6.7.4 Hadoop资源管理优化
前面提到,Hadoop资源管理由两部分组成:资源表示模型和资源分配模型。考虑到这两部分是耦合在一起的,因此,如果想对Hadoop资源管理进行优化,则需要同时结合这两部分进行考虑。本小节介绍了三种常见的Hadoop资源管理优化方案、分别为基于动态slot的方案、基于无类别slot的方案和基于真实资源需求量的方案。
在正式介绍这几个资源优化方案之前,我们先回顾一下Hadoop 1.0中的资源管理方案。Hadoop 1.0采用了基于slot的资源表示模型。为了简化资源分配问题,Hadoop将各个节点上的多维度资源(CPU、内存、网络I/O和磁盘I/O等)抽象成一维度slot,这样便把复杂的多维度资源分配问题转换成简单的slot分配问题。此外,考虑到Map Task和Reduce Task资源使用量不同,Hadoop又进一步将slot划分成Map slot和Reduce slot两种,并规定Map Task只能使用Map slot, Reduce Task只能使用Reduce slot。具体如图6-15所示。
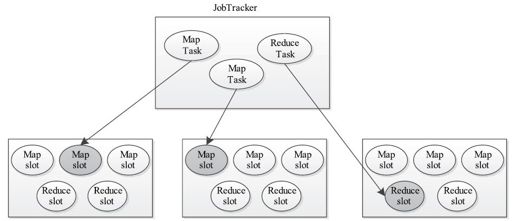
图 6-15 基于slot的资源管理方案
(1)基于动态slot的资源管理方案
Hadoop 1. 0中的资源分配方案采用了静态资源设置策略,即每个节点实现配置好可用的slot总数,这些slot数目一旦启动后无法再动态修改。考虑到实际应用场景中,不同作业对资源的需求往往具有较大差异,静态配置slot数目往往会导致节点上的资源利用率过高或者过低。为了解决该问题,可尝试采用动态调整slot数目的方案[1],具体如图6-16所示。该方案在每个节点上安装一个slot数目动态调整模块SlotsAdjuster,它可以根据节点上的资源利用率动态调整slot数目,以便更合理地利用资源。
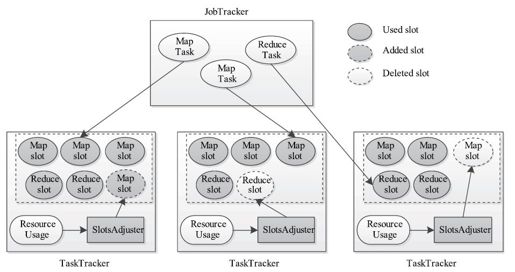
图 6-16 基于动态slot的资源管理方案
(2)基于无类别slot的资源管理方案
对于一个MapReduce应用程序而言,Map Task优先得到调度,而只有当Map Task完成数目达到一定比例(默认是5%)后,Reduce Task才开始获得调度机会。因此,从单个应用程序看,刚开始运行时,Map slot资源紧缺而Reduce slot空闲,当Map Task全部运行完成后,Reduce slot紧缺而Map slot空闲。很明显,这种区分slot类别的资源管理方案在一定程度上降低了slot的利用率。如图6-17所示,一种直观的解决方案是不再区分Map slot和Reduce slot[2],而是只有一种slot,并让Map Task和Reduce Task共享这些slot;至于怎样将这些slot分配给Map Task和Reduce Task,则完全由调度器决定。
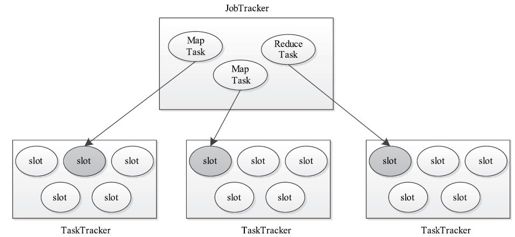
图 6-17 基于无类别slot的资源管理方案
(3)基于真实资源需求量的资源管理方案
让我们进一步分析这种基于无类别slot的资源管理方案可能存在的问题。由于整个Hadoop集群中只有一种slot,因此,这隐含着各个TaskTracker上的slot是同质的,也就是说,一个slot实际上代表了相同的资源。然而,在实际应用环境中,用户应用程序对资源需求往往是多样化的(不同应用程序对资源的要求不同)。这种基于无类别slot的资源划分方法的划分粒度仍过于粗糙,往往会造成节点资源利用率过高或者过低[3]。比如,管理员事先规划好一个slot代表2 GB内存和1个CPU,如果一个应用程序的任务只需要1 GB内存,则会产生“资源碎片”,从而降低集群资源的利用率;同样,如果一个应用程序的任务需要3 GB内存,则会隐式地抢占其他任务的资源,从而产生资源抢占现象,可能导致集群利用率过高。因此,寻求一种更精细的资源划分方法显得尤为必要。
让我们回归到资源分配的本质,即根据任务资源需求为其分配系统中的各类资源。在实际系统中,资源本身是多维度的,包括CPU、内存、网络I/O和磁盘I/O等,因此。如果想精确控制资源分配,不能再有slot的概念,最直接的方法是让任务直接向调度器申请自己需要的资源(比如某个任务可申请1.5 GB内存和1个CPU),而调度器则按照任务实际需求为其精细地分配对应的资源量,不再简单地将一个Slot分配给它,具体如图6-18所示。
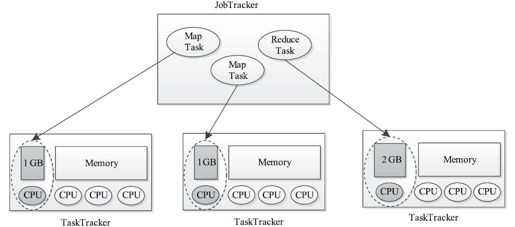
图 6-18 基于真实资源需求量的资源管理方案
Hadoop 2.0中便采用了这种完全基于真实资源需求量的资源管理方案,比如Apache YARN、Facebook Corona等(将在第12章详细介绍)。相比于基于slot的方案,这种方案更加直观,且能够大大提高资源利用率。
[1]梁李印,《阿里Hadoop集群架构及服务体系》,PPT, Hadoop与大数据技术大会(HBTC 2012)。
[2]Hong Mao, Shengqiu Hu, Zhenzhong Zhang, Limin Xiao, Li Ruan:A Load-Driven Task Scheduler with Adaptive DSC for MapReduce. GreenCom 2011:28-33.
[3]A. Ghodsi, M.Zaharia, B.Hindman, A.Konwinski, S.Shenker, and I.Stoica.Dominant Resource Fairness:Fair Allocation of Multiple Resource Types.In USENIX NSDI,2011.
