6.5.5 磁盘容错
在MapReduce中,任务需要频繁往磁盘上写数据,比如Map Task需将数据写到本地磁盘,Reduce Task需将数据写到最终的HDFS上。由于磁盘故障率明显高于其他硬件(比如内存、CPU等),因而设计合理的磁盘容错机制对于成功运行一个数据密集型作业尤为重要。
MapReduce中存在多个可配置选项用于设定各种数据输出目录,这些选项大多同时支持配置多个目录,为了提高写效率和负载均衡,用户通常将不同磁盘挂载到这些目录,一个典型的架构如图6-9所示。
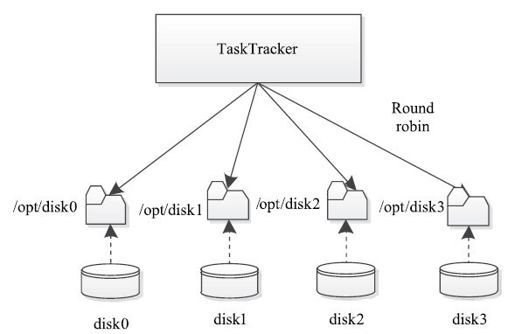
图 6-9 磁盘容错架构
TaskTracker有多种可选策略可将数据均衡地写到这些磁盘,比如轮询选择、随机选择、最多剩余空间磁盘优先等。当前TaskTracker实现中采用了轮询策略,即轮流选择磁盘作为任务的输出目录所在位置。该策略与随机选择和最多剩余空间磁盘优先策略比较,可明显降低产生写热点(大量任务同时往一个磁盘上写数据)的可能性,有利于实现写负载均衡。
(1)TaskTracker采用的机制
TaskTracker允许用户设定以下两个参数以保证节点上有足够的可用磁盘空间,防止任务因磁盘空间不足而运行失败。
❑mapred. local.dir.minspacestart:TaskTracker需要保证的最小可用磁盘空间。只有当可用磁盘空间超过该参数值时,才会接收新任务。
❑mapred. local.dir.minspacekill:TaskTracker会周期性检查所在节点的剩余磁盘空间,一旦低于该阈值,便会按照一定策略杀掉正在运行的任务以释放磁盘空间。
对于MapReduce而言,最重要的目录是用于保存Map Task中间结果的目录,它由参数mapred.local.dirs指定。TaskTracker刚启动时,首先会检查这些目录的健康状况,并将健康目录保存下来以便使用,这之后,它还会周期性(周期由参数mapred.disk.healthChecker.interval指定,默认是60秒)检查各个目录的健康状况,一旦发现某个正常目录出现故障(比如属性变为只读),则会重新对自己进行初始化(该过程与JobTracker向TaskTracker发送ReinitTrackerAction命令后,TaskTracker重启过程一致,涉及清理磁盘空间、初始化各种服务等)。
(2)JobTracker采用的机制
JobTracker上保存了所有任务的运行时信息。它可以通过已经运行完成的任务产生的数据量估算出其他同作业任务需要的磁盘空间,这可以防止因为某个节点磁盘空间不足以容纳某个任务运行结果而造成任务运行失败。
JobTracker采用的数据量估算方法如下。
当一个作业已经运行完成的Map Task数目超过Map Task总数的1/10时,JobTracker开始估算剩余Map Task产生的数据量,它采用了以下简单的线性模型:
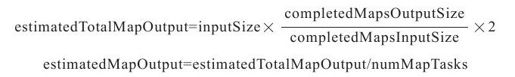
其中,inputSize表示输入数据总量,completedMapsInputSize/completedMapsOutputSize表示所有已经运行完成的Map Task的总输入数据量和总输出数据量,最后乘2表示输出数据量会翻倍(保守估计)。
在此基础上,可估算出Reduce Task的输入数据量:
estimatedReduceInput=estimatedTotalMapOutput/numReduceTasks
如果估算到某个Map/Reduce Task产生的数据量或者输入的数据量超过某个TaskTracker剩余磁盘空间,则不会将该Task分配给它。
