8.2.2 排序
排序是MapReduce框架中最重要的操作之一。Map Task和Reduce Task均会对数据(按照key)进行排序。该操作属于Hadoop的默认行为。任何应用程序中的数据均会被排序,而不管逻辑上是否需要。
对于Map Task,它会将处理的结果暂时放到一个缓冲区中,当缓冲区使用率达到一定阈值后,再对缓冲区中的数据进行一次排序,并将这些有序数据以IFile文件形式写到磁盘上,而当数据处理完毕后,它会对磁盘上所有文件进行一次合并,以将这些文件合并成一个大的有序文件。
对于Reduce Task,它从每个Map Task上远程拷贝相应的数据文件,如果文件大小超过一定阈值,则放到磁盘上,否则放到内存中。如果磁盘上文件数目达到一定阈值,则进行一次合并以生成一个更大文件;如果内存中文件大小或者数目超过一定阈值,则进行一次合并后将数据写到磁盘上。当所有数据拷贝完毕后,Reduce Task统一对内存和磁盘上的所有数据进行一次合并。
在Map Task和Reduce Task运行过程中,缓冲区数据排序使用了Hadoop自己实现快速排序算法,而IFile文件合并则使用了基于堆实现的优先队列。
1.快速排序
快速排序是应用最广泛的排序算法之一。它的基本思想是,选择序列中的一个元素作为枢轴,将小于枢轴的元素放在左边,将大于枢轴的元素放在右边,针对左右两个子序列重复此过程,直到序列为空或者只剩下一个元素。
在《算法导论》[1]一书中,给出了一个教科书式的快速排序实现算法,它的实现方法是:选择序列的最后一个元素作为枢轴,并使用一个索引由前往后遍历整个序列,将小于枢轴的元素交换到左边,大于枢轴的元素交换到右边,直到序列为空或者只剩下一个元素。
Hadoop实现的快速排序在该快速排序之上进行了以下优化。
(1)枢轴选择
枢轴的选择好坏直接影响快速排序的性能,而最坏的情况是划分过程中始终产生两个极端不对称的子序列(有一个长度为1,另一个为n-1),此时排序算法复杂度将增为O(N2)。减小出现划分严重不对称的可能性,Hadoop将序列的首尾和中间元素中的中位数作为枢轴。
(2)子序列划分方法
Hadoop使用了两个索引i和j分别从左右两端进行扫描序列,并让索引i扫描到大于等于枢轴的元素停止,索引j扫描到小于等于枢轴的元素停止,然后交换两个元素,重复这个过程直到两个索引相遇。
(3)对相同元素的优化
在每次划分子序列时,将与枢轴相同的元素集中存放到中间位置,让它们不再参与后续的递归处理,即将序列划分成三部分:小于枢轴、等于枢轴和大于枢轴。
(4)减少递归次数
当子序列中元素数目小于13时,直接使用插入排序算法,不再继续递归。
2.优先队列
文件归并由类Merger完成,它要求待排序对象需是Segment实例化对象。Segment是对磁盘和内存中的IFile格式文件的抽象。它具有类似于迭代器的功能,可迭代读取IFile文件中的key/value。
Merger采用了多轮递归合并的方式,每轮选取最小的前io.sort.factor(默认是10,用户可配置)个文件进行合并,并将产生的文件重新加入待合并列表中,直到剩下的文件数目小于io.sort.factor个,此时,它会返回指向由这些文件组成的小顶堆的迭代器。在图8-3中,我们给出了一个io.sort.factor为3的文件合并实例。
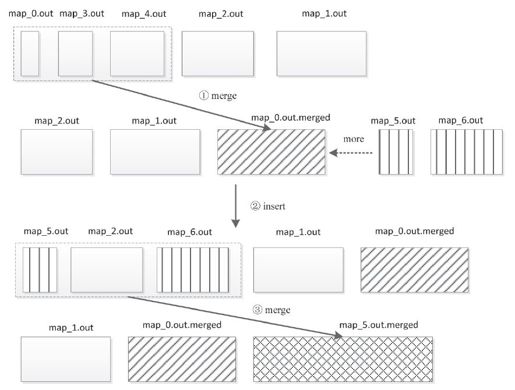
图 8-3 文件合并过程
如图8-4所示,在每一轮合并过程中,Merger采用了小顶堆实现,进而可将文件合并过程看作一个不断建堆的过程:建堆→取堆顶元素→重新建堆→取堆顶元素……
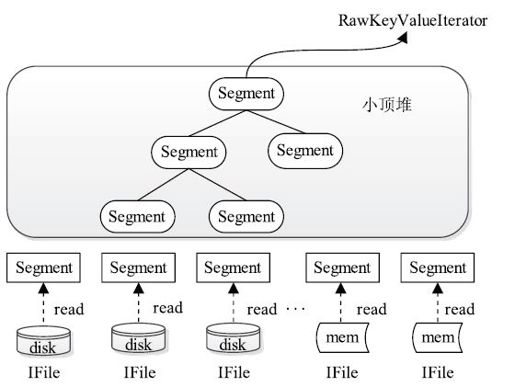
图 8-4 利用小顶堆合并文件
[1]Thomas H. Cormen、Charles E.Leiserson、Ronald L.Rivest、Clifford Stein,“算法导论”,第3版。
