8.6 小结
本章通过将任务进行阶段细分,详细介绍了Map Task和Reduce Task内部实现原理。
本章将Map Task分解成Read、Map、Collect、Spill和Combine五个阶段,并详细介绍了后三个阶段:map()函数处理完结果后,Map Task会将处理结果存放到一个内存缓冲区中(Collect阶段),待缓冲区使用率达到一定阈值后,再将数据溢写到磁盘上(Spill阶段),而当所有数据处理完后,Map Task会将磁盘上所有文件合并成一个大文件(Combine阶段)。这几个阶段形成的流水线如图8-28所示。
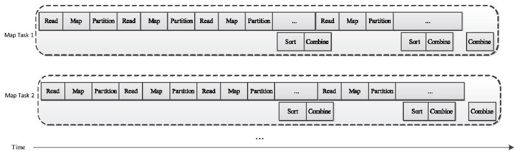
图 8-28 Map Task内部流水线
本章将Reduce Task分解成Shuffle、Merge、Sort、Reduce和Write五个阶段,且重点介绍了前三个阶段:Reduce Task首先进入Shuffle阶段,在该阶段中,它会启动若干个线程,从各个完成的Map Task上拷贝数据,并将数据放到磁盘上或者内存中,待文件数目超过一定阈值后进行一次合并(Merge阶段),当所有数据拷贝完成后,再对所有数据进行一次排序(Sort阶段),并将key相同的记录分组依次交给reduce()函数处理。这几个阶段形成的流水线如图8-29所示。
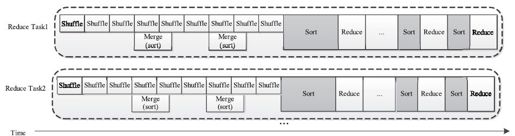
图 8-29 Reduce Task内部流水线
本章最后从参数调优和系统优化两个角度介绍了MapReduce作业优化方法。
