第6章 JobTracker内部实现剖析
前面提到,Hadoop MapReduce采用了Master/Slave结构。其中,Master便是这一章将要讲解的JobTracker,它是整个集群中唯一的全局“管理者”,涉及的功能包括作业管理、状态监控、任务调度器等。它的设计思路直接决定着Hadoop MapReduce计算框架的容错性和可扩展性的好坏,因此,它是整个系统中最重要的组件,是系统高效运转的关键。
本章将详细介绍JobTracker的实现细节。总的来看,JobTracker主要包含两个功能:资源管理和作业控制。本章将以这两个功能为切入点深入剖析JobTracker的实现细节,包括状态监控、容错机制、推测执行原理和任务调度机制等。
6.1 JobTracker概述
JobTracker是整个MapReduce计算框架中的主服务,相当于集群的“管理者”,负责整个集群的作业控制和资源管理。在Hadoop内部,每个应用程序被表示成一个作业,每个作业又被进一步分成多个任务,而JobTracker的作业控制模块则负责作业的分解和状态监控。其中,最重要的是状态监控,主要包括TaskTracker状态监控、作业状态监控和任务状态监控等。其主要作用有两个:容错和为任务调度提供决策依据。一方面,通过状态监控,JobTracker能够及时发现存在异常或者出现故障的TaskTracker、作业或者任务,从而启动相应的容错机制进行处理;另一方面,由于JobTracker保存了作业和任务的近似实时运行信息,这些可用于任务调度时进行任务选择的依据。资源管理模块的作用是通过一定的策略将各个节点上的计算资源分配给集群中的任务。它由可插拔的任务调度器完成,用户可根据自己的需要编写相应的调度器。
JobTracker的设计原理如图6-1所示。JobTracker是一个后台服务进程,启动之后,会一直监听并接收来自各个TaskTracker发送的心跳信息,这里面包含节点资源使用情况和任务运行情况等信息。JobTracker会将这些信息统一保存起来,并根据需要为TaskTracker分配新任务。
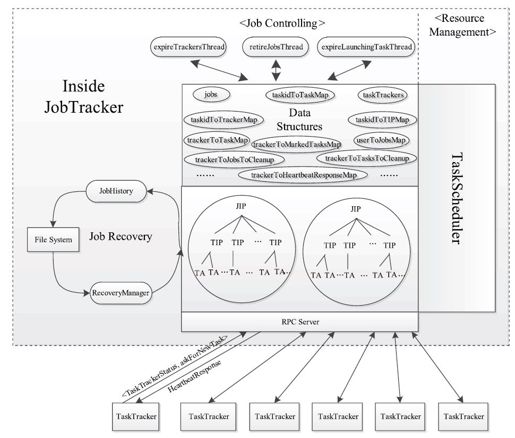
图 6-1 JobTracker内部原理
(1)作业控制
JobTracker在其内部以“三层多叉树”的方式描述和跟踪每个作业的运行状态,作业被抽象成三层,从上往下依次为:作业监控层、任务监控层和任务执行层。在作业监控层中,每个作业由一个JobInProgress(JIP)对象描述和跟踪其整体运行状态以及每个任务的运行情况;在任务监控层中,每个任务由一个TaskInProgress(TIP)对象描述和跟踪其运行状态;在任务执行层中,考虑到任务在执行过程中可能会失败,因而每个任务可能尝试执行多次,直到成功。JobTracker将每次尝试运行一次任务称为“任务运行尝试”,而对应的任务运行实例称为Task Attempt(TA)。当任何一个Task Attempt运行成功后,其上层对应的TaskInProgress会标注该任务运行成功;而当所有的TaskInProgress运行成功后,JobInProgress则会标注整个作业运行成功。
为了方便查找和定位各种对象(比如TaskTracker,作业或者任务等),JobTracker将其相关信息封装成各种对象后,以key/value的形式保存到数据结构Map中。比如,为了能够根据作业ID找到对应的JobInProgress对象,JobTracker将所有运行作业按照JobID与JobInProgress的对应关系保存到Map[1]数据结构jobs中;为了能够查找每个TaskTracker上当前正在运行的Task, JobTracker将trackerID与Task ID集合的映射关系保存到Map数据结构trackerToTaskMap中。JobTracker的各种操作,比如监控、更新等,实际上就是修改这些数据结构中的映射关系。
状态监控的一个重要目的是实现容错功能。借助监控信息,JobTracker实现了全方位的容错机制,包括JobTracker、TaskTracker、Job/Task、Record和磁盘等关键服务和对象的容错。此外,通过监控信息,JobTracker可以推测出“拖后腿”的任务,并通过启动备份任务加快数据处理速度。
在Hadoop MapReduce中,JobTracker存在单点故障问题,当失效或者重启后,如果已保存的任务或者节点状态丢失,则所有正在运行的作业将会失败。为了能够在JobTracker发生故障时尽可能大限度地恢复各个作业,Hadoop在作业运行的各个阶段记录日志,以辅助作业恢复。
(2)资源管理
除了状态监控外,JobTracker的另一个重要功能是资源管理。JobTracker不断接收各个TaskTracker周期性发送过来的资源量和任务状态等信息,并综合考虑TaskTracker(所在DataNode)的数据分布、资源剩余量、作业优先级、作业提交时间等因素,为TaskTracker分配最合适的任务。
[1]在JDK实现中,Map数据结构实际上是红黑树。
