第5章 作业提交与初始化过程分析
前面一章介绍了Hadoop RPC框架,这是MapReduce运行时环境的基础。从本章开始,我们将以“作业的生命周期”为轴线介绍MapReduce内部实现原理。
在本章中,我们将深入分析一个MapReduce作业的提交与初始化过程,即从用户输入提交作业命令到作业初始化的整个过程。该过程涉及JobClient、JobTracker和TaskScheduler三个组件,它们的功能分别是准备运行环境、接收作业以及初始化作业。我们将在本章中深入分析这三个组件。
5.1 作业提交与初始化概述
总体而言,作业提交过程比较简单,它主要为后续作业执行准备环境,主要涉及创建目录、上传文件等操作;而一旦用户提交作业后,JobTracker端便会对作业进行初始化。作业初始化的主要工作是根据输入数据量和作业配置参数将作业分解成若干个Map Task以及Reduce Task,并添加到相关数据结构中,以等待后续被调度执行。总之,可将作业提交与初始化过程分为四个步骤,如图5-1所示。
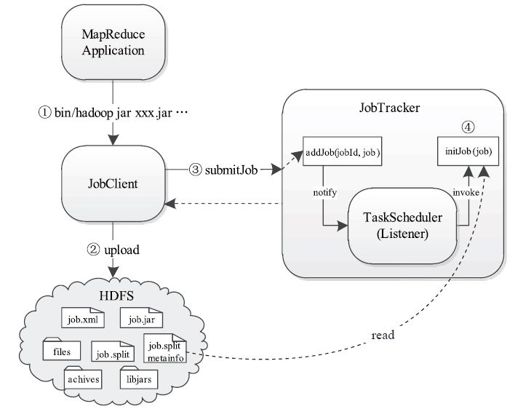
图 5-1 MapReduce作业提交与初始化过程
步骤1 用户使用Hadoop提供的Shell命令提交作业。
步骤2 JobClient按照作业配置信息(JonConf)将作业运行需要的全部文件上传到JobTracker文件系统(通常为HDFS,本书统一采用HDFS)的某个目录下。
步骤3 JobClient调用RPC接口向JobTracker提交作业。
步骤4 JobTracker接收到作业后,将其告知TaskScheduler,由TaskScheduler对作业进行初始化。
在步骤2中,之所以将作业相关文件(包括应用程序jar包、xml文件及其依赖的文件等,后面简称“作业文件”)上传到HDFS上,主要是出于以下两点考虑:
❑HDFS是一个分布式文件系统,Hadoop集群中任何一个节点可以直接从该系统中下载文件。也就是说,HDFS上所有文件都是节点间共享的(不考虑文件权限)。
❑作业文件是运行Task所必需的。它们一旦被上传到HDFS上后,任何一个Task只需知道存放路径便可以下载到自己的工作目录中使用,因而可看作一种非常简便的文件共享方式。
在接下来的几节中,我们将详细分析每个步骤中涉及的技术细节。
