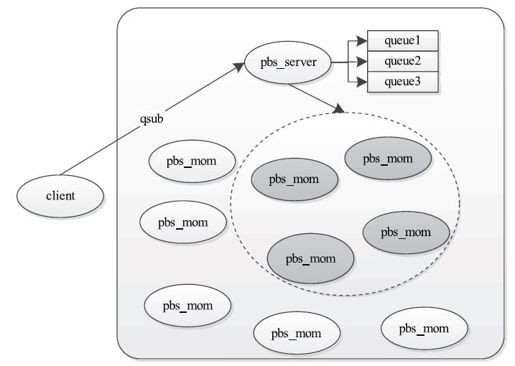
图 10-1 Torque内部工作原理
[1]http://hadoop. apache.org/docs/stable/hod_scheduler.html
[2]http://www. adaptivecomputing.com/products/open-source/torque/
