第7章 TaskTracker内部实现剖析
在Hadoop中,MapReduce采用了master/slave架构。这在第6章已提到了,并对与master对应的JobTracker进行了详细介绍。在本章中,我们将剖析slave的实现——TaskTracker。与JobTracker一样,TaskTracker也是以服务组件的形式存在的。它分布在各个slave节点上,负责任务的执行和任务状态的汇报。
本章将从TaskTracker架构、TaskTracker行为(如启动新任务,杀死任务等)、作业目录管理和任务启动等几个方面深入分析TaskTracker工作原理及其实现。
7.1 TaskTracker概述
TaskTracker是Hadoop集群中运行于各个节点上的服务。它扮演着“通信枢纽”的角色,是JobTracker与Task之间的“沟通桥梁”:一方面,它从JobTracker端接收并执行各种命令,比如运行任务、提交任务、杀死任务等;另一方面,它将本节点上的各个任务状态通过周期性心跳汇报给JobTracker,具体如图7-1所示。
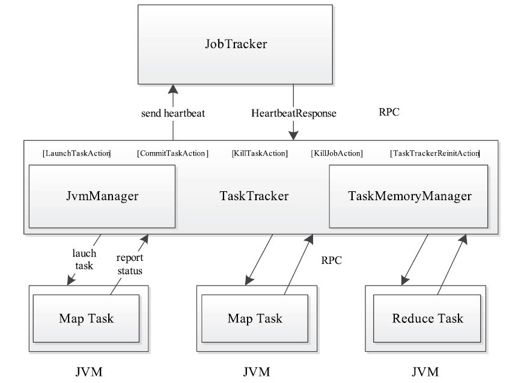
图 7-1 TaskTracker工作原理图
TaskTracker与JobTracker和Task之间采用了RPC协议进行通信。对于TaskTracker和JobTracker而言,它们之间采用InterTrackerProtocol协议,其中,JobTracker扮演RPC Server的角色,而TaskTracker扮演RPC Client的角色;对于TaskTracker与Task而言,它们之间采用TaskUmbilicalProtocol协议,其中,TaskTracker扮演RPC Server的角色,而Task扮演RPC Client的角色。这两个协议的具体内容已在第4章进行了详细介绍,本章不再重复介绍。
总体来说,TaskTracker实现了两个功能:汇报心跳和执行命令。具体如下:
(1)汇报心跳
TaskTracker周期性地将所在节点[1]上各种信息通过心跳机制汇报给JobTracker。这些信息包括两部分:机器级别信息,如节点健康状况、资源使用情况等;任务级别信息,如任务执行进度、任务运行状态、任务Counter值等。
(2)执行命令
JobTracker收到TaskTracker心跳信息后,会根据心跳信息和当前作业运行情况为该TaskTracker下达命令,主要包括启动任务(LaunchTaskAction)、提交任务(CommitTaskAction)、杀死任务(KillTaskAction)、杀死作业(KillJobAction)和重新初始化(TaskTrackerReinitAction)5种命令。其中,过程比较复杂的是启动任务。为了防止任务之间的干扰,TaskTracker为每个任务创建一个单独的Java虚拟机(Java Virtual Machine, JVM),并有专门的线程监控其资源使用情况,一旦发现超量使用资源就直接将其杀掉。
[1]Hadoop允许一个节点上部署多个TaskTracker,并通过端口号区别它们,但通常情况下只部署一个。
